|
|
||
|---|---|---|
| .. | ||
| src | ||
| kahadb-vs-leveldb.png | ||
| pom.xml | ||
| readme.md | ||
{kind=link}
readme.md
The LevelDB Store
Overview
The LevelDB Store is message store implementation that can be used in ActiveMQ messaging servers.
LevelDB vs KahaDB
How is the LevelDB Store better than the default KahaDB store:
- It maitains fewer index entries per message than KahaDB which means it has a higher persistent throughput.
- Faster recovery when a broker restarts
- Since the broker tends to write and read queue entries sequentially, the LevelDB based index provide a much better performance than the B-Tree based indexes of KahaDB which increases throughput.
- Unlike the KahaDB indexes, the LevelDB indexes support concurrent read access which further improves read throughput.
- Pauseless data log file garbage collection cycles.
- It uses fewer read IO operations to load stored messages.
- If a message is copied to multiple queues (Typically happens if your using virtual topics with multiple consumers), then LevelDB will only journal the payload of the message once. KahaDB will journal it multiple times.
- It exposes it's status via JMX for monitoring
- Supports replication to get High Availability
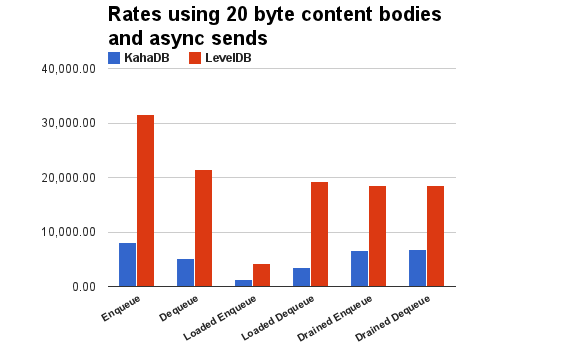
See the following chart to get an idea on how much better you can expect the LevelDB store to perform vs the KahaDB store:
How to Use with ActiveMQ
Update the broker configuration file and change persistenceAdapter elements
settings so that it uses the LevelDB store using the following spring XML
configuration example:
<persistenceAdapter>
<levelDB directory="${activemq.base}/data/leveldb" logSize="107374182"/>
</persistenceAdapter>
Configuration / Property Reference
TODO
JMX Attribute and Operation Reference
TODO
Known Limitations
- The store does not do any dup detection of messages.
Built in High Availability Support
You can also use a High Availability (HA) version of the LevelDB store which works with Hadoop based file systems to achieve HA of your stored messages.
Q: What are the requirements? A: An existing Hadoop 1.0.0 cluster
Q: How does it work during the normal operating cycle? A: It uses HDFS to store a highly available copy of the local leveldb storage files. As local log files are being written to, it also maintains a mirror copy on HDFS. If you have sync enabled on the store, a HDFS file sync is performed instead of a local disk sync. When the index is check pointed, we upload any previously not uploaded leveldb .sst files to HDFS.
Q: What happens when a broker fails and we startup a new slave to take over? A: The slave will download from HDFS the log files and the .sst files associated with the latest uploaded index. Then normal leveldb store recovery kicks in which updates the index using the log files.
Q: How do I use the HA version of the LevelDB store?
A: Update your activemq.xml to use a persistenceAdapter setting similar to the following:
<persistenceAdapter>
<bean xmlns="http://www.springframework.org/schema/beans"
class="org.apache.activemq.leveldb.HALevelDBStore">
<!-- File system URL to replicate to -->
<property name="dfsUrl" value="hdfs://hadoop-name-node"/>
<!-- Directory in the file system to store the data in -->
<property name="dfsDirectory" value="activemq"/>
<property name="directory" value="${activemq.base}/data/leveldb"/>
<property name="logSize" value="107374182"/>
<!-- <property name="sync" value="false"/> -->
</bean>
</persistenceAdapter>
Notice the implementation class name changes to 'HALevelDBStore' Instead of using a 'dfsUrl' property you can instead also just load an existing Hadoop configuration file if it's available on your system, for example:
Q: Who handles starting up the Slave? A: You do. :) This implementation assumes master startup/elections are performed externally and that 2 brokers are never running against the same HDFS file path. In practice this means you need something like ZooKeeper to control starting new brokers to take over failed masters.
Q: Can this run against something other than HDFS? A: It should be able to run with any Hadoop supported file system like CloudStore, S3, MapR, NFS, etc (Well at least in theory, I've only tested against HDFS).
Q: Can 'X' performance be optimized? A: There are bunch of way to improve the performance of many of the things that current version of the store is doing. For example, aggregating the .sst files into an archive to make more efficient use of HDFS, concurrent downloading to improve recovery performance. Lazy downloading of the oldest log files to make recovery faster. Async HDFS writes to avoid blocking local updates. Running brokers in a warm 'standy' mode which keep downloading new log updates and applying index updates from the master as they get uploaded to HDFS to get faster failovers.
Q: Does the broker fail if HDFS fails? A: Currently, yes. But it should be possible to make the master resilient to HDFS failures.