The statistics package provides frameworks and implementations for basic Descriptive statistics, frequency distributions, bivariate regression, and t- and chi-square test statistics.
Descriptive statistics
Frequency distributions
Simple Regression
Statistical Tests
The stat package includes a framework and default implementations for the following Descriptive statistics:
With the exception of percentiles and the median, all of these statistics can be computed without maintaining the full list of input data values in memory. The stat package provides interfaces and implementations that do not require value storage as well as implementations that operate on arrays of stored values.
The top level interface is
org.apache.commons.math.stat.descriptive.UnivariateStatistic.
This interface, implemented by all statistics, consists of
evaluate() methods that take double[] arrays as arguments
and return the value of the statistic. This interface is extended by
StorelessUnivariateStatistic, which adds increment(),
getResult() and associated methods to support
"storageless" implementations that maintain counters, sums or other
state information as values are added using the increment()
method.
Abstract implementations of the top level interfaces are provided in AbstractUnivariateStatistic and AbstractStorelessUnivariateStatistic respectively.
Each statistic is implemented as a separate class, in one of the subpackages (moment, rank, summary) and each extends one of the abstract classes above (depending on whether or not value storage is required to compute the statistic). There are several ways to instantiate and use statistics. Statistics can be instantiated and used directly, but it is generally more convenient (and efficient) to access them using the provided aggregates, DescriptiveStatistics and SummaryStatistics.
DescriptiveStatistics maintains the input data in memory
and has the capability of producing "rolling" statistics computed from a
"window" consisting of the most recently added values.
SummaryStatisics does not store the input data values
in memory, so the statistics included in this aggregate are limited to those
that can be computed in one pass through the data without access to
the full array of values.
| Aggregate | Statistics Included | Values stored? | "Rolling" capability? |
|---|---|---|---|
| DescriptiveStatistics | min, max, mean, geometric mean, n, sum, sum of squares, standard deviation, variance, percentiles, skewness, kurtosis, median | Yes | Yes |
| SummaryStatistics | min, max, mean, geometric mean, n, sum, sum of squares, standard deviation, variance | No | No |
There is also a utility class, StatUtils, that provides static methods for computing statistics directly from double[] arrays.
Here are some examples showing how to compute Descriptive statistics.
DescriptiveStatistics aggregate
(values are stored in memory):
SummaryStatistics aggregate (values are
not stored in memory):
StatUtils utility class:
DescriptiveStatistics instance with
window size set to 100
org.apache.commons.math.stat.descriptive.Frequency provides a simple interface for maintaining counts and percentages of discrete values.
Strings, integers, longs and chars are all supported as value types,
as well as instances of any class that implements Comparable.
The ordering of values used in computing cumulative frequencies is by
default the natural ordering, but this can be overriden by supplying a
Comparator to the constructor. Adding values that are not
comparable to those that have already been added results in an
IllegalArgumentException.
Here are some examples.
org.apache.commons.math.stat.regression.SimpleRegression provides ordinary least squares regression with one independent variable, estimating the linear model:
y = intercept + slope * x
Standard errors for intercept and slope are
available as well as ANOVA, r-square and Pearson's r statistics.
Observations (x,y pairs) can be added to the model one at a time or they can be provided in a 2-dimensional array. The observations are not stored in memory, so there is no limit to the number of observations that can be added to the model.
Usage Notes:
NaN. At least two observations with
different x coordinates are requred to estimate a bivariate regression
model.Implementation Notes:
Here are some examples.
The interfaces and implementations in the
org.apache.commons.math.stat.inference package provide
Student's t and
Chi-Square test statistics as well as
p-values associated with t- and
Chi-Square tests.
Implementation Notes
distributions package. Examples:
t testsobserved values against
mu.
observed values are drawn equals mu.
0 < alpha < 0.5 is the significance level of
the test. The boolean value returned will be true iff the
null hypothesis can be rejected with confidence 1 - alpha.
To test, for example at the 95% level of confidence, use
alpha = 0.05
double[] arrays
sample1 and sample2 is zero.
To compute the t-statistic:
To compute the p-value:
To perform a fixed significance level test with alpha = .05:
true iff the p-value
returned by testStatistic.pairedTTest(sample1, sample2)
is less than .05
StatisticalSummary instances, without assuming that
subpopulation variances are equal.
First create the StatisticalSummary instances. Both
DescriptiveStatistics and SummaryStatistics
implement this interface. Assume that summary1 and
summary2 are SummaryStatistics instances,
each of which has had at least 2 values added to the (virtual) dataset that
it describes. The sample sizes do not have to be the same -- all that is required
is that both samples have at least 2 elements.
Note: The SummaryStatistics class does
not store the dataset that it describes in memory, but it does compute all
statistics necessary to perform t-tests, so this method can be used to
conduct t-tests with very large samples. One-sample tests can also be
performed this way.
(See Descriptive statistics for details
on the SummaryStatistics class.)
To compute the t-statistic:
To compute the p-value:
To perform a fixed significance level test with alpha = .05:
In each case above, the test does not assume that the subpopulation variances are equal. To perform the tests under this assumption, replace "t" at the beginning of the method name with "homoscedasticT"
chi-square test statisticslong[] array of observed counts and a double[]
array of expected counts, use:
sum((expected[i] - observed[i])^2 / expected[i])
observed conforms to expected use:
observed conforms to
expected with alpha siginficance level
(equiv. 100 * (1-alpha)% confidence) where
0 < alpha < 1 use:
true iff the null hypothesis
can be rejected with confidence 1 - alpha.
counts array viewed as a two-way table, use:
count[0], ... , count[count.length - 1]. sum((counts[i][j] - expected[i][j])^2/expected[i][j])
where the sum is taken over all table entries and
expected[i][j] is the product of the row and column sums at
row i, column j divided by the total count.
alpha
siginficance level (equiv. 100 * (1-alpha)% confidence)
where 0 < alpha < 1 use:
true iff the null
hypothesis can be rejected with confidence 1 - alpha.
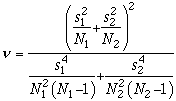{kind=link}