of Hadoop to use. The default is "org.apache.hadoop:hadoop-client:2.3.0".|no|
The Hadoop Index Config submitted as part of an Hadoop Index Task is identical to the Hadoop Index Config used by the `HadoopBatchIndexer` except that three fields must be omitted: `segmentOutputPath`, `workingPath`, `updaterJobSpec`. The Indexing Service takes care of setting these fields internally.
#### Using your own Hadoop distribution
-Druid is compiled against Apache hadoop-core 1.0.3. However, if you happen to use a different flavor of hadoop that is API compatible with hadoop-core 1.0.3, you should only have to change the hadoopCoordinates property to point to the maven artifact used by your distribution.
+Druid is compiled against Apache hadoop-client 2.3.0. However, if you happen to use a different flavor of hadoop that is API compatible with hadoop-client 2.3.0, you should only have to change the hadoopCoordinates property to point to the maven artifact used by your distribution.
#### Resolving dependency conflicts running HadoopIndexTask
diff --git a/docs/content/Tutorial:-A-First-Look-at-Druid.md b/docs/content/Tutorial:-A-First-Look-at-Druid.md
index 468e78c310c..fb4534d43ec 100644
--- a/docs/content/Tutorial:-A-First-Look-at-Druid.md
+++ b/docs/content/Tutorial:-A-First-Look-at-Druid.md
@@ -49,7 +49,7 @@ There are two ways to setup Druid: download a tarball, or [Build From Source](Bu
### Download a Tarball
-We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz). Download this file to a directory of your choosing.
+We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz). Download this file to a directory of your choosing.
You can extract the awesomeness within by issuing:
@@ -60,7 +60,7 @@ tar -zxvf druid-services-*-bin.tar.gz
Not too lost so far right? That's great! If you cd into the directory:
```
-cd druid-services-0.6.81
+cd druid-services-0.6.101
```
You should see a bunch of files:
diff --git a/docs/content/Tutorial:-Loading-Your-Data-Part-1.md b/docs/content/Tutorial:-Loading-Your-Data-Part-1.md
index 122ce70ccc4..45723c03527 100644
--- a/docs/content/Tutorial:-Loading-Your-Data-Part-1.md
+++ b/docs/content/Tutorial:-Loading-Your-Data-Part-1.md
@@ -42,7 +42,7 @@ Metrics (things to aggregate over):
Setting Up
----------
-At this point, you should already have Druid downloaded and are comfortable with running a Druid cluster locally. If you are not, see [here](Tutiroal%3A-The-Druid-Cluster.html).
+At this point, you should already have Druid downloaded and are comfortable with running a Druid cluster locally. If you are not, see [here](Tutorial%3A-The-Druid-Cluster.html).
Let's start from our usual starting point in the tarball directory.
@@ -136,7 +136,7 @@ Indexing the Data
To index the data and build a Druid segment, we are going to need to submit a task to the indexing service. This task should already exist:
```
-examples/indexing/index_task.json
+examples/indexing/wikipedia_index_task.json
```
Open up the file to see the following:
diff --git a/docs/content/Tutorial:-The-Druid-Cluster.md b/docs/content/Tutorial:-The-Druid-Cluster.md
index 215c2d83207..6a1d4ce756b 100644
--- a/docs/content/Tutorial:-The-Druid-Cluster.md
+++ b/docs/content/Tutorial:-The-Druid-Cluster.md
@@ -13,7 +13,7 @@ In this tutorial, we will set up other types of Druid nodes and external depende
If you followed the first tutorial, you should already have Druid downloaded. If not, let's go back and do that first.
-You can download the latest version of druid [here](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz)
+You can download the latest version of druid [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz)
and untar the contents within by issuing:
@@ -149,7 +149,7 @@ druid.port=8081
druid.zk.service.host=localhost
-druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81"]
+druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101"]
# Dummy read only AWS account (used to download example data)
druid.s3.secretKey=QyyfVZ7llSiRg6Qcrql1eEUG7buFpAK6T6engr1b
@@ -240,7 +240,7 @@ druid.port=8083
druid.zk.service.host=localhost
-druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.81","io.druid.extensions:druid-kafka-seven:0.6.81"]
+druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.101","io.druid.extensions:druid-kafka-seven:0.6.101"]
# Change this config to db to hand off to the rest of the Druid cluster
druid.publish.type=noop
diff --git a/docs/content/Tutorial:-Webstream.md b/docs/content/Tutorial:-Webstream.md
index cd2bfb5eb9a..191a52c78c9 100644
--- a/docs/content/Tutorial:-Webstream.md
+++ b/docs/content/Tutorial:-Webstream.md
@@ -37,7 +37,7 @@ There are two ways to setup Druid: download a tarball, or [Build From Source](Bu
h3. Download a Tarball
-We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz)
+We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz)
Download this file to a directory of your choosing.
You can extract the awesomeness within by issuing:
@@ -48,7 +48,7 @@ tar zxvf druid-services-*-bin.tar.gz
Not too lost so far right? That's great! If you cd into the directory:
```
-cd druid-services-0.6.81
+cd druid-services-0.6.101
```
You should see a bunch of files:
diff --git a/docs/content/Twitter-Tutorial.textile b/docs/content/Twitter-Tutorial.md
similarity index 79%
rename from docs/content/Twitter-Tutorial.textile
rename to docs/content/Twitter-Tutorial.md
index 6decc746b17..ccf0e2a4b3c 100644
--- a/docs/content/Twitter-Tutorial.textile
+++ b/docs/content/Twitter-Tutorial.md
@@ -1,77 +1,93 @@
---
layout: doc_page
---
-Greetings! We see you've taken an interest in Druid. That's awesome! Hopefully this tutorial will help clarify some core Druid concepts. We will go through one of the Real-time "Examples":Examples.html, and issue some basic Druid queries. The data source we'll be working with is the "Twitter spritzer stream":https://dev.twitter.com/docs/streaming-apis/streams/public. If you are ready to explore Druid, brave its challenges, and maybe learn a thing or two, read on!
+Greetings! We see you've taken an interest in Druid. That's awesome! Hopefully this tutorial will help clarify some core Druid concepts. We will go through one of the Real-time [Examples](Examples.html), and issue some basic Druid queries. The data source we'll be working with is the [Twitter spritzer stream](https://dev.twitter.com/docs/streaming-apis/streams/public). If you are ready to explore Druid, brave its challenges, and maybe learn a thing or two, read on!
-h2. Setting Up
+# Setting Up
There are two ways to setup Druid: download a tarball, or build it from source.
-h3. Download a Tarball
+# Download a Tarball
-We've built a tarball that contains everything you'll need. You'll find it "here":http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz.
+We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz).
Download this bad boy to a directory of your choosing.
You can extract the awesomeness within by issuing:
-pre. tar -zxvf druid-services-0.X.X.tar.gz
+```
+tar -zxvf druid-services-0.X.X.tar.gz
+```
Not too lost so far right? That's great! If you cd into the directory:
-pre. cd druid-services-0.X.X
+```
+cd druid-services-0.X.X
+```
You should see a bunch of files:
+
* run_example_server.sh
* run_example_client.sh
* LICENSE, config, examples, lib directories
-h3. Clone and Build from Source
+# Clone and Build from Source
The other way to setup Druid is from source via git. To do so, run these commands:
-git clone git@github.com:metamx/druid.git
+```
+git clone git@github.com:metamx/druid.git
cd druid
git checkout druid-0.X.X
./build.sh
-
+```
You should see a bunch of files:
-DruidCorporateCLA.pdf README common examples indexer pom.xml server
+```
+DruidCorporateCLA.pdf README common examples indexer pom.xml server
DruidIndividualCLA.pdf build.sh doc group_by.body install publications services
LICENSE client eclipse_formatting.xml index-common merger realtime
-
+```
You can find the example executables in the examples/bin directory:
+
* run_example_server.sh
* run_example_client.sh
-h2. Running Example Scripts
+# Running Example Scripts
-Let's start doing stuff. You can start a Druid "Realtime":Realtime.html node by issuing:
-./run_example_server.sh
+Let's start doing stuff. You can start a Druid [Realtime](Realtime.html) node by issuing:
+
+```
+./run_example_server.sh
+```
Select "twitter".
-You'll need to register a new application with the twitter API, which only takes a minute. Go to "https://twitter.com/oauth_clients/new":https://twitter.com/oauth_clients/new and fill out the form and submit. Don't worry, the home page and callback url can be anything. This will generate keys for the Twitter example application. Take note of the values for consumer key/secret and access token/secret.
+You'll need to register a new application with the twitter API, which only takes a minute. Go to [this link](https://twitter.com/oauth_clients/new":https://twitter.com/oauth_clients/new) and fill out the form and submit. Don't worry, the home page and callback url can be anything. This will generate keys for the Twitter example application. Take note of the values for consumer key/secret and access token/secret.
Enter your credentials when prompted.
Once the node starts up you will see a bunch of logs about setting up properties and connecting to the data source. If everything was successful, you should see messages of the form shown below. If you see crazy exceptions, you probably typed in your login information incorrectly.
-2013-05-17 23:04:40,934 INFO [main] org.mortbay.log - Started SelectChannelConnector@0.0.0.0:8080
+
+```
+2013-05-17 23:04:40,934 INFO [main] org.mortbay.log - Started SelectChannelConnector@0.0.0.0:8080
2013-05-17 23:04:40,935 INFO [main] com.metamx.common.lifecycle.Lifecycle$AnnotationBasedHandler - Invoking start method[public void com.metamx.druid.http.FileRequestLogger.start()] on object[com.metamx.druid.http.FileRequestLogger@42bb0406].
2013-05-17 23:04:41,578 INFO [Twitter Stream consumer-1[Establishing connection]] twitter4j.TwitterStreamImpl - Connection established.
2013-05-17 23:04:41,578 INFO [Twitter Stream consumer-1[Establishing connection]] io.druid.examples.twitter.TwitterSpritzerFirehoseFactory - Connected_to_Twitter
2013-05-17 23:04:41,578 INFO [Twitter Stream consumer-1[Establishing connection]] twitter4j.TwitterStreamImpl - Receiving status stream.
-
+```
Periodically, you'll also see messages of the form:
-2013-05-17 23:04:59,793 INFO [chief-twitterstream] io.druid.examples.twitter.TwitterSpritzerFirehoseFactory - nextRow() has returned 1,000 InputRows
-
+
+```
+2013-05-17 23:04:59,793 INFO [chief-twitterstream] io.druid.examples.twitter.TwitterSpritzerFirehoseFactory - nextRow() has returned 1,000 InputRows
+```
These messages indicate you are ingesting events. The Druid real time-node ingests events in an in-memory buffer. Periodically, these events will be persisted to disk. Persisting to disk generates a whole bunch of logs:
-2013-05-17 23:06:40,918 INFO [chief-twitterstream] com.metamx.druid.realtime.plumber.RealtimePlumberSchool - Submitting persist runnable for dataSource[twitterstream]
+```
+2013-05-17 23:06:40,918 INFO [chief-twitterstream] com.metamx.druid.realtime.plumber.RealtimePlumberSchool - Submitting persist runnable for dataSource[twitterstream]
2013-05-17 23:06:40,920 INFO [twitterstream-incremental-persist] com.metamx.druid.realtime.plumber.RealtimePlumberSchool - DataSource[twitterstream], Interval[2013-05-17T23:00:00.000Z/2013-05-18T00:00:00.000Z], persisting Hydrant[FireHydrant{index=com.metamx.druid.index.v1.IncrementalIndex@126212dd, queryable=com.metamx.druid.index.IncrementalIndexSegment@64c47498, count=0}]
2013-05-17 23:06:40,937 INFO [twitterstream-incremental-persist] com.metamx.druid.index.v1.IndexMerger - Starting persist for interval[2013-05-17T23:00:00.000Z/2013-05-17T23:07:00.000Z], rows[4,666]
2013-05-17 23:06:41,039 INFO [twitterstream-incremental-persist] com.metamx.druid.index.v1.IndexMerger - outDir[/tmp/example/twitter_realtime/basePersist/twitterstream/2013-05-17T23:00:00.000Z_2013-05-18T00:00:00.000Z/0/v8-tmp] completed index.drd in 11 millis.
@@ -88,16 +104,20 @@ These messages indicate you are ingesting events. The Druid real time-node inges
2013-05-17 23:06:41,425 INFO [twitterstream-incremental-persist] com.metamx.druid.index.v1.IndexIO$DefaultIndexIOHandler - Converting v8[/tmp/example/twitter_realtime/basePersist/twitterstream/2013-05-17T23:00:00.000Z_2013-05-18T00:00:00.000Z/0/v8-tmp] to v9[/tmp/example/twitter_realtime/basePersist/twitterstream/2013-05-17T23:00:00.000Z_2013-05-18T00:00:00.000Z/0]
2013-05-17 23:06:41,426 INFO [twitterstream-incremental-persist]
... ETC
-
+```
The logs are about building different columns, probably not the most exciting stuff (they might as well be in Vulcan) if are you learning about Druid for the first time. Nevertheless, if you are interested in the details of our real-time architecture and why we persist indexes to disk, I suggest you read our "White Paper":http://static.druid.io/docs/druid.pdf.
Okay, things are about to get real (-time). To query the real-time node you've spun up, you can issue:
-./run_example_client.sh
-Select "twitter" once again. This script issues ["GroupByQuery":GroupByQuery.html]s to the twitter data we've been ingesting. The query looks like this:
+```
+./run_example_client.sh
+```
-{
+Select "twitter" once again. This script issues [GroupByQueries](GroupByQuery.html) to the twitter data we've been ingesting. The query looks like this:
+
+```json
+{
"queryType": "groupBy",
"dataSource": "twitterstream",
"granularity": "all",
@@ -109,13 +129,14 @@ Select "twitter" once again. This script issues ["GroupByQuery":GroupByQuery.htm
"filter": { "type": "selector", "dimension": "lang", "value": "en" },
"intervals":["2012-10-01T00:00/2020-01-01T00"]
}
-
+```
This is a **groupBy** query, which you may be familiar with from SQL. We are grouping, or aggregating, via the **dimensions** field: ["lang", "utc_offset"]. We are **filtering** via the **"lang"** dimension, to only look at english tweets. Our **aggregations** are what we are calculating: a row count, and the sum of the tweets in our data.
The result looks something like this:
-[
+```json
+[
{
"version": "v1",
"timestamp": "2012-10-01T00:00:00.000Z",
@@ -137,41 +158,48 @@ The result looks something like this:
}
},
...
-
+```
This data, plotted in a time series/distribution, looks something like this:
-!http://metamarkets.com/wp-content/uploads/2013/06/tweets_timezone_offset.png(Timezone / Tweets Scatter Plot)!
+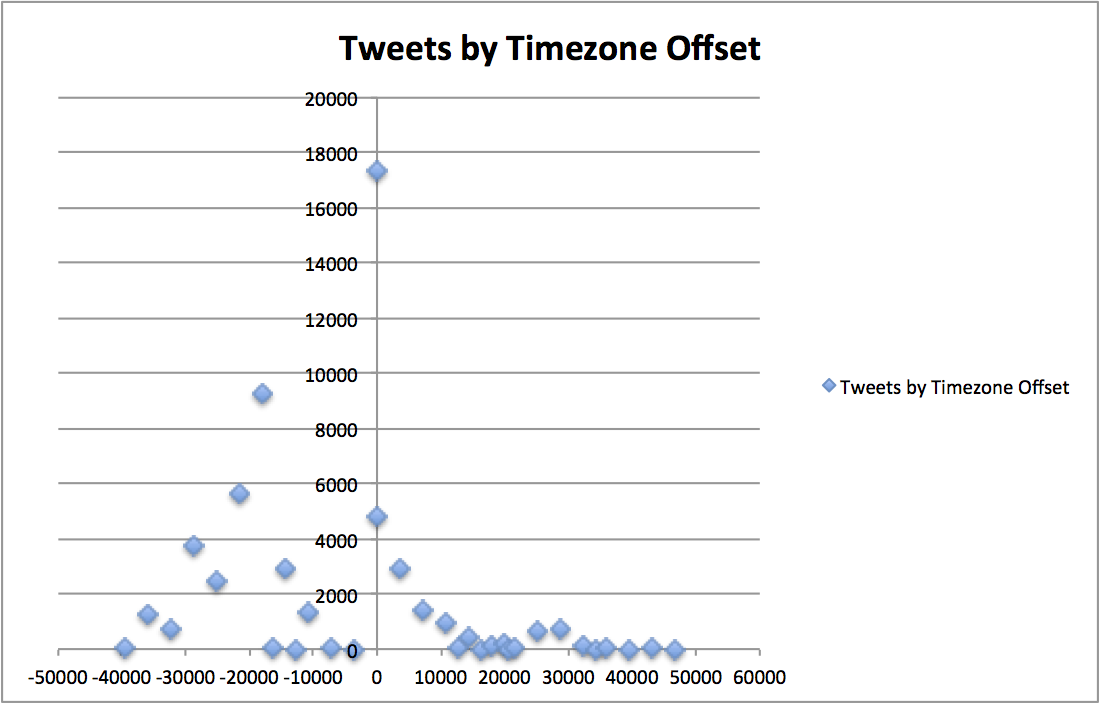
-This groupBy query is a bit complicated and we'll return to it later. For the time being, just make sure you are getting some blocks of data back. If you are having problems, make sure you have "curl":http://curl.haxx.se/ installed. Control+C to break out of the client script.
+This groupBy query is a bit complicated and we'll return to it later. For the time being, just make sure you are getting some blocks of data back. If you are having problems, make sure you have [curl](http://curl.haxx.se/) installed. Control+C to break out of the client script.
-h2. Querying Druid
+# Querying Druid
In your favorite editor, create the file:
-time_boundary_query.body
+
+```
+time_boundary_query.body
+```
Druid queries are JSON blobs which are relatively painless to create programmatically, but an absolute pain to write by hand. So anyway, we are going to create a Druid query by hand. Add the following to the file you just created:
-{
+
+```json
+{
"queryType" : "timeBoundary",
"dataSource" : "twitterstream"
}
-
+```
The "TimeBoundaryQuery":TimeBoundaryQuery.html is one of the simplest Druid queries. To run the query, you can issue:
-
+
+```
curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @time_boundary_query.body
-
+```
We get something like this JSON back:
-[ {
+```json
+{
"timestamp" : "2013-06-10T19:09:00.000Z",
"result" : {
"minTime" : "2013-06-10T19:09:00.000Z",
"maxTime" : "2013-06-10T20:50:00.000Z"
}
} ]
-
+```
That's the result. What information do you think the result is conveying?
...
@@ -179,11 +207,14 @@ If you said the result is indicating the maximum and minimum timestamps we've se
Return to your favorite editor and create the file:
-timeseries_query.body
+```
+timeseries_query.body
+```
-We are going to make a slightly more complicated query, the "TimeseriesQuery":TimeseriesQuery.html. Copy and paste the following into the file:
+We are going to make a slightly more complicated query, the [TimeseriesQuery](TimeseriesQuery.html). Copy and paste the following into the file:
-{
+```json
+{
"queryType":"timeseries",
"dataSource":"twitterstream",
"intervals":["2010-01-01/2020-01-01"],
@@ -193,22 +224,26 @@ We are going to make a slightly more complicated query, the "TimeseriesQuery":Ti
{ "type": "doubleSum", "fieldName": "tweets", "name": "tweets"}
]
}
-
+```
-You are probably wondering, what are these "Granularities":Granularities.html and "Aggregations":Aggregations.html things? What the query is doing is aggregating some metrics over some span of time.
+You are probably wondering, what are these [Granularities](Granularities.html) and [Aggregations](Aggregations.html) things? What the query is doing is aggregating some metrics over some span of time.
To issue the query and get some results, run the following in your command line:
-curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @timeseries_query.body
+
+```
+curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @timeseries_query.body
+```
Once again, you should get a JSON blob of text back with your results, that looks something like this:
-[ {
+```json
+[ {
"timestamp" : "2013-06-10T19:09:00.000Z",
"result" : {
"tweets" : 358562.0,
"rows" : 272271
}
} ]
-
+```
If you issue the query again, you should notice your results updating.
@@ -216,7 +251,8 @@ Right now all the results you are getting back are being aggregated into a singl
If you loudly exclaimed "we can change granularity to minute", you are absolutely correct again! We can specify different granularities to bucket our results, like so:
-{
+```json
+{
"queryType":"timeseries",
"dataSource":"twitterstream",
"intervals":["2010-01-01/2020-01-01"],
@@ -226,11 +262,12 @@ If you loudly exclaimed "we can change granularity to minute", you are absolutel
{ "type": "doubleSum", "fieldName": "tweets", "name": "tweets"}
]
}
-
+```
This gives us something like the following:
-[ {
+```json
+[ {
"timestamp" : "2013-06-10T19:09:00.000Z",
"result" : {
"tweets" : 2650.0,
@@ -250,16 +287,21 @@ This gives us something like the following:
}
},
...
-
+```
-h2. Solving a Problem
+# Solving a Problem
One of Druid's main powers (see what we did there?) is to provide answers to problems, so let's pose a problem. What if we wanted to know what the top hash tags are, ordered by the number tweets, where the language is english, over the last few minutes you've been reading this tutorial? To solve this problem, we have to return to the query we introduced at the very beginning of this tutorial, the "GroupByQuery":GroupByQuery.html. It would be nice if we could group by results by dimension value and somehow sort those results... and it turns out we can!
Let's create the file:
-group_by_query.body
+
+```
+group_by_query.body
+```
and put the following in there:
-{
+
+```json
+{
"queryType": "groupBy",
"dataSource": "twitterstream",
"granularity": "all",
@@ -271,16 +313,20 @@ and put the following in there:
"filter": {"type": "selector", "dimension": "lang", "value": "en" },
"intervals":["2012-10-01T00:00/2020-01-01T00"]
}
-
+```
Woah! Our query just got a way more complicated. Now we have these "Filters":Filters.html things and this "OrderBy":OrderBy.html thing. Fear not, it turns out the new objects we've introduced to our query can help define the format of our results and provide an answer to our question.
If you issue the query:
-curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @group_by_query.body
+
+```
+curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @group_by_query.body
+```
You should hopefully see an answer to our question. For my twitter stream, it looks like this:
-[ {
+```json
+[ {
"version" : "v1",
"timestamp" : "2012-10-01T00:00:00.000Z",
"event" : {
@@ -316,12 +362,12 @@ You should hopefully see an answer to our question. For my twitter stream, it lo
"htags" : "IDidntTextYouBackBecause"
}
} ]
-
+```
Feel free to tweak other query parameters to answer other questions you may have about the data.
-h2. Additional Information
+# Additional Information
-This tutorial is merely showcasing a small fraction of what Druid can do. Next, continue on to "The Druid Cluster":./Tutorial:-The-Druid-Cluster.html.
+This tutorial is merely showcasing a small fraction of what Druid can do. Next, continue on to [The Druid Cluster](./Tutorial:-The-Druid-Cluster.html).
-And thus concludes our journey! Hopefully you learned a thing or two about Druid real-time ingestion, querying Druid, and how Druid can be used to solve problems. If you have additional questions, feel free to post in our "google groups page":http://www.groups.google.com/forum/#!forum/druid-development.
+And thus concludes our journey! Hopefully you learned a thing or two about Druid real-time ingestion, querying Druid, and how Druid can be used to solve problems. If you have additional questions, feel free to post in our [google groups page](http://www.groups.google.com/forum/#!forum/druid-development).
diff --git a/docs/content/toc.textile b/docs/content/toc.textile
index 136aa730335..98395fc2e91 100644
--- a/docs/content/toc.textile
+++ b/docs/content/toc.textile
@@ -22,12 +22,6 @@ h2. Configuration
* "Broker":Broker-Config.html
* "Indexing Service":Indexing-Service-Config.html
-h2. Operations
-* "Extending Druid":./Modules.html
-* "Cluster Setup":./Cluster-setup.html
-* "Booting a Production Cluster":./Booting-a-production-cluster.html
-* "Performance FAQ":./Performance-FAQ.html
-
h2. Data Ingestion
* "Realtime":./Realtime-ingestion.html
* "Batch":./Batch-ingestion.html
@@ -36,6 +30,12 @@ h2. Data Ingestion
* "Data Formats":./Data_formats.html
* "Ingestion FAQ":./Ingestion-FAQ.html
+h2. Operations
+* "Extending Druid":./Modules.html
+* "Cluster Setup":./Cluster-setup.html
+* "Booting a Production Cluster":./Booting-a-production-cluster.html
+* "Performance FAQ":./Performance-FAQ.html
+
h2. Querying
* "Querying":./Querying.html
** "Filters":./Filters.html
@@ -75,6 +75,7 @@ h2. Architecture
h2. Experimental
* "About Experimental Features":./About-Experimental-Features.html
* "Geographic Queries":./GeographicQueries.html
+* "Select Query":./SelectQuery.html
h2. Development
* "Versioning":./Versioning.html
diff --git a/examples/config/historical/runtime.properties b/examples/config/historical/runtime.properties
index 1dffb2cf8ff..c19813610d2 100644
--- a/examples/config/historical/runtime.properties
+++ b/examples/config/historical/runtime.properties
@@ -4,7 +4,7 @@ druid.port=8081
druid.zk.service.host=localhost
-druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81"]
+druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101"]
# Dummy read only AWS account (used to download example data)
druid.s3.secretKey=QyyfVZ7llSiRg6Qcrql1eEUG7buFpAK6T6engr1b
diff --git a/examples/config/realtime/runtime.properties b/examples/config/realtime/runtime.properties
index 94ec5bafd19..c1681adc6ff 100644
--- a/examples/config/realtime/runtime.properties
+++ b/examples/config/realtime/runtime.properties
@@ -4,7 +4,7 @@ druid.port=8083
druid.zk.service.host=localhost
-druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.81","io.druid.extensions:druid-kafka-seven:0.6.81","io.druid.extensions:druid-rabbitmq:0.6.81"]
+druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.101","io.druid.extensions:druid-kafka-seven:0.6.101","io.druid.extensions:druid-rabbitmq:0.6.101"]
# Change this config to db to hand off to the rest of the Druid cluster
druid.publish.type=noop
diff --git a/examples/pom.xml b/examples/pom.xml
index 26b2d2d8b46..48822dce1a9 100644
--- a/examples/pom.xml
+++ b/examples/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
@@ -58,6 +58,11 @@
twitter4j-stream
3.0.3
+
+ commons-validator
+ commons-validator
+ 1.4.0
+
@@ -82,14 +87,14 @@
${project.build.directory}/${project.artifactId}-${project.version}-selfcontained.jar
-
- *:*
-
- META-INF/*.SF
- META-INF/*.DSA
- META-INF/*.RSA
-
-
+
+ *:*
+
+ META-INF/*.SF
+ META-INF/*.DSA
+ META-INF/*.RSA
+
+
diff --git a/examples/src/main/java/io/druid/examples/web/WebJsonSupplier.java b/examples/src/main/java/io/druid/examples/web/WebJsonSupplier.java
index cafb39c3214..9372f721145 100644
--- a/examples/src/main/java/io/druid/examples/web/WebJsonSupplier.java
+++ b/examples/src/main/java/io/druid/examples/web/WebJsonSupplier.java
@@ -19,8 +19,11 @@
package io.druid.examples.web;
+import com.google.api.client.repackaged.com.google.common.base.Throwables;
+import com.google.common.base.Preconditions;
import com.google.common.io.InputSupplier;
import com.metamx.emitter.EmittingLogger;
+import org.apache.commons.validator.routines.UrlValidator;
import java.io.BufferedReader;
import java.io.IOException;
@@ -31,25 +34,25 @@ import java.net.URLConnection;
public class WebJsonSupplier implements InputSupplier
{
private static final EmittingLogger log = new EmittingLogger(WebJsonSupplier.class);
+ private static final UrlValidator urlValidator = new UrlValidator();
- private String urlString;
private URL url;
public WebJsonSupplier(String urlString)
{
- this.urlString = urlString;
+ Preconditions.checkState(urlValidator.isValid(urlString));
+
try {
this.url = new URL(urlString);
}
catch (Exception e) {
- log.error(e,"Malformed url");
+ throw Throwables.propagate(e);
}
}
@Override
public BufferedReader getInput() throws IOException
{
- URL url = new URL(urlString);
URLConnection connection = url.openConnection();
connection.setDoInput(true);
return new BufferedReader(new InputStreamReader(url.openStream()));
diff --git a/examples/src/test/java/io/druid/examples/web/WebJsonSupplierTest.java b/examples/src/test/java/io/druid/examples/web/WebJsonSupplierTest.java
index ca181427c82..436304b7614 100644
--- a/examples/src/test/java/io/druid/examples/web/WebJsonSupplierTest.java
+++ b/examples/src/test/java/io/druid/examples/web/WebJsonSupplierTest.java
@@ -22,15 +22,14 @@ package io.druid.examples.web;
import org.junit.Test;
import java.io.IOException;
+import java.net.MalformedURLException;
public class WebJsonSupplierTest
{
- @Test(expected = IOException.class)
+ @Test(expected = IllegalStateException.class)
public void checkInvalidUrl() throws Exception
{
-
String invalidURL = "http://invalid.url.";
WebJsonSupplier supplier = new WebJsonSupplier(invalidURL);
- supplier.getInput();
}
}
diff --git a/hdfs-storage/pom.xml b/hdfs-storage/pom.xml
index 6e9919a3b1f..a45575c704d 100644
--- a/hdfs-storage/pom.xml
+++ b/hdfs-storage/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
@@ -52,7 +52,7 @@
org.apache.hadoop
- hadoop-core
+ hadoop-client
compile
diff --git a/hll/pom.xml b/hll/pom.xml
index 2e0c36b5ca6..e1e534ff57d 100644
--- a/hll/pom.xml
+++ b/hll/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
diff --git a/indexing-hadoop/pom.xml b/indexing-hadoop/pom.xml
index 19af0cb921c..e3bd0445bd3 100644
--- a/indexing-hadoop/pom.xml
+++ b/indexing-hadoop/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
@@ -67,7 +67,7 @@
org.apache.hadoop
- hadoop-core
+ hadoop-client
com.fasterxml.jackson.core
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/DbUpdaterJob.java b/indexing-hadoop/src/main/java/io/druid/indexer/DbUpdaterJob.java
index 36b67e10c05..a238d5e0254 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/DbUpdaterJob.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/DbUpdaterJob.java
@@ -23,6 +23,7 @@ import com.google.common.collect.ImmutableMap;
import com.metamx.common.logger.Logger;
import io.druid.db.DbConnector;
import io.druid.timeline.DataSegment;
+import io.druid.timeline.partition.NoneShardSpec;
import org.joda.time.DateTime;
import org.skife.jdbi.v2.Handle;
import org.skife.jdbi.v2.IDBI;
@@ -39,13 +40,15 @@ public class DbUpdaterJob implements Jobby
private final HadoopDruidIndexerConfig config;
private final IDBI dbi;
+ private final DbConnector dbConnector;
public DbUpdaterJob(
HadoopDruidIndexerConfig config
)
{
this.config = config;
- this.dbi = new DbConnector(config.getUpdaterJobSpec(), null).getDBI();
+ this.dbConnector = new DbConnector(config.getUpdaterJobSpec(), null);
+ this.dbi = this.dbConnector.getDBI();
}
@Override
@@ -61,8 +64,11 @@ public class DbUpdaterJob implements Jobby
{
final PreparedBatch batch = handle.prepareBatch(
String.format(
- "INSERT INTO %s (id, dataSource, created_date, start, end, partitioned, version, used, payload) "
- + "VALUES (:id, :dataSource, :created_date, :start, :end, :partitioned, :version, :used, :payload)",
+ dbConnector.isPostgreSQL() ?
+ "INSERT INTO %s (id, dataSource, created_date, start, \"end\", partitioned, version, used, payload) "
+ + "VALUES (:id, :dataSource, :created_date, :start, :end, :partitioned, :version, :used, :payload)" :
+ "INSERT INTO %s (id, dataSource, created_date, start, end, partitioned, version, used, payload) "
+ + "VALUES (:id, :dataSource, :created_date, :start, :end, :partitioned, :version, :used, :payload)",
config.getUpdaterJobSpec().getSegmentTable()
)
);
@@ -75,7 +81,7 @@ public class DbUpdaterJob implements Jobby
.put("created_date", new DateTime().toString())
.put("start", segment.getInterval().getStart().toString())
.put("end", segment.getInterval().getEnd().toString())
- .put("partitioned", segment.getShardSpec().getPartitionNum())
+ .put("partitioned", (segment.getShardSpec() instanceof NoneShardSpec) ? 0 : 1)
.put("version", segment.getVersion())
.put("used", true)
.put("payload", HadoopDruidIndexerConfig.jsonMapper.writeValueAsString(segment))
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/DetermineHashedPartitionsJob.java b/indexing-hadoop/src/main/java/io/druid/indexer/DetermineHashedPartitionsJob.java
index ae2d61a9a93..530d155460d 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/DetermineHashedPartitionsJob.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/DetermineHashedPartitionsJob.java
@@ -37,6 +37,7 @@ import io.druid.indexer.granularity.UniformGranularitySpec;
import io.druid.query.aggregation.hyperloglog.HyperLogLogCollector;
import io.druid.timeline.partition.HashBasedNumberedShardSpec;
import io.druid.timeline.partition.NoneShardSpec;
+import org.apache.hadoop.conf.Configurable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
@@ -45,6 +46,7 @@ import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
+import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
@@ -65,7 +67,6 @@ import java.util.Set;
*/
public class DetermineHashedPartitionsJob implements Jobby
{
- private static final int MAX_SHARDS = 128;
private static final Logger log = new Logger(DetermineHashedPartitionsJob.class);
private final HadoopDruidIndexerConfig config;
@@ -98,8 +99,11 @@ public class DetermineHashedPartitionsJob implements Jobby
groupByJob.setOutputKeyClass(NullWritable.class);
groupByJob.setOutputValueClass(NullWritable.class);
groupByJob.setOutputFormatClass(SequenceFileOutputFormat.class);
+ groupByJob.setPartitionerClass(DetermineHashedPartitionsPartitioner.class);
if (!config.getSegmentGranularIntervals().isPresent()) {
groupByJob.setNumReduceTasks(1);
+ } else {
+ groupByJob.setNumReduceTasks(config.getSegmentGranularIntervals().get().size());
}
JobHelper.setupClasspath(config, groupByJob);
@@ -124,9 +128,6 @@ public class DetermineHashedPartitionsJob implements Jobby
if (!config.getSegmentGranularIntervals().isPresent()) {
final Path intervalInfoPath = config.makeIntervalInfoPath();
fileSystem = intervalInfoPath.getFileSystem(groupByJob.getConfiguration());
- if (!fileSystem.exists(intervalInfoPath)) {
- throw new ISE("Path[%s] didn't exist!?", intervalInfoPath);
- }
List intervals = config.jsonMapper.readValue(
Utils.openInputStream(groupByJob, intervalInfoPath), new TypeReference>()
{
@@ -144,37 +145,25 @@ public class DetermineHashedPartitionsJob implements Jobby
if (fileSystem == null) {
fileSystem = partitionInfoPath.getFileSystem(groupByJob.getConfiguration());
}
- if (fileSystem.exists(partitionInfoPath)) {
- Long cardinality = config.jsonMapper.readValue(
- Utils.openInputStream(groupByJob, partitionInfoPath), new TypeReference()
- {
- }
- );
- int numberOfShards = (int) Math.ceil((double) cardinality / config.getTargetPartitionSize());
-
- if (numberOfShards > MAX_SHARDS) {
- throw new ISE(
- "Number of shards [%d] exceed the maximum limit of [%d], either targetPartitionSize is too low or data volume is too high",
- numberOfShards,
- MAX_SHARDS
- );
- }
-
- List actualSpecs = Lists.newArrayListWithExpectedSize(numberOfShards);
- if (numberOfShards == 1) {
- actualSpecs.add(new HadoopyShardSpec(new NoneShardSpec(), shardCount++));
- } else {
- for (int i = 0; i < numberOfShards; ++i) {
- actualSpecs.add(new HadoopyShardSpec(new HashBasedNumberedShardSpec(i, numberOfShards), shardCount++));
- log.info("DateTime[%s], partition[%d], spec[%s]", bucket, i, actualSpecs.get(i));
- }
- }
-
- shardSpecs.put(bucket, actualSpecs);
-
- } else {
- log.info("Path[%s] didn't exist!?", partitionInfoPath);
+ final Long cardinality = config.jsonMapper.readValue(
+ Utils.openInputStream(groupByJob, partitionInfoPath), new TypeReference()
+ {
}
+ );
+ final int numberOfShards = (int) Math.ceil((double) cardinality / config.getTargetPartitionSize());
+
+ List actualSpecs = Lists.newArrayListWithExpectedSize(numberOfShards);
+ if (numberOfShards == 1) {
+ actualSpecs.add(new HadoopyShardSpec(new NoneShardSpec(), shardCount++));
+ } else {
+ for (int i = 0; i < numberOfShards; ++i) {
+ actualSpecs.add(new HadoopyShardSpec(new HashBasedNumberedShardSpec(i, numberOfShards), shardCount++));
+ log.info("DateTime[%s], partition[%d], spec[%s]", bucket, i, actualSpecs.get(i));
+ }
+ }
+
+ shardSpecs.put(bucket, actualSpecs);
+
}
config.setShardSpecs(shardSpecs);
log.info(
@@ -319,13 +308,6 @@ public class DetermineHashedPartitionsJob implements Jobby
}
}
- private byte[] getDataBytes(BytesWritable writable)
- {
- byte[] rv = new byte[writable.getLength()];
- System.arraycopy(writable.getBytes(), 0, rv, 0, writable.getLength());
- return rv;
- }
-
@Override
public void run(Context context)
throws IOException, InterruptedException
@@ -353,6 +335,50 @@ public class DetermineHashedPartitionsJob implements Jobby
}
}
}
+
+ public static class DetermineHashedPartitionsPartitioner
+ extends Partitioner implements Configurable
+ {
+ private Configuration config;
+ private boolean determineIntervals;
+ private Map reducerLookup;
+
+ @Override
+ public int getPartition(LongWritable interval, BytesWritable text, int numPartitions)
+ {
+
+ if (config.get("mapred.job.tracker").equals("local") || determineIntervals) {
+ return 0;
+ } else {
+ return reducerLookup.get(interval);
+ }
+ }
+
+ @Override
+ public Configuration getConf()
+ {
+ return config;
+ }
+
+ @Override
+ public void setConf(Configuration config)
+ {
+ this.config = config;
+ HadoopDruidIndexerConfig hadoopConfig = HadoopDruidIndexerConfigBuilder.fromConfiguration(config);
+ if (hadoopConfig.getSegmentGranularIntervals().isPresent()) {
+ determineIntervals = false;
+ int reducerNumber = 0;
+ ImmutableMap.Builder builder = ImmutableMap.builder();
+ for (Interval interval : hadoopConfig.getSegmentGranularIntervals().get()) {
+ builder.put(new LongWritable(interval.getStartMillis()), reducerNumber++);
+ }
+ reducerLookup = builder.build();
+ } else {
+ determineIntervals = true;
+ }
+ }
+ }
+
}
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/DeterminePartitionsJob.java b/indexing-hadoop/src/main/java/io/druid/indexer/DeterminePartitionsJob.java
index 890a3516189..ddcb691ef09 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/DeterminePartitionsJob.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/DeterminePartitionsJob.java
@@ -215,23 +215,20 @@ public class DeterminePartitionsJob implements Jobby
if (fileSystem == null) {
fileSystem = partitionInfoPath.getFileSystem(dimSelectionJob.getConfiguration());
}
- if (fileSystem.exists(partitionInfoPath)) {
- List specs = config.jsonMapper.readValue(
- Utils.openInputStream(dimSelectionJob, partitionInfoPath), new TypeReference>()
- {
- }
- );
-
- List actualSpecs = Lists.newArrayListWithExpectedSize(specs.size());
- for (int i = 0; i < specs.size(); ++i) {
- actualSpecs.add(new HadoopyShardSpec(specs.get(i), shardCount++));
- log.info("DateTime[%s], partition[%d], spec[%s]", segmentGranularity, i, actualSpecs.get(i));
- }
-
- shardSpecs.put(segmentGranularity.getStart(), actualSpecs);
- } else {
- log.info("Path[%s] didn't exist!?", partitionInfoPath);
+ List specs = config.jsonMapper.readValue(
+ Utils.openInputStream(dimSelectionJob, partitionInfoPath), new TypeReference>()
+ {
}
+ );
+
+ List actualSpecs = Lists.newArrayListWithExpectedSize(specs.size());
+ for (int i = 0; i < specs.size(); ++i) {
+ actualSpecs.add(new HadoopyShardSpec(specs.get(i), shardCount++));
+ log.info("DateTime[%s], partition[%d], spec[%s]", segmentGranularity, i, actualSpecs.get(i));
+ }
+
+ shardSpecs.put(segmentGranularity.getStart(), actualSpecs);
+
}
config.setShardSpecs(shardSpecs);
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/HadoopDruidDetermineConfigurationJob.java b/indexing-hadoop/src/main/java/io/druid/indexer/HadoopDruidDetermineConfigurationJob.java
index 2076292260d..311eec6248e 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/HadoopDruidDetermineConfigurationJob.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/HadoopDruidDetermineConfigurationJob.java
@@ -23,6 +23,7 @@ import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import com.google.inject.Inject;
import com.metamx.common.logger.Logger;
+import io.druid.timeline.partition.HashBasedNumberedShardSpec;
import io.druid.timeline.partition.NoneShardSpec;
import org.joda.time.DateTime;
import org.joda.time.DateTimeComparator;
@@ -56,13 +57,28 @@ public class HadoopDruidDetermineConfigurationJob implements Jobby
if (config.isDeterminingPartitions()) {
jobs.add(config.getPartitionsSpec().getPartitionJob(config));
} else {
+ int shardsPerInterval = config.getPartitionsSpec().getNumShards();
Map> shardSpecs = Maps.newTreeMap(DateTimeComparator.getInstance());
int shardCount = 0;
for (Interval segmentGranularity : config.getSegmentGranularIntervals().get()) {
DateTime bucket = segmentGranularity.getStart();
- final HadoopyShardSpec spec = new HadoopyShardSpec(new NoneShardSpec(), shardCount++);
- shardSpecs.put(bucket, Lists.newArrayList(spec));
- log.info("DateTime[%s], spec[%s]", bucket, spec);
+ if (shardsPerInterval > 0) {
+ List specs = Lists.newArrayListWithCapacity(shardsPerInterval);
+ for (int i = 0; i < shardsPerInterval; i++) {
+ specs.add(
+ new HadoopyShardSpec(
+ new HashBasedNumberedShardSpec(i, shardsPerInterval),
+ shardCount++
+ )
+ );
+ }
+ shardSpecs.put(bucket, specs);
+ log.info("DateTime[%s], spec[%s]", bucket, specs);
+ } else {
+ final HadoopyShardSpec spec = new HadoopyShardSpec(new NoneShardSpec(), shardCount++);
+ shardSpecs.put(bucket, Lists.newArrayList(spec));
+ log.info("DateTime[%s], spec[%s]", bucket, spec);
+ }
}
config.setShardSpecs(shardSpecs);
}
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/AbstractPartitionsSpec.java b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/AbstractPartitionsSpec.java
index 90fab3e0435..e0d7deb4a32 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/AbstractPartitionsSpec.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/AbstractPartitionsSpec.java
@@ -20,6 +20,7 @@
package io.druid.indexer.partitions;
import com.fasterxml.jackson.annotation.JsonProperty;
+import com.google.common.base.Preconditions;
public abstract class AbstractPartitionsSpec implements PartitionsSpec
@@ -28,11 +29,13 @@ public abstract class AbstractPartitionsSpec implements PartitionsSpec
private final long targetPartitionSize;
private final long maxPartitionSize;
private final boolean assumeGrouped;
+ private final int numShards;
public AbstractPartitionsSpec(
Long targetPartitionSize,
Long maxPartitionSize,
- Boolean assumeGrouped
+ Boolean assumeGrouped,
+ Integer numShards
)
{
this.targetPartitionSize = targetPartitionSize == null ? -1 : targetPartitionSize;
@@ -40,6 +43,11 @@ public abstract class AbstractPartitionsSpec implements PartitionsSpec
? (long) (this.targetPartitionSize * DEFAULT_OVERSIZE_THRESHOLD)
: maxPartitionSize;
this.assumeGrouped = assumeGrouped == null ? false : assumeGrouped;
+ this.numShards = numShards == null ? -1 : numShards;
+ Preconditions.checkArgument(
+ this.targetPartitionSize == -1 || this.numShards == -1,
+ "targetPartitionsSize and shardCount both cannot be set"
+ );
}
@JsonProperty
@@ -65,4 +73,10 @@ public abstract class AbstractPartitionsSpec implements PartitionsSpec
{
return targetPartitionSize > 0;
}
+
+ @Override
+ public int getNumShards()
+ {
+ return numShards;
+ }
}
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/HashedPartitionsSpec.java b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/HashedPartitionsSpec.java
index d164cef1638..ca53b959591 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/HashedPartitionsSpec.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/HashedPartitionsSpec.java
@@ -33,10 +33,11 @@ public class HashedPartitionsSpec extends AbstractPartitionsSpec
public HashedPartitionsSpec(
@JsonProperty("targetPartitionSize") @Nullable Long targetPartitionSize,
@JsonProperty("maxPartitionSize") @Nullable Long maxPartitionSize,
- @JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped
+ @JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped,
+ @JsonProperty("numShards") @Nullable Integer numShards
)
{
- super(targetPartitionSize, maxPartitionSize, assumeGrouped);
+ super(targetPartitionSize, maxPartitionSize, assumeGrouped, numShards);
}
@Override
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/PartitionsSpec.java b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/PartitionsSpec.java
index cce5de8becf..a36555f0ea8 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/PartitionsSpec.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/PartitionsSpec.java
@@ -49,4 +49,7 @@ public interface PartitionsSpec
@JsonIgnore
public boolean isDeterminingPartitions();
+ @JsonProperty
+ public int getNumShards();
+
}
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/RandomPartitionsSpec.java b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/RandomPartitionsSpec.java
index 30f13f49478..777db4cc5c8 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/RandomPartitionsSpec.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/RandomPartitionsSpec.java
@@ -21,9 +21,6 @@ package io.druid.indexer.partitions;
import com.fasterxml.jackson.annotation.JsonCreator;
import com.fasterxml.jackson.annotation.JsonProperty;
-import io.druid.indexer.DetermineHashedPartitionsJob;
-import io.druid.indexer.HadoopDruidIndexerConfig;
-import io.druid.indexer.Jobby;
import javax.annotation.Nullable;
@@ -35,9 +32,10 @@ public class RandomPartitionsSpec extends HashedPartitionsSpec
public RandomPartitionsSpec(
@JsonProperty("targetPartitionSize") @Nullable Long targetPartitionSize,
@JsonProperty("maxPartitionSize") @Nullable Long maxPartitionSize,
- @JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped
+ @JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped,
+ @JsonProperty("numShards") @Nullable Integer numShards
)
{
- super(targetPartitionSize, maxPartitionSize, assumeGrouped);
+ super(targetPartitionSize, maxPartitionSize, assumeGrouped, numShards);
}
}
diff --git a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/SingleDimensionPartitionsSpec.java b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/SingleDimensionPartitionsSpec.java
index 118d1355914..7964c1cbe6f 100644
--- a/indexing-hadoop/src/main/java/io/druid/indexer/partitions/SingleDimensionPartitionsSpec.java
+++ b/indexing-hadoop/src/main/java/io/druid/indexer/partitions/SingleDimensionPartitionsSpec.java
@@ -41,7 +41,7 @@ public class SingleDimensionPartitionsSpec extends AbstractPartitionsSpec
@JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped
)
{
- super(targetPartitionSize, maxPartitionSize, assumeGrouped);
+ super(targetPartitionSize, maxPartitionSize, assumeGrouped, null);
this.partitionDimension = partitionDimension;
}
diff --git a/indexing-hadoop/src/test/java/io/druid/indexer/HadoopDruidIndexerConfigTest.java b/indexing-hadoop/src/test/java/io/druid/indexer/HadoopDruidIndexerConfigTest.java
index c6bb0ba719f..ba03ca7d76f 100644
--- a/indexing-hadoop/src/test/java/io/druid/indexer/HadoopDruidIndexerConfigTest.java
+++ b/indexing-hadoop/src/test/java/io/druid/indexer/HadoopDruidIndexerConfigTest.java
@@ -216,10 +216,10 @@ public class HadoopDruidIndexerConfigTest
150
);
- Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof SingleDimensionPartitionsSpec);
+ Assert.assertTrue("partitionsSpec", partitionsSpec instanceof SingleDimensionPartitionsSpec);
Assert.assertEquals(
"getPartitionDimension",
- ((SingleDimensionPartitionsSpec)partitionsSpec).getPartitionDimension(),
+ ((SingleDimensionPartitionsSpec) partitionsSpec).getPartitionDimension(),
"foo"
);
}
@@ -262,10 +262,10 @@ public class HadoopDruidIndexerConfigTest
150
);
- Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof SingleDimensionPartitionsSpec);
+ Assert.assertTrue("partitionsSpec", partitionsSpec instanceof SingleDimensionPartitionsSpec);
Assert.assertEquals(
"getPartitionDimension",
- ((SingleDimensionPartitionsSpec)partitionsSpec).getPartitionDimension(),
+ ((SingleDimensionPartitionsSpec) partitionsSpec).getPartitionDimension(),
"foo"
);
}
@@ -311,10 +311,10 @@ public class HadoopDruidIndexerConfigTest
200
);
- Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof SingleDimensionPartitionsSpec);
+ Assert.assertTrue("partitionsSpec", partitionsSpec instanceof SingleDimensionPartitionsSpec);
Assert.assertEquals(
"getPartitionDimension",
- ((SingleDimensionPartitionsSpec)partitionsSpec).getPartitionDimension(),
+ ((SingleDimensionPartitionsSpec) partitionsSpec).getPartitionDimension(),
"foo"
);
}
@@ -503,7 +503,8 @@ public class HadoopDruidIndexerConfigTest
}
@Test
- public void testRandomPartitionsSpec() throws Exception{
+ public void testRandomPartitionsSpec() throws Exception
+ {
{
final HadoopDruidIndexerConfig cfg;
@@ -542,12 +543,13 @@ public class HadoopDruidIndexerConfigTest
150
);
- Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof RandomPartitionsSpec);
+ Assert.assertTrue("partitionsSpec", partitionsSpec instanceof RandomPartitionsSpec);
}
}
@Test
- public void testHashedPartitionsSpec() throws Exception{
+ public void testHashedPartitionsSpec() throws Exception
+ {
{
final HadoopDruidIndexerConfig cfg;
@@ -586,7 +588,57 @@ public class HadoopDruidIndexerConfigTest
150
);
- Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof HashedPartitionsSpec);
+ Assert.assertTrue("partitionsSpec", partitionsSpec instanceof HashedPartitionsSpec);
}
}
+
+ @Test
+ public void testHashedPartitionsSpecShardCount() throws Exception
+ {
+ final HadoopDruidIndexerConfig cfg;
+
+ try {
+ cfg = jsonReadWriteRead(
+ "{"
+ + "\"partitionsSpec\":{"
+ + " \"type\":\"hashed\","
+ + " \"numShards\":2"
+ + " }"
+ + "}",
+ HadoopDruidIndexerConfig.class
+ );
+ }
+ catch (Exception e) {
+ throw Throwables.propagate(e);
+ }
+
+ final PartitionsSpec partitionsSpec = cfg.getPartitionsSpec();
+
+ Assert.assertEquals(
+ "isDeterminingPartitions",
+ partitionsSpec.isDeterminingPartitions(),
+ false
+ );
+
+ Assert.assertEquals(
+ "getTargetPartitionSize",
+ partitionsSpec.getTargetPartitionSize(),
+ -1
+ );
+
+ Assert.assertEquals(
+ "getMaxPartitionSize",
+ partitionsSpec.getMaxPartitionSize(),
+ -1
+ );
+
+ Assert.assertEquals(
+ "shardCount",
+ partitionsSpec.getNumShards(),
+ 2
+ );
+
+ Assert.assertTrue("partitionsSpec", partitionsSpec instanceof HashedPartitionsSpec);
+
+ }
}
diff --git a/indexing-service/pom.xml b/indexing-service/pom.xml
index 83c456fcbfa..100d3a21d52 100644
--- a/indexing-service/pom.xml
+++ b/indexing-service/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
@@ -71,7 +71,7 @@
org.apache.hadoop
- hadoop-core
+ hadoop-client
test
diff --git a/indexing-service/src/main/java/io/druid/indexing/common/task/AbstractTask.java b/indexing-service/src/main/java/io/druid/indexing/common/task/AbstractTask.java
index eaff1b9b46f..f03c552b656 100644
--- a/indexing-service/src/main/java/io/druid/indexing/common/task/AbstractTask.java
+++ b/indexing-service/src/main/java/io/druid/indexing/common/task/AbstractTask.java
@@ -64,7 +64,7 @@ public abstract class AbstractTask implements Task
this.id = Preconditions.checkNotNull(id, "id");
this.groupId = Preconditions.checkNotNull(groupId, "groupId");
this.taskResource = Preconditions.checkNotNull(taskResource, "resource");
- this.dataSource = Preconditions.checkNotNull(dataSource, "dataSource");
+ this.dataSource = Preconditions.checkNotNull(dataSource.toLowerCase(), "dataSource");
}
@JsonProperty
diff --git a/indexing-service/src/main/java/io/druid/indexing/common/task/HadoopIndexTask.java b/indexing-service/src/main/java/io/druid/indexing/common/task/HadoopIndexTask.java
index ca38f90e3cc..22529c62163 100644
--- a/indexing-service/src/main/java/io/druid/indexing/common/task/HadoopIndexTask.java
+++ b/indexing-service/src/main/java/io/druid/indexing/common/task/HadoopIndexTask.java
@@ -66,7 +66,8 @@ public class HadoopIndexTask extends AbstractTask
extensionsConfig = Initialization.makeStartupInjector().getInstance(ExtensionsConfig.class);
}
- private static String defaultHadoopCoordinates = "org.apache.hadoop:hadoop-core:1.0.3";
+ public static String DEFAULT_HADOOP_COORDINATES = "org.apache.hadoop:hadoop-client:2.3.0";
+
@JsonIgnore
private final HadoopDruidIndexerSchema schema;
@JsonIgnore
@@ -102,7 +103,7 @@ public class HadoopIndexTask extends AbstractTask
this.schema = schema;
this.hadoopDependencyCoordinates = hadoopDependencyCoordinates == null ? Arrays.asList(
- hadoopCoordinates == null ? defaultHadoopCoordinates : hadoopCoordinates
+ hadoopCoordinates == null ? DEFAULT_HADOOP_COORDINATES : hadoopCoordinates
) : hadoopDependencyCoordinates;
}
diff --git a/indexing-service/src/main/java/io/druid/indexing/overlord/IndexerDBCoordinator.java b/indexing-service/src/main/java/io/druid/indexing/overlord/IndexerDBCoordinator.java
index 429ac34f2a7..986a5696d5b 100644
--- a/indexing-service/src/main/java/io/druid/indexing/overlord/IndexerDBCoordinator.java
+++ b/indexing-service/src/main/java/io/druid/indexing/overlord/IndexerDBCoordinator.java
@@ -33,6 +33,7 @@ import io.druid.db.DbTablesConfig;
import io.druid.timeline.DataSegment;
import io.druid.timeline.TimelineObjectHolder;
import io.druid.timeline.VersionedIntervalTimeline;
+import io.druid.timeline.partition.NoneShardSpec;
import org.joda.time.DateTime;
import org.joda.time.Interval;
import org.skife.jdbi.v2.FoldController;
@@ -193,7 +194,7 @@ public class IndexerDBCoordinator
.bind("created_date", new DateTime().toString())
.bind("start", segment.getInterval().getStart().toString())
.bind("end", segment.getInterval().getEnd().toString())
- .bind("partitioned", segment.getShardSpec().getPartitionNum())
+ .bind("partitioned", (segment.getShardSpec() instanceof NoneShardSpec) ? 0 : 1)
.bind("version", segment.getVersion())
.bind("used", true)
.bind("payload", jsonMapper.writeValueAsString(segment))
diff --git a/kafka-eight/pom.xml b/kafka-eight/pom.xml
index 1c1df24d020..a4b74914eab 100644
--- a/kafka-eight/pom.xml
+++ b/kafka-eight/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
diff --git a/kafka-seven/pom.xml b/kafka-seven/pom.xml
index 96594460983..f36bd18717f 100644
--- a/kafka-seven/pom.xml
+++ b/kafka-seven/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
diff --git a/pom.xml b/pom.xml
index 2ae2afb18ea..87bf8b6228c 100644
--- a/pom.xml
+++ b/pom.xml
@@ -23,14 +23,14 @@
io.druid
druid
pom
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
druid
druid
scm:git:ssh://git@github.com/metamx/druid.git
scm:git:ssh://git@github.com/metamx/druid.git
http://www.github.com/metamx/druid
- druid-0.6.81-SNAPSHOT
+ druid-0.6.100-SNAPSHOT
@@ -39,7 +39,7 @@
UTF-8
- 0.25.3
+ 0.25.4
2.4.0
0.1.11
@@ -74,12 +74,12 @@
com.metamx
emitter
- 0.2.9
+ 0.2.11
com.metamx
http-client
- 0.8.5
+ 0.9.2
com.metamx
@@ -174,6 +174,12 @@
org.apache.curator
curator-framework
${apache.curator.version}
+
+
+ org.jboss.netty
+ netty
+
+
org.apache.curator
@@ -313,17 +319,17 @@
org.eclipse.jetty
jetty-server
- 9.1.3.v20140225
+ 9.1.4.v20140401
org.eclipse.jetty
jetty-servlet
- 9.1.3.v20140225
+ 9.1.4.v20140401
org.eclipse.jetty
jetty-servlets
- 9.1.3.v20140225
+ 9.1.4.v20140401
joda-time
@@ -373,7 +379,7 @@
com.google.protobuf
protobuf-java
- 2.4.0a
+ 2.5.0
io.tesla.aether
@@ -402,8 +408,8 @@
org.apache.hadoop
- hadoop-core
- 1.0.3
+ hadoop-client
+ 2.3.0
provided
diff --git a/processing/pom.xml b/processing/pom.xml
index 4169ea3be38..db10bb7a321 100644
--- a/processing/pom.xml
+++ b/processing/pom.xml
@@ -28,7 +28,7 @@
io.druid
druid
- 0.6.83-SNAPSHOT
+ 0.6.102-SNAPSHOT
diff --git a/processing/src/main/java/io/druid/query/BaseQuery.java b/processing/src/main/java/io/druid/query/BaseQuery.java
index 71beaa26652..32d9c3256f4 100644
--- a/processing/src/main/java/io/druid/query/BaseQuery.java
+++ b/processing/src/main/java/io/druid/query/BaseQuery.java
@@ -23,6 +23,7 @@ import com.fasterxml.jackson.annotation.JsonProperty;
import com.google.common.base.Preconditions;
import com.google.common.collect.ImmutableMap;
import com.google.common.collect.Maps;
+import com.metamx.common.ISE;
import com.metamx.common.guava.Sequence;
import io.druid.query.spec.QuerySegmentSpec;
import org.joda.time.Duration;
@@ -120,6 +121,67 @@ public abstract class BaseQuery implements Query
return retVal == null ? defaultValue : retVal;
}
+ @Override
+ public int getContextPriority(int defaultValue)
+ {
+ if (context == null) {
+ return defaultValue;
+ }
+ Object val = context.get("priority");
+ if (val == null) {
+ return defaultValue;
+ }
+ if (val instanceof String) {
+ return Integer.parseInt((String) val);
+ } else if (val instanceof Integer) {
+ return (int) val;
+ } else {
+ throw new ISE("Unknown type [%s]", val.getClass());
+ }
+ }
+
+ @Override
+ public boolean getContextBySegment(boolean defaultValue)
+ {
+ return parseBoolean("bySegment", defaultValue);
+ }
+
+ @Override
+ public boolean getContextPopulateCache(boolean defaultValue)
+ {
+ return parseBoolean("populateCache", defaultValue);
+ }
+
+ @Override
+ public boolean getContextUseCache(boolean defaultValue)
+ {
+ return parseBoolean("useCache", defaultValue);
+ }
+
+ @Override
+ public boolean getContextFinalize(boolean defaultValue)
+ {
+ return parseBoolean("finalize", defaultValue);
+ }
+
+ private boolean parseBoolean(String key, boolean defaultValue)
+ {
+ if (context == null) {
+ return defaultValue;
+ }
+ Object val = context.get(key);
+ if (val == null) {
+ return defaultValue;
+ }
+ if (val instanceof String) {
+ return Boolean.parseBoolean((String) val);
+ } else if (val instanceof Boolean) {
+ return (boolean) val;
+ } else {
+ throw new ISE("Unknown type [%s]. Cannot parse!", val.getClass());
+ }
+ }
+
protected Map computeOverridenContext(Map overrides)
{
Map overridden = Maps.newTreeMap();
diff --git a/processing/src/main/java/io/druid/query/BySegmentQueryRunner.java b/processing/src/main/java/io/druid/query/BySegmentQueryRunner.java
index d6150f63456..44094d0216a 100644
--- a/processing/src/main/java/io/druid/query/BySegmentQueryRunner.java
+++ b/processing/src/main/java/io/druid/query/BySegmentQueryRunner.java
@@ -53,7 +53,7 @@ public class BySegmentQueryRunner implements QueryRunner
@SuppressWarnings("unchecked")
public Sequence run(final Query query)
{
- if (Boolean.parseBoolean(query.getContextValue("bySegment"))) {
+ if (query.getContextBySegment(false)) {
final Sequence baseSequence = base.run(query);
return new Sequence()
{
diff --git a/processing/src/main/java/io/druid/query/BySegmentResultValueClass.java b/processing/src/main/java/io/druid/query/BySegmentResultValueClass.java
index c26bfb35706..3a3544cf47a 100644
--- a/processing/src/main/java/io/druid/query/BySegmentResultValueClass.java
+++ b/processing/src/main/java/io/druid/query/BySegmentResultValueClass.java
@@ -64,10 +64,44 @@ public class BySegmentResultValueClass
@Override
public String toString()
{
- return "BySegmentTimeseriesResultValue{" +
+ return "BySegmentResultValue{" +
"results=" + results +
", segmentId='" + segmentId + '\'' +
", interval='" + interval + '\'' +
'}';
}
+
+ @Override
+ public boolean equals(Object o)
+ {
+ if (this == o) {
+ return true;
+ }
+ if (o == null || getClass() != o.getClass()) {
+ return false;
+ }
+
+ BySegmentResultValueClass that = (BySegmentResultValueClass) o;
+
+ if (interval != null ? !interval.equals(that.interval) : that.interval != null) {
+ return false;
+ }
+ if (results != null ? !results.equals(that.results) : that.results != null) {
+ return false;
+ }
+ if (segmentId != null ? !segmentId.equals(that.segmentId) : that.segmentId != null) {
+ return false;
+ }
+
+ return true;
+ }
+
+ @Override
+ public int hashCode()
+ {
+ int result = results != null ? results.hashCode() : 0;
+ result = 31 * result + (segmentId != null ? segmentId.hashCode() : 0);
+ result = 31 * result + (interval != null ? interval.hashCode() : 0);
+ return result;
+ }
}
diff --git a/processing/src/main/java/io/druid/query/BySegmentSkippingQueryRunner.java b/processing/src/main/java/io/druid/query/BySegmentSkippingQueryRunner.java
index 8e666c30b16..13ca4dd75df 100644
--- a/processing/src/main/java/io/druid/query/BySegmentSkippingQueryRunner.java
+++ b/processing/src/main/java/io/druid/query/BySegmentSkippingQueryRunner.java
@@ -37,7 +37,7 @@ public abstract class BySegmentSkippingQueryRunner implements QueryRunner
@Override
public Sequence run(Query query)
{
- if (Boolean.parseBoolean(query.getContextValue("bySegment"))) {
+ if (query.getContextBySegment(false)) {
return baseRunner.run(query);
}
diff --git a/processing/src/main/java/io/druid/query/ChainedExecutionQueryRunner.java b/processing/src/main/java/io/druid/query/ChainedExecutionQueryRunner.java
index d3600068a23..6d7d1ea25b5 100644
--- a/processing/src/main/java/io/druid/query/ChainedExecutionQueryRunner.java
+++ b/processing/src/main/java/io/druid/query/ChainedExecutionQueryRunner.java
@@ -35,8 +35,10 @@ import com.metamx.common.logger.Logger;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
+import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
+import java.util.concurrent.Executors;
import java.util.concurrent.Future;
/**
@@ -83,7 +85,7 @@ public class ChainedExecutionQueryRunner implements QueryRunner
@Override
public Sequence run(final Query query)
{
- final int priority = Integer.parseInt((String) query.getContextValue("priority", "0"));
+ final int priority = query.getContextPriority(0);
return new BaseSequence>(
new BaseSequence.IteratorMaker>()
@@ -110,7 +112,18 @@ public class ChainedExecutionQueryRunner implements QueryRunner
if (input == null) {
throw new ISE("Input is null?! How is this possible?!");
}
- return Sequences.toList(input.run(query), Lists.newArrayList());
+
+ Sequence result = input.run(query);
+ if (result == null) {
+ throw new ISE("Got a null result! Segments are missing!");
+ }
+
+ List retVal = Sequences.toList(result, Lists.newArrayList());
+ if (retVal == null) {
+ throw new ISE("Got a null list of results! WTF?!");
+ }
+
+ return retVal;
}
catch (Exception e) {
log.error(e, "Exception with one of the sequences!");
diff --git a/processing/src/main/java/io/druid/query/FinalizeResultsQueryRunner.java b/processing/src/main/java/io/druid/query/FinalizeResultsQueryRunner.java
index 2880332e184..60cc710635e 100644
--- a/processing/src/main/java/io/druid/query/FinalizeResultsQueryRunner.java
+++ b/processing/src/main/java/io/druid/query/FinalizeResultsQueryRunner.java
@@ -24,7 +24,8 @@ import com.google.common.collect.ImmutableMap;
import com.google.common.collect.Lists;
import com.metamx.common.guava.Sequence;
import com.metamx.common.guava.Sequences;
-import io.druid.query.aggregation.AggregatorFactory;
+import io.druid.query.aggregation.FinalizeMetricManipulationFn;
+import io.druid.query.aggregation.IdentityMetricManipulationFn;
import io.druid.query.aggregation.MetricManipulationFn;
import javax.annotation.Nullable;
@@ -48,62 +49,55 @@ public class FinalizeResultsQueryRunner implements QueryRunner
@Override
public Sequence run(final Query query)
{
- final boolean isBySegment = Boolean.parseBoolean(query.getContextValue("bySegment"));
- final boolean shouldFinalize = Boolean.parseBoolean(query.getContextValue("finalize", "true"));
+ final boolean isBySegment = query.getContextBySegment(false);
+ final boolean shouldFinalize = query.getContextFinalize(true);
+
+ final Query queryToRun;
+ final Function finalizerFn;
+ final MetricManipulationFn metricManipulationFn;
+
if (shouldFinalize) {
- Function finalizerFn;
- if (isBySegment) {
- finalizerFn = new Function()
- {
- final Function baseFinalizer = toolChest.makeMetricManipulatorFn(
- query,
- new MetricManipulationFn()
- {
- @Override
- public Object manipulate(AggregatorFactory factory, Object object)
- {
- return factory.finalizeComputation(factory.deserialize(object));
- }
- }
- );
+ queryToRun = query.withOverriddenContext(ImmutableMap.of("finalize", false));
+ metricManipulationFn = new FinalizeMetricManipulationFn();
- @Override
- @SuppressWarnings("unchecked")
- public T apply(@Nullable T input)
- {
- Result> result = (Result>) input;
- BySegmentResultValueClass resultsClass = result.getValue();
-
- return (T) new Result(
- result.getTimestamp(),
- new BySegmentResultValueClass(
- Lists.transform(resultsClass.getResults(), baseFinalizer),
- resultsClass.getSegmentId(),
- resultsClass.getInterval()
- )
- );
- }
- };
- }
- else {
- finalizerFn = toolChest.makeMetricManipulatorFn(
- query,
- new MetricManipulationFn()
- {
- @Override
- public Object manipulate(AggregatorFactory factory, Object object)
- {
- return factory.finalizeComputation(object);
- }
- }
- );
- }
-
- return Sequences.map(
- baseRunner.run(query.withOverriddenContext(ImmutableMap.of("finalize", "false"))),
- finalizerFn
- );
+ } else {
+ queryToRun = query;
+ metricManipulationFn = new IdentityMetricManipulationFn();
}
- return baseRunner.run(query);
+ if (isBySegment) {
+ finalizerFn = new Function()
+ {
+ final Function baseFinalizer = toolChest.makePostComputeManipulatorFn(
+ query,
+ metricManipulationFn
+ );
+
+ @Override
+ @SuppressWarnings("unchecked")
+ public T apply(@Nullable T input)
+ {
+ Result> result = (Result>) input;
+ BySegmentResultValueClass resultsClass = result.getValue();
+
+ return (T) new Result(
+ result.getTimestamp(),
+ new BySegmentResultValueClass(
+ Lists.transform(resultsClass.getResults(), baseFinalizer),
+ resultsClass.getSegmentId(),
+ resultsClass.getInterval()
+ )
+ );
+ }
+ };
+ } else {
+ finalizerFn = toolChest.makePostComputeManipulatorFn(query, metricManipulationFn);
+ }
+
+
+ return Sequences.map(
+ baseRunner.run(queryToRun),
+ finalizerFn
+ );
+
}
}
diff --git a/processing/src/main/java/io/druid/query/GroupByParallelQueryRunner.java b/processing/src/main/java/io/druid/query/GroupByParallelQueryRunner.java
index 10dde9b26ea..20817a772e5 100644
--- a/processing/src/main/java/io/druid/query/GroupByParallelQueryRunner.java
+++ b/processing/src/main/java/io/druid/query/GroupByParallelQueryRunner.java
@@ -83,7 +83,7 @@ public class GroupByParallelQueryRunner implements QueryRunner
query,
configSupplier.get()
);
- final int priority = Integer.parseInt((String) query.getContextValue("priority", "0"));
+ final int priority = query.getContextPriority(0);
if (Iterables.isEmpty(queryables)) {
log.warn("No queryables found.");
diff --git a/processing/src/main/java/io/druid/query/Query.java b/processing/src/main/java/io/druid/query/Query.java
index 10a84328584..9b9c9e373f9 100644
--- a/processing/src/main/java/io/druid/query/Query.java
+++ b/processing/src/main/java/io/druid/query/Query.java
@@ -74,6 +74,13 @@ public interface Query
public ContextType getContextValue(String key, ContextType defaultValue);
+ // For backwards compatibility
+ @Deprecated public int getContextPriority(int defaultValue);
+ @Deprecated public boolean getContextBySegment(boolean defaultValue);
+ @Deprecated public boolean getContextPopulateCache(boolean defaultValue);
+ @Deprecated public boolean getContextUseCache(boolean defaultValue);
+ @Deprecated public boolean getContextFinalize(boolean defaultValue);
+
public Query withOverriddenContext(Map contextOverride);
public Query withQuerySegmentSpec(QuerySegmentSpec spec);
diff --git a/processing/src/main/java/io/druid/query/QueryToolChest.java b/processing/src/main/java/io/druid/query/QueryToolChest.java
index 304d3e1eb14..8299ecaad0a 100644
--- a/processing/src/main/java/io/druid/query/QueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/QueryToolChest.java
@@ -44,8 +44,16 @@ public abstract class QueryToolChest mergeSequences(Sequence> seqOfSequences);
+
public abstract ServiceMetricEvent.Builder makeMetricBuilder(QueryType query);
- public abstract Function makeMetricManipulatorFn(QueryType query, MetricManipulationFn fn);
+
+ public abstract Function makePreComputeManipulatorFn(QueryType query, MetricManipulationFn fn);
+
+ public Function makePostComputeManipulatorFn(QueryType query, MetricManipulationFn fn)
+ {
+ return makePreComputeManipulatorFn(query, fn);
+ }
+
public abstract TypeReference getResultTypeReference();
public CacheStrategy getCacheStrategy(QueryType query) {
diff --git a/processing/src/main/java/io/druid/query/aggregation/AggregatorUtil.java b/processing/src/main/java/io/druid/query/aggregation/AggregatorUtil.java
new file mode 100644
index 00000000000..809a903cddd
--- /dev/null
+++ b/processing/src/main/java/io/druid/query/aggregation/AggregatorUtil.java
@@ -0,0 +1,85 @@
+/*
+ * Druid - a distributed column store.
+ * Copyright (C) 2012, 2013, 2014 Metamarkets Group Inc.
+ *
+ * This program is free software; you can redistribute it and/or
+ * modify it under the terms of the GNU General Public License
+ * as published by the Free Software Foundation; either version 2
+ * of the License, or (at your option) any later version.
+ *
+ * This program is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with this program; if not, write to the Free Software
+ * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
+ */
+
+package io.druid.query.aggregation;
+
+import com.google.common.collect.Lists;
+import com.metamx.common.ISE;
+import com.metamx.common.Pair;
+
+import java.util.HashSet;
+import java.util.LinkedList;
+import java.util.List;
+import java.util.Set;
+
+public class AggregatorUtil
+{
+ /**
+ * returns the list of dependent postAggregators that should be calculated in order to calculate given postAgg
+ *
+ * @param postAggregatorList List of postAggregator, there is a restriction that the list should be in an order
+ * such that all the dependencies of any given aggregator should occur before that aggregator.
+ * See AggregatorUtilTest.testOutOfOrderPruneDependentPostAgg for example.
+ * @param postAggName name of the postAgg on which dependency is to be calculated
+ */
+ public static List pruneDependentPostAgg(List postAggregatorList, String postAggName)
+ {
+ LinkedList rv = Lists.newLinkedList();
+ Set deps = new HashSet<>();
+ deps.add(postAggName);
+ // Iterate backwards to find the last calculated aggregate and add dependent aggregator as we find dependencies in reverse order
+ for (PostAggregator agg : Lists.reverse(postAggregatorList)) {
+ if (deps.contains(agg.getName())) {
+ rv.addFirst(agg); // add to the beginning of List
+ deps.remove(agg.getName());
+ deps.addAll(agg.getDependentFields());
+ }
+ }
+
+ return rv;
+ }
+
+ public static Pair, List> condensedAggregators(
+ List aggList,
+ List postAggList,
+ String metric
+ )
+ {
+
+ List condensedPostAggs = AggregatorUtil.pruneDependentPostAgg(
+ postAggList,
+ metric
+ );
+ // calculate dependent aggregators for these postAgg
+ Set dependencySet = new HashSet<>();
+ dependencySet.add(metric);
+ for (PostAggregator postAggregator : condensedPostAggs) {
+ dependencySet.addAll(postAggregator.getDependentFields());
+ }
+
+ List condensedAggs = Lists.newArrayList();
+ for (AggregatorFactory aggregatorSpec : aggList) {
+ if (dependencySet.contains(aggregatorSpec.getName())) {
+ condensedAggs.add(aggregatorSpec);
+ }
+ }
+ return new Pair(condensedAggs, condensedPostAggs);
+ }
+
+}
diff --git a/processing/src/main/java/io/druid/query/aggregation/DoubleSumAggregatorFactory.java b/processing/src/main/java/io/druid/query/aggregation/DoubleSumAggregatorFactory.java
index ebd4e185ea3..c7f3eba75f4 100644
--- a/processing/src/main/java/io/druid/query/aggregation/DoubleSumAggregatorFactory.java
+++ b/processing/src/main/java/io/druid/query/aggregation/DoubleSumAggregatorFactory.java
@@ -88,6 +88,10 @@ public class DoubleSumAggregatorFactory implements AggregatorFactory
@Override
public Object deserialize(Object object)
{
+ // handle "NaN" / "Infinity" values serialized as strings in JSON
+ if (object instanceof String) {
+ return Double.parseDouble((String) object);
+ }
return object;
}
diff --git a/processing/src/main/java/io/druid/query/aggregation/FinalizeMetricManipulationFn.java b/processing/src/main/java/io/druid/query/aggregation/FinalizeMetricManipulationFn.java
new file mode 100644
index 00000000000..e532421e572
--- /dev/null
+++ b/processing/src/main/java/io/druid/query/aggregation/FinalizeMetricManipulationFn.java
@@ -0,0 +1,31 @@
+/*
+ * Druid - a distributed column store.
+ * Copyright (C) 2012, 2013 Metamarkets Group Inc.
+ *
+ * This program is free software; you can redistribute it and/or
+ * modify it under the terms of the GNU General Public License
+ * as published by the Free Software Foundation; either version 2
+ * of the License, or (at your option) any later version.
+ *
+ * This program is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with this program; if not, write to the Free Software
+ * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
+ */
+
+package io.druid.query.aggregation;
+
+/**
+ */
+public class FinalizeMetricManipulationFn implements MetricManipulationFn
+{
+ @Override
+ public Object manipulate(AggregatorFactory factory, Object object)
+ {
+ return factory.finalizeComputation(object);
+ }
+}
diff --git a/processing/src/main/java/io/druid/query/aggregation/IdentityMetricManipulationFn.java b/processing/src/main/java/io/druid/query/aggregation/IdentityMetricManipulationFn.java
new file mode 100644
index 00000000000..6b99838700a
--- /dev/null
+++ b/processing/src/main/java/io/druid/query/aggregation/IdentityMetricManipulationFn.java
@@ -0,0 +1,31 @@
+/*
+ * Druid - a distributed column store.
+ * Copyright (C) 2012, 2013 Metamarkets Group Inc.
+ *
+ * This program is free software; you can redistribute it and/or
+ * modify it under the terms of the GNU General Public License
+ * as published by the Free Software Foundation; either version 2
+ * of the License, or (at your option) any later version.
+ *
+ * This program is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with this program; if not, write to the Free Software
+ * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
+ */
+
+package io.druid.query.aggregation;
+
+/**
+ */
+public class IdentityMetricManipulationFn implements MetricManipulationFn
+{
+ @Override
+ public Object manipulate(AggregatorFactory factory, Object object)
+ {
+ return object;
+ }
+}
diff --git a/processing/src/main/java/io/druid/query/aggregation/JavaScriptAggregatorFactory.java b/processing/src/main/java/io/druid/query/aggregation/JavaScriptAggregatorFactory.java
index 6de6be09ad8..85bd9597ae8 100644
--- a/processing/src/main/java/io/druid/query/aggregation/JavaScriptAggregatorFactory.java
+++ b/processing/src/main/java/io/druid/query/aggregation/JavaScriptAggregatorFactory.java
@@ -139,6 +139,10 @@ public class JavaScriptAggregatorFactory implements AggregatorFactory
@Override
public Object deserialize(Object object)
{
+ // handle "NaN" / "Infinity" values serialized as strings in JSON
+ if (object instanceof String) {
+ return Double.parseDouble((String) object);
+ }
return object;
}
diff --git a/processing/src/main/java/io/druid/query/aggregation/MaxAggregatorFactory.java b/processing/src/main/java/io/druid/query/aggregation/MaxAggregatorFactory.java
index ee8217f820b..b731c4319e7 100644
--- a/processing/src/main/java/io/druid/query/aggregation/MaxAggregatorFactory.java
+++ b/processing/src/main/java/io/druid/query/aggregation/MaxAggregatorFactory.java
@@ -85,6 +85,7 @@ public class MaxAggregatorFactory implements AggregatorFactory
@Override
public Object deserialize(Object object)
{
+ // handle "NaN" / "Infinity" values serialized as strings in JSON
if (object instanceof String) {
return Double.parseDouble((String) object);
}
diff --git a/processing/src/main/java/io/druid/query/aggregation/MinAggregatorFactory.java b/processing/src/main/java/io/druid/query/aggregation/MinAggregatorFactory.java
index 9c3d560bacf..d3956c94b52 100644
--- a/processing/src/main/java/io/druid/query/aggregation/MinAggregatorFactory.java
+++ b/processing/src/main/java/io/druid/query/aggregation/MinAggregatorFactory.java
@@ -85,6 +85,7 @@ public class MinAggregatorFactory implements AggregatorFactory
@Override
public Object deserialize(Object object)
{
+ // handle "NaN" / "Infinity" values serialized as strings in JSON
if (object instanceof String) {
return Double.parseDouble((String) object);
}
diff --git a/processing/src/main/java/io/druid/query/aggregation/hyperloglog/HyperLogLogCollector.java b/processing/src/main/java/io/druid/query/aggregation/hyperloglog/HyperLogLogCollector.java
index bd5cfd84058..dbd766c391a 100644
--- a/processing/src/main/java/io/druid/query/aggregation/hyperloglog/HyperLogLogCollector.java
+++ b/processing/src/main/java/io/druid/query/aggregation/hyperloglog/HyperLogLogCollector.java
@@ -326,27 +326,26 @@ public abstract class HyperLogLogCollector implements Comparable dimValues = inputRow.getDimension(metricName);
- if (dimValues == null) {
+ if (rawValue instanceof HyperLogLogCollector) {
+ return (HyperLogLogCollector) inputRow.getRaw(metricName);
+ } else {
+ HyperLogLogCollector collector = HyperLogLogCollector.makeLatestCollector();
+
+ List dimValues = inputRow.getDimension(metricName);
+ if (dimValues == null) {
+ return collector;
+ }
+
+ for (String dimensionValue : dimValues) {
+ collector.add(hashFn.hashBytes(dimensionValue.getBytes(Charsets.UTF_8)).asBytes());
+ }
return collector;
}
-
- for (String dimensionValue : dimValues) {
- collector.add(hashFn.hashBytes(dimensionValue.getBytes(Charsets.UTF_8)).asBytes());
- }
- return collector;
}
};
}
diff --git a/processing/src/main/java/io/druid/query/filter/JavaScriptDimFilter.java b/processing/src/main/java/io/druid/query/filter/JavaScriptDimFilter.java
index b9cef360238..1f8740562a3 100644
--- a/processing/src/main/java/io/druid/query/filter/JavaScriptDimFilter.java
+++ b/processing/src/main/java/io/druid/query/filter/JavaScriptDimFilter.java
@@ -67,4 +67,13 @@ public class JavaScriptDimFilter implements DimFilter
.put(functionBytes)
.array();
}
+
+ @Override
+ public String toString()
+ {
+ return "JavaScriptDimFilter{" +
+ "dimension='" + dimension + '\'' +
+ ", function='" + function + '\'' +
+ '}';
+ }
}
diff --git a/processing/src/main/java/io/druid/query/filter/RegexDimFilter.java b/processing/src/main/java/io/druid/query/filter/RegexDimFilter.java
index 0644250f819..9a327dde3b5 100644
--- a/processing/src/main/java/io/druid/query/filter/RegexDimFilter.java
+++ b/processing/src/main/java/io/druid/query/filter/RegexDimFilter.java
@@ -69,4 +69,13 @@ public class RegexDimFilter implements DimFilter
.put(patternBytes)
.array();
}
+
+ @Override
+ public String toString()
+ {
+ return "RegexDimFilter{" +
+ "dimension='" + dimension + '\'' +
+ ", pattern='" + pattern + '\'' +
+ '}';
+ }
}
diff --git a/processing/src/main/java/io/druid/query/filter/SearchQueryDimFilter.java b/processing/src/main/java/io/druid/query/filter/SearchQueryDimFilter.java
index 76c5ecd0148..c6d09c0a55c 100644
--- a/processing/src/main/java/io/druid/query/filter/SearchQueryDimFilter.java
+++ b/processing/src/main/java/io/druid/query/filter/SearchQueryDimFilter.java
@@ -64,9 +64,18 @@ public class SearchQueryDimFilter implements DimFilter
final byte[] queryBytes = query.getCacheKey();
return ByteBuffer.allocate(1 + dimensionBytes.length + queryBytes.length)
- .put(DimFilterCacheHelper.SEARCH_QUERY_TYPE_ID)
- .put(dimensionBytes)
- .put(queryBytes)
- .array();
+ .put(DimFilterCacheHelper.SEARCH_QUERY_TYPE_ID)
+ .put(dimensionBytes)
+ .put(queryBytes)
+ .array();
+ }
+
+ @Override
+ public String toString()
+ {
+ return "SearchQueryDimFilter{" +
+ "dimension='" + dimension + '\'' +
+ ", query=" + query +
+ '}';
}
}
diff --git a/processing/src/main/java/io/druid/query/filter/SpatialDimFilter.java b/processing/src/main/java/io/druid/query/filter/SpatialDimFilter.java
index 6899d306602..2abcc9282b3 100644
--- a/processing/src/main/java/io/druid/query/filter/SpatialDimFilter.java
+++ b/processing/src/main/java/io/druid/query/filter/SpatialDimFilter.java
@@ -99,4 +99,13 @@ public class SpatialDimFilter implements DimFilter
result = 31 * result + (bound != null ? bound.hashCode() : 0);
return result;
}
+
+ @Override
+ public String toString()
+ {
+ return "SpatialDimFilter{" +
+ "dimension='" + dimension + '\'' +
+ ", bound=" + bound +
+ '}';
+ }
}
diff --git a/processing/src/main/java/io/druid/query/groupby/GroupByQueryEngine.java b/processing/src/main/java/io/druid/query/groupby/GroupByQueryEngine.java
index ea58501635b..1c75f1390f1 100644
--- a/processing/src/main/java/io/druid/query/groupby/GroupByQueryEngine.java
+++ b/processing/src/main/java/io/druid/query/groupby/GroupByQueryEngine.java
@@ -44,6 +44,7 @@ import io.druid.query.aggregation.AggregatorFactory;
import io.druid.query.aggregation.BufferAggregator;
import io.druid.query.aggregation.PostAggregator;
import io.druid.query.dimension.DimensionSpec;
+import io.druid.query.extraction.DimExtractionFn;
import io.druid.segment.Cursor;
import io.druid.segment.DimensionSelector;
import io.druid.segment.StorageAdapter;
@@ -69,7 +70,7 @@ public class GroupByQueryEngine
private final StupidPool intermediateResultsBufferPool;
@Inject
- public GroupByQueryEngine (
+ public GroupByQueryEngine(
Supplier config,
@Global StupidPool intermediateResultsBufferPool
)
@@ -80,6 +81,12 @@ public class GroupByQueryEngine
public Sequence process(final GroupByQuery query, StorageAdapter storageAdapter)
{
+ if (storageAdapter == null) {
+ throw new ISE(
+ "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
+ );
+ }
+
final List intervals = query.getQuerySegmentSpec().getIntervals();
if (intervals.size() != 1) {
throw new IAE("Should only have one interval, got[%s]", intervals);
@@ -182,12 +189,11 @@ public class GroupByQueryEngine
final DimensionSelector dimSelector = dims.get(0);
final IndexedInts row = dimSelector.getRow();
- if (row.size() == 0) {
+ if (row == null || row.size() == 0) {
ByteBuffer newKey = key.duplicate();
newKey.putInt(dimSelector.getValueCardinality());
unaggregatedBuffers = updateValues(newKey, dims.subList(1, dims.size()));
- }
- else {
+ } else {
for (Integer dimValue : row) {
ByteBuffer newKey = key.duplicate();
newKey.putInt(dimValue);
@@ -201,8 +207,7 @@ public class GroupByQueryEngine
retVal.addAll(unaggregatedBuffers);
}
return retVal;
- }
- else {
+ } else {
key.clear();
Integer position = positions.get(key);
int[] increments = positionMaintainer.getIncrements();
@@ -266,8 +271,7 @@ public class GroupByQueryEngine
{
if (nextVal > max) {
return null;
- }
- else {
+ } else {
int retVal = (int) nextVal;
nextVal += increment;
return retVal;
@@ -398,9 +402,14 @@ public class GroupByQueryEngine
ByteBuffer keyBuffer = input.getKey().duplicate();
for (int i = 0; i < dimensions.size(); ++i) {
final DimensionSelector dimSelector = dimensions.get(i);
+ final DimExtractionFn fn = dimensionSpecs.get(i).getDimExtractionFn();
final int dimVal = keyBuffer.getInt();
if (dimSelector.getValueCardinality() != dimVal) {
- theEvent.put(dimNames.get(i), dimSelector.lookupName(dimVal));
+ if (fn != null) {
+ theEvent.put(dimNames.get(i), fn.apply(dimSelector.lookupName(dimVal)));
+ } else {
+ theEvent.put(dimNames.get(i), dimSelector.lookupName(dimVal));
+ }
}
}
@@ -428,9 +437,10 @@ public class GroupByQueryEngine
throw new UnsupportedOperationException();
}
- public void close() {
+ public void close()
+ {
// cleanup
- for(BufferAggregator agg : aggregators) {
+ for (BufferAggregator agg : aggregators) {
agg.close();
}
}
diff --git a/processing/src/main/java/io/druid/query/groupby/GroupByQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/groupby/GroupByQueryQueryToolChest.java
index 1b77f2299ba..ab70b34db05 100644
--- a/processing/src/main/java/io/druid/query/groupby/GroupByQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/groupby/GroupByQueryQueryToolChest.java
@@ -173,7 +173,7 @@ public class GroupByQueryQueryToolChest extends QueryToolChest makeMetricManipulatorFn(final GroupByQuery query, final MetricManipulationFn fn)
+ public Function makePreComputeManipulatorFn(final GroupByQuery query, final MetricManipulationFn fn)
{
return new Function()
{
diff --git a/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryQueryToolChest.java
index 0bc9f22b1dd..98eb896476d 100644
--- a/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryQueryToolChest.java
@@ -155,7 +155,7 @@ public class SegmentMetadataQueryQueryToolChest extends QueryToolChest makeMetricManipulatorFn(
+ public Function makePreComputeManipulatorFn(
SegmentMetadataQuery query, MetricManipulationFn fn
)
{
diff --git a/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryRunnerFactory.java b/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryRunnerFactory.java
index d600b2b4499..c5b64c2d46a 100644
--- a/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryRunnerFactory.java
+++ b/processing/src/main/java/io/druid/query/metadata/SegmentMetadataQueryRunnerFactory.java
@@ -104,47 +104,47 @@ public class SegmentMetadataQueryRunnerFactory implements QueryRunnerFactory(
- Sequences.map(
- Sequences.simple(queryRunners),
- new Function, QueryRunner>()
+ Sequences.map(
+ Sequences.simple(queryRunners),
+ new Function, QueryRunner>()
+ {
+ @Override
+ public QueryRunner apply(final QueryRunner input)
+ {
+ return new QueryRunner()
{
@Override
- public QueryRunner apply(final QueryRunner input)
+ public Sequence run(final Query query)
{
- return new QueryRunner()
- {
- @Override
- public Sequence run(final Query query)
- {
- Future> future = queryExecutor.submit(
- new Callable>()
- {
- @Override
- public Sequence call() throws Exception
- {
- return new ExecutorExecutingSequence(
- input.run(query),
- queryExecutor
- );
- }
- }
- );
- try {
- return future.get();
+ Future> future = queryExecutor.submit(
+ new Callable>()
+ {
+ @Override
+ public Sequence call() throws Exception
+ {
+ return new ExecutorExecutingSequence(
+ input.run(query),
+ queryExecutor
+ );
+ }
}
- catch (InterruptedException e) {
- throw Throwables.propagate(e);
- }
- catch (ExecutionException e) {
- throw Throwables.propagate(e);
- }
- }
- };
+ );
+ try {
+ return future.get();
+ }
+ catch (InterruptedException e) {
+ throw Throwables.propagate(e);
+ }
+ catch (ExecutionException e) {
+ throw Throwables.propagate(e);
+ }
}
- }
- )
- );
+ };
+ }
+ }
+ )
+ );
}
@Override
diff --git a/processing/src/main/java/io/druid/query/metadata/metadata/SegmentMetadataQuery.java b/processing/src/main/java/io/druid/query/metadata/metadata/SegmentMetadataQuery.java
index 098a5462d3b..c6d6ecca0bd 100644
--- a/processing/src/main/java/io/druid/query/metadata/metadata/SegmentMetadataQuery.java
+++ b/processing/src/main/java/io/druid/query/metadata/metadata/SegmentMetadataQuery.java
@@ -32,7 +32,6 @@ import java.util.Map;
public class SegmentMetadataQuery extends BaseQuery
{
-
private final ColumnIncluderator toInclude;
private final boolean merge;
diff --git a/processing/src/main/java/io/druid/query/search/SearchQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/search/SearchQueryQueryToolChest.java
index 6e14ef1c1f3..a8429ad2726 100644
--- a/processing/src/main/java/io/druid/query/search/SearchQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/search/SearchQueryQueryToolChest.java
@@ -129,7 +129,7 @@ public class SearchQueryQueryToolChest extends QueryToolChest, Result> makeMetricManipulatorFn(
+ public Function, Result> makePreComputeManipulatorFn(
SearchQuery query, MetricManipulationFn fn
)
{
@@ -294,7 +294,7 @@ public class SearchQueryQueryToolChest extends QueryToolChest>
{
private static final EmittingLogger log = new EmittingLogger(SearchQueryRunner.class);
@@ -99,12 +99,10 @@ public class SearchQueryRunner implements QueryRunner>
ConciseSet set = new ConciseSet();
set.add(0);
baseFilter = ImmutableConciseSet.newImmutableFromMutable(set);
- }
- else {
+ } else {
baseFilter = ImmutableConciseSet.complement(new ImmutableConciseSet(), index.getNumRows());
}
- }
- else {
+ } else {
baseFilter = filter.goConcise(new ColumnSelectorBitmapIndexSelector(index));
}
@@ -133,49 +131,52 @@ public class SearchQueryRunner implements QueryRunner>
}
final StorageAdapter adapter = segment.asStorageAdapter();
- if (adapter != null) {
- Iterable dimsToSearch;
- if (dimensions == null || dimensions.isEmpty()) {
- dimsToSearch = adapter.getAvailableDimensions();
- } else {
- dimsToSearch = dimensions;
+
+ if (adapter == null) {
+ log.makeAlert("WTF!? Unable to process search query on segment.")
+ .addData("segment", segment.getIdentifier())
+ .addData("query", query).emit();
+ throw new ISE(
+ "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
+ );
+ }
+
+ Iterable dimsToSearch;
+ if (dimensions == null || dimensions.isEmpty()) {
+ dimsToSearch = adapter.getAvailableDimensions();
+ } else {
+ dimsToSearch = dimensions;
+ }
+
+ final TreeSet retVal = Sets.newTreeSet(query.getSort().getComparator());
+
+ final Iterable cursors = adapter.makeCursors(filter, segment.getDataInterval(), QueryGranularity.ALL);
+ for (Cursor cursor : cursors) {
+ Map dimSelectors = Maps.newHashMap();
+ for (String dim : dimsToSearch) {
+ dimSelectors.put(dim, cursor.makeDimensionSelector(dim));
}
- final TreeSet retVal = Sets.newTreeSet(query.getSort().getComparator());
-
- final Iterable cursors = adapter.makeCursors(filter, segment.getDataInterval(), QueryGranularity.ALL);
- for (Cursor cursor : cursors) {
- Map dimSelectors = Maps.newHashMap();
- for (String dim : dimsToSearch) {
- dimSelectors.put(dim, cursor.makeDimensionSelector(dim));
- }
-
- while (!cursor.isDone()) {
- for (Map.Entry entry : dimSelectors.entrySet()) {
- final DimensionSelector selector = entry.getValue();
- final IndexedInts vals = selector.getRow();
- for (int i = 0; i < vals.size(); ++i) {
- final String dimVal = selector.lookupName(vals.get(i));
- if (searchQuerySpec.accept(dimVal)) {
- retVal.add(new SearchHit(entry.getKey(), dimVal));
- if (retVal.size() >= limit) {
- return makeReturnResult(limit, retVal);
- }
+ while (!cursor.isDone()) {
+ for (Map.Entry entry : dimSelectors.entrySet()) {
+ final DimensionSelector selector = entry.getValue();
+ final IndexedInts vals = selector.getRow();
+ for (int i = 0; i < vals.size(); ++i) {
+ final String dimVal = selector.lookupName(vals.get(i));
+ if (searchQuerySpec.accept(dimVal)) {
+ retVal.add(new SearchHit(entry.getKey(), dimVal));
+ if (retVal.size() >= limit) {
+ return makeReturnResult(limit, retVal);
}
}
}
-
- cursor.advance();
}
- }
- return makeReturnResult(limit, retVal);
+ cursor.advance();
+ }
}
- log.makeAlert("WTF!? Unable to process search query on segment.")
- .addData("segment", segment.getIdentifier())
- .addData("query", query);
- return Sequences.empty();
+ return makeReturnResult(limit, retVal);
}
private Sequence> makeReturnResult(int limit, TreeSet retVal)
diff --git a/processing/src/main/java/io/druid/query/select/EventHolder.java b/processing/src/main/java/io/druid/query/select/EventHolder.java
index 1ac3661d1f5..aa4f6418289 100644
--- a/processing/src/main/java/io/druid/query/select/EventHolder.java
+++ b/processing/src/main/java/io/druid/query/select/EventHolder.java
@@ -22,6 +22,7 @@ package io.druid.query.select;
import com.fasterxml.jackson.annotation.JsonCreator;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.google.common.collect.Maps;
+import com.metamx.common.ISE;
import org.joda.time.DateTime;
import java.util.Map;
@@ -50,7 +51,14 @@ public class EventHolder
public DateTime getTimestamp()
{
- return (DateTime) event.get(timestampKey);
+ Object retVal = event.get(timestampKey);
+ if (retVal instanceof String) {
+ return new DateTime(retVal);
+ } else if (retVal instanceof DateTime) {
+ return (DateTime) retVal;
+ } else {
+ throw new ISE("Do not understand format [%s]", retVal.getClass());
+ }
}
@JsonProperty
diff --git a/processing/src/main/java/io/druid/query/select/SelectQueryEngine.java b/processing/src/main/java/io/druid/query/select/SelectQueryEngine.java
index 3238ac01f7a..f5bc7aba043 100644
--- a/processing/src/main/java/io/druid/query/select/SelectQueryEngine.java
+++ b/processing/src/main/java/io/druid/query/select/SelectQueryEngine.java
@@ -22,6 +22,7 @@ package io.druid.query.select;
import com.google.common.base.Function;
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
+import com.metamx.common.ISE;
import com.metamx.common.guava.BaseSequence;
import com.metamx.common.guava.Sequence;
import io.druid.query.QueryRunnerHelper;
@@ -54,6 +55,12 @@ public class SelectQueryEngine
{
final StorageAdapter adapter = segment.asStorageAdapter();
+ if (adapter == null) {
+ throw new ISE(
+ "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
+ );
+ }
+
final Iterable dims;
if (query.getDimensions() == null || query.getDimensions().isEmpty()) {
dims = adapter.getAvailableDimensions();
diff --git a/processing/src/main/java/io/druid/query/select/SelectQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/select/SelectQueryQueryToolChest.java
index 1533c48c383..f3bbe028ed8 100644
--- a/processing/src/main/java/io/druid/query/select/SelectQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/select/SelectQueryQueryToolChest.java
@@ -131,7 +131,7 @@ public class SelectQueryQueryToolChest extends QueryToolChest, Result> makeMetricManipulatorFn(
+ public Function, Result> makePreComputeManipulatorFn(
final SelectQuery query, final MetricManipulationFn fn
)
{
@@ -170,10 +170,9 @@ public class SelectQueryQueryToolChest extends QueryToolChest metrics = Sets.newTreeSet();
if (query.getMetrics() != null) {
- dimensions.addAll(query.getMetrics());
+ metrics.addAll(query.getMetrics());
}
final byte[][] metricBytes = new byte[metrics.size()][];
diff --git a/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryQueryToolChest.java
index 95715bb7511..7186b1a6e38 100644
--- a/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryQueryToolChest.java
@@ -123,7 +123,7 @@ public class TimeBoundaryQueryQueryToolChest
}
@Override
- public Function, Result> makeMetricManipulatorFn(
+ public Function, Result> makePreComputeManipulatorFn(
TimeBoundaryQuery query, MetricManipulationFn fn
)
{
diff --git a/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryRunnerFactory.java b/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryRunnerFactory.java
index cd732de18e4..16e9ae832fa 100644
--- a/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryRunnerFactory.java
+++ b/processing/src/main/java/io/druid/query/timeboundary/TimeBoundaryQueryRunnerFactory.java
@@ -87,6 +87,12 @@ public class TimeBoundaryQueryRunnerFactory
@Override
public Iterator> make()
{
+ if (adapter == null) {
+ throw new ISE(
+ "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
+ );
+ }
+
return legacyQuery.buildResult(
adapter.getInterval().getStart(),
adapter.getMinTime(),
diff --git a/processing/src/main/java/io/druid/query/timeseries/TimeseriesBinaryFn.java b/processing/src/main/java/io/druid/query/timeseries/TimeseriesBinaryFn.java
index f8530ce334f..7cecb554a92 100644
--- a/processing/src/main/java/io/druid/query/timeseries/TimeseriesBinaryFn.java
+++ b/processing/src/main/java/io/druid/query/timeseries/TimeseriesBinaryFn.java
@@ -24,7 +24,6 @@ import io.druid.granularity.AllGranularity;
import io.druid.granularity.QueryGranularity;
import io.druid.query.Result;
import io.druid.query.aggregation.AggregatorFactory;
-import io.druid.query.aggregation.PostAggregator;
import java.util.LinkedHashMap;
import java.util.List;
@@ -37,17 +36,14 @@ public class TimeseriesBinaryFn
{
private final QueryGranularity gran;
private final List aggregations;
- private final List postAggregations;
public TimeseriesBinaryFn(
QueryGranularity granularity,
- List aggregations,
- List postAggregations
+ List aggregations
)
{
this.gran = granularity;
this.aggregations = aggregations;
- this.postAggregations = postAggregations;
}
@Override
@@ -71,11 +67,6 @@ public class TimeseriesBinaryFn
retVal.put(metricName, factory.combine(arg1Val.getMetric(metricName), arg2Val.getMetric(metricName)));
}
- for (PostAggregator pf : postAggregations) {
- final String metricName = pf.getName();
- retVal.put(metricName, pf.compute(retVal));
- }
-
return (gran instanceof AllGranularity) ?
new Result(
arg1.getTimestamp(),
diff --git a/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryEngine.java b/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryEngine.java
index b57105aa654..6ab42477890 100644
--- a/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryEngine.java
+++ b/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryEngine.java
@@ -20,6 +20,7 @@
package io.druid.query.timeseries;
import com.google.common.base.Function;
+import com.metamx.common.ISE;
import com.metamx.common.guava.BaseSequence;
import com.metamx.common.guava.Sequence;
import io.druid.query.QueryRunnerHelper;
@@ -40,6 +41,12 @@ public class TimeseriesQueryEngine
{
public Sequence> process(final TimeseriesQuery query, final StorageAdapter adapter)
{
+ if (adapter == null) {
+ throw new ISE(
+ "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
+ );
+ }
+
return new BaseSequence, Iterator>>(
new BaseSequence.IteratorMaker, Iterator>>()
{
@@ -74,10 +81,6 @@ public class TimeseriesQueryEngine
bob.addMetric(aggregator);
}
- for (PostAggregator postAgg : postAggregatorSpecs) {
- bob.addMetric(postAgg);
- }
-
Result retVal = bob.build();
// cleanup
diff --git a/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryQueryToolChest.java
index b4752266944..482e92adc3e 100644
--- a/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/timeseries/TimeseriesQueryQueryToolChest.java
@@ -101,8 +101,7 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest, Result> makeMetricManipulatorFn(
- final TimeseriesQuery query, final MetricManipulationFn fn
- )
- {
- return new Function, Result>()
- {
- @Override
- public Result apply(Result result)
- {
- final Map values = Maps.newHashMap();
- final TimeseriesResultValue holder = result.getValue();
- for (AggregatorFactory agg : query.getAggregatorSpecs()) {
- values.put(agg.getName(), fn.manipulate(agg, holder.getMetric(agg.getName())));
- }
- for (PostAggregator postAgg : query.getPostAggregatorSpecs()) {
- values.put(postAgg.getName(), holder.getMetric(postAgg.getName()));
- }
- return new Result(
- result.getTimestamp(),
- new TimeseriesResultValue(values)
- );
- }
- };
- }
-
@Override
public TypeReference> getResultTypeReference()
{
@@ -169,7 +142,6 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest, Object, TimeseriesQuery>()
{
private final List aggs = query.getAggregatorSpecs();
- private final List postAggs = query.getPostAggregatorSpecs();
@Override
public byte[] computeCacheKey(TimeseriesQuery query)
@@ -238,10 +210,6 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest(
timestamp,
new TimeseriesResultValue(retVal)
@@ -268,4 +236,52 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest, Result> makePreComputeManipulatorFn(
+ final TimeseriesQuery query, final MetricManipulationFn fn
+ )
+ {
+ return makeComputeManipulatorFn(query, fn, false);
+ }
+
+ @Override
+ public Function, Result> makePostComputeManipulatorFn(
+ TimeseriesQuery query, MetricManipulationFn fn
+ )
+ {
+ return makeComputeManipulatorFn(query, fn, true);
+ }
+
+ private Function, Result> makeComputeManipulatorFn(
+ final TimeseriesQuery query, final MetricManipulationFn fn, final boolean calculatePostAggs
+ )
+ {
+ return new Function, Result>()
+ {
+ @Override
+ public Result apply(Result result)
+ {
+ final Map values = Maps.newHashMap();
+ final TimeseriesResultValue holder = result.getValue();
+ if (calculatePostAggs) {
+ // put non finalized aggregators for calculating dependent post Aggregators
+ for (AggregatorFactory agg : query.getAggregatorSpecs()) {
+ values.put(agg.getName(), holder.getMetric(agg.getName()));
+ }
+ for (PostAggregator postAgg : query.getPostAggregatorSpecs()) {
+ values.put(postAgg.getName(), postAgg.compute(values));
+ }
+ }
+ for (AggregatorFactory agg : query.getAggregatorSpecs()) {
+ values.put(agg.getName(), fn.manipulate(agg, holder.getMetric(agg.getName())));
+ }
+
+ return new Result(
+ result.getTimestamp(),
+ new TimeseriesResultValue(values)
+ );
+ }
+ };
+ }
}
diff --git a/processing/src/main/java/io/druid/query/topn/AggregateTopNMetricFirstAlgorithm.java b/processing/src/main/java/io/druid/query/topn/AggregateTopNMetricFirstAlgorithm.java
index 84be056fea1..254d13d581b 100644
--- a/processing/src/main/java/io/druid/query/topn/AggregateTopNMetricFirstAlgorithm.java
+++ b/processing/src/main/java/io/druid/query/topn/AggregateTopNMetricFirstAlgorithm.java
@@ -19,10 +19,11 @@
package io.druid.query.topn;
-import com.google.common.collect.Lists;
import com.metamx.common.ISE;
+import com.metamx.common.Pair;
import io.druid.collections.StupidPool;
import io.druid.query.aggregation.AggregatorFactory;
+import io.druid.query.aggregation.AggregatorUtil;
import io.druid.query.aggregation.PostAggregator;
import io.druid.segment.Capabilities;
import io.druid.segment.Cursor;
@@ -56,7 +57,6 @@ public class AggregateTopNMetricFirstAlgorithm implements TopNAlgorithm, List> condensedAggPostAggPair = AggregatorUtil.condensedAggregators(
+ query.getAggregatorSpecs(),
+ query.getPostAggregatorSpecs(),
+ metric
+ );
- // Find either the aggregator or post aggregator to do the topN over
- List condensedAggs = Lists.newArrayList();
- for (AggregatorFactory aggregatorSpec : query.getAggregatorSpecs()) {
- if (aggregatorSpec.getName().equalsIgnoreCase(metric)) {
- condensedAggs.add(aggregatorSpec);
- break;
- }
- }
- List condensedPostAggs = Lists.newArrayList();
- if (condensedAggs.isEmpty()) {
- for (PostAggregator postAggregator : query.getPostAggregatorSpecs()) {
- if (postAggregator.getName().equalsIgnoreCase(metric)) {
- condensedPostAggs.add(postAggregator);
-
- // Add all dependent metrics
- for (AggregatorFactory aggregatorSpec : query.getAggregatorSpecs()) {
- if (postAggregator.getDependentFields().contains(aggregatorSpec.getName())) {
- condensedAggs.add(aggregatorSpec);
- }
- }
- break;
- }
- }
- }
- if (condensedAggs.isEmpty() && condensedPostAggs.isEmpty()) {
+ if (condensedAggPostAggPair.lhs.isEmpty() && condensedAggPostAggPair.rhs.isEmpty()) {
throw new ISE("WTF! Can't find the metric to do topN over?");
}
-
// Run topN for only a single metric
TopNQuery singleMetricQuery = new TopNQueryBuilder().copy(query)
- .aggregators(condensedAggs)
- .postAggregators(condensedPostAggs)
+ .aggregators(condensedAggPostAggPair.lhs)
+ .postAggregators(condensedAggPostAggPair.rhs)
.build();
+ final TopNResultBuilder singleMetricResultBuilder = BaseTopNAlgorithm.makeResultBuilder(params, singleMetricQuery);
PooledTopNAlgorithm singleMetricAlgo = new PooledTopNAlgorithm(capabilities, singleMetricQuery, bufferPool);
PooledTopNAlgorithm.PooledTopNParams singleMetricParam = null;
diff --git a/processing/src/main/java/io/druid/query/topn/BaseTopNAlgorithm.java b/processing/src/main/java/io/druid/query/topn/BaseTopNAlgorithm.java
index 0c32d8db676..9d8baceb2c9 100644
--- a/processing/src/main/java/io/druid/query/topn/BaseTopNAlgorithm.java
+++ b/processing/src/main/java/io/druid/query/topn/BaseTopNAlgorithm.java
@@ -28,6 +28,7 @@ import io.druid.segment.Cursor;
import io.druid.segment.DimensionSelector;
import java.util.Arrays;
+import java.util.Comparator;
import java.util.List;
/**
@@ -230,4 +231,18 @@ public abstract class BaseTopNAlgorithm aggFactories,
+ List postAggs
)
{
- return delegate.getResultBuilder(timestamp, dimSpec, threshold, comparator);
+ return delegate.getResultBuilder(timestamp, dimSpec, threshold, comparator, aggFactories, postAggs);
}
@Override
@@ -102,15 +103,27 @@ public class InvertedTopNMetricSpec implements TopNMetricSpec
delegate.initTopNAlgorithmSelector(selector);
}
+ @Override
+ public String getMetricName(DimensionSpec dimSpec)
+ {
+ return delegate.getMetricName(dimSpec);
+ }
+
@Override
public boolean equals(Object o)
{
- if (this == o) return true;
- if (o == null || getClass() != o.getClass()) return false;
+ if (this == o) {
+ return true;
+ }
+ if (o == null || getClass() != o.getClass()) {
+ return false;
+ }
InvertedTopNMetricSpec that = (InvertedTopNMetricSpec) o;
- if (delegate != null ? !delegate.equals(that.delegate) : that.delegate != null) return false;
+ if (delegate != null ? !delegate.equals(that.delegate) : that.delegate != null) {
+ return false;
+ }
return true;
}
diff --git a/processing/src/main/java/io/druid/query/topn/LexicographicTopNMetricSpec.java b/processing/src/main/java/io/druid/query/topn/LexicographicTopNMetricSpec.java
index 0f2c8344b14..b7c7c6a2565 100644
--- a/processing/src/main/java/io/druid/query/topn/LexicographicTopNMetricSpec.java
+++ b/processing/src/main/java/io/druid/query/topn/LexicographicTopNMetricSpec.java
@@ -80,10 +80,12 @@ public class LexicographicTopNMetricSpec implements TopNMetricSpec
DateTime timestamp,
DimensionSpec dimSpec,
int threshold,
- Comparator comparator
+ Comparator comparator,
+ List aggFactories,
+ List postAggs
)
{
- return new TopNLexicographicResultBuilder(timestamp, dimSpec, threshold, previousStop, comparator);
+ return new TopNLexicographicResultBuilder(timestamp, dimSpec, threshold, previousStop, comparator, aggFactories);
}
@Override
@@ -111,6 +113,12 @@ public class LexicographicTopNMetricSpec implements TopNMetricSpec
selector.setAggregateAllMetrics(true);
}
+ @Override
+ public String getMetricName(DimensionSpec dimSpec)
+ {
+ return dimSpec.getOutputName();
+ }
+
@Override
public String toString()
{
diff --git a/processing/src/main/java/io/druid/query/topn/NumericTopNMetricSpec.java b/processing/src/main/java/io/druid/query/topn/NumericTopNMetricSpec.java
index 76f1a9341ac..9ad97e239cd 100644
--- a/processing/src/main/java/io/druid/query/topn/NumericTopNMetricSpec.java
+++ b/processing/src/main/java/io/druid/query/topn/NumericTopNMetricSpec.java
@@ -121,10 +121,12 @@ public class NumericTopNMetricSpec implements TopNMetricSpec
DateTime timestamp,
DimensionSpec dimSpec,
int threshold,
- Comparator comparator
+ Comparator comparator,
+ List aggFactories,
+ List postAggs
)
{
- return new TopNNumericResultBuilder(timestamp, dimSpec, metric, threshold, comparator);
+ return new TopNNumericResultBuilder(timestamp, dimSpec, metric, threshold, comparator, aggFactories, postAggs);
}
@Override
@@ -150,6 +152,12 @@ public class NumericTopNMetricSpec implements TopNMetricSpec
selector.setAggregateTopNMetricFirst(true);
}
+ @Override
+ public String getMetricName(DimensionSpec dimSpec)
+ {
+ return metric;
+ }
+
@Override
public String toString()
{
diff --git a/processing/src/main/java/io/druid/query/topn/PooledTopNAlgorithm.java b/processing/src/main/java/io/druid/query/topn/PooledTopNAlgorithm.java
index d87631c7b57..a8e3f324467 100644
--- a/processing/src/main/java/io/druid/query/topn/PooledTopNAlgorithm.java
+++ b/processing/src/main/java/io/druid/query/topn/PooledTopNAlgorithm.java
@@ -35,7 +35,8 @@ import java.util.Comparator;
/**
*/
-public class PooledTopNAlgorithm extends BaseTopNAlgorithm
+public class PooledTopNAlgorithm
+ extends BaseTopNAlgorithm
{
private final Capabilities capabilities;
private final TopNQuery query;
@@ -113,13 +114,7 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm resultsBufHolder;
private final ByteBuffer resultsBuf;
private final int[] aggregatorSizes;
@@ -278,6 +266,11 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm getResultsBufHolder()
{
return resultsBufHolder;
diff --git a/processing/src/main/java/io/druid/query/topn/TopNAlgorithm.java b/processing/src/main/java/io/druid/query/topn/TopNAlgorithm.java
index 89bac871441..3d5c90e2b20 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNAlgorithm.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNAlgorithm.java
@@ -33,8 +33,6 @@ public interface TopNAlgorithm
public TopNParams makeInitParams(DimensionSelector dimSelector, Cursor cursor);
- public TopNResultBuilder makeResultBuilder(Parameters params);
-
public void run(
Parameters params,
TopNResultBuilder resultBuilder,
diff --git a/processing/src/main/java/io/druid/query/topn/TopNBinaryFn.java b/processing/src/main/java/io/druid/query/topn/TopNBinaryFn.java
index 437c28f640f..4c02da447aa 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNBinaryFn.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNBinaryFn.java
@@ -24,6 +24,7 @@ import io.druid.granularity.AllGranularity;
import io.druid.granularity.QueryGranularity;
import io.druid.query.Result;
import io.druid.query.aggregation.AggregatorFactory;
+import io.druid.query.aggregation.AggregatorUtil;
import io.druid.query.aggregation.PostAggregator;
import io.druid.query.dimension.DimensionSpec;
import org.joda.time.DateTime;
@@ -63,7 +64,11 @@ public class TopNBinaryFn implements BinaryFn, Result, Result retVals = new LinkedHashMap();
+ Map retVals = new LinkedHashMap<>();
TopNResultValue arg1Vals = arg1.getValue();
TopNResultValue arg2Vals = arg2.getValue();
@@ -92,7 +97,8 @@ public class TopNBinaryFn implements BinaryFn, Result retVal = new LinkedHashMap();
+ // size of map = aggregator + topNDim + postAgg (If sorting is done on post agg field)
+ Map retVal = new LinkedHashMap<>(aggregations.size() + 2);
retVal.put(dimension, dimensionValue);
for (AggregatorFactory factory : aggregations) {
@@ -117,7 +123,14 @@ public class TopNBinaryFn implements BinaryFn, Result aggFactories;
private MinMaxPriorityQueue pQueue = null;
public TopNLexicographicResultBuilder(
@@ -48,12 +48,14 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
DimensionSpec dimSpec,
int threshold,
String previousStop,
- final Comparator comparator
+ final Comparator comparator,
+ List aggFactories
)
{
this.timestamp = timestamp;
this.dimSpec = dimSpec;
this.previousStop = previousStop;
+ this.aggFactories = aggFactories;
instantiatePQueue(threshold, comparator);
}
@@ -62,9 +64,7 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
public TopNResultBuilder addEntry(
String dimName,
Object dimValIndex,
- Object[] metricVals,
- List aggFactories,
- List postAggs
+ Object[] metricVals
)
{
Map metricValues = Maps.newLinkedHashMap();
@@ -75,9 +75,6 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
for (Object metricVal : metricVals) {
metricValues.put(aggsIter.next().getName(), metricVal);
}
- for (PostAggregator postAgg : postAggs) {
- metricValues.put(postAgg.getName(), postAgg.compute(metricValues));
- }
pQueue.add(new DimValHolder.Builder().withDirName(dimName).withMetricValues(metricValues).build());
}
diff --git a/processing/src/main/java/io/druid/query/topn/TopNMapFn.java b/processing/src/main/java/io/druid/query/topn/TopNMapFn.java
index c013d546f7f..5479eeb72f8 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNMapFn.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNMapFn.java
@@ -24,6 +24,8 @@ import io.druid.query.Result;
import io.druid.segment.Cursor;
import io.druid.segment.DimensionSelector;
+import java.util.Comparator;
+
public class TopNMapFn implements Function>
{
private final TopNQuery query;
@@ -52,7 +54,7 @@ public class TopNMapFn implements Function>
try {
params = topNAlgorithm.makeInitParams(dimSelector, cursor);
- TopNResultBuilder resultBuilder = topNAlgorithm.makeResultBuilder(params);
+ TopNResultBuilder resultBuilder = BaseTopNAlgorithm.makeResultBuilder(params, query);
topNAlgorithm.run(params, resultBuilder, null);
diff --git a/processing/src/main/java/io/druid/query/topn/TopNMetricSpec.java b/processing/src/main/java/io/druid/query/topn/TopNMetricSpec.java
index c2baf13e3eb..267f2f278dd 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNMetricSpec.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNMetricSpec.java
@@ -47,7 +47,9 @@ public interface TopNMetricSpec
DateTime timestamp,
DimensionSpec dimSpec,
int threshold,
- Comparator comparator
+ Comparator comparator,
+ List aggFactories,
+ List postAggs
);
public byte[] getCacheKey();
@@ -55,4 +57,6 @@ public interface TopNMetricSpec
public TopNMetricSpecBuilder configureOptimizer(TopNMetricSpecBuilder builder);
public void initTopNAlgorithmSelector(TopNAlgorithmSelector selector);
+
+ public String getMetricName(DimensionSpec dimSpec);
}
diff --git a/processing/src/main/java/io/druid/query/topn/TopNNumericResultBuilder.java b/processing/src/main/java/io/druid/query/topn/TopNNumericResultBuilder.java
index 9f6479baee4..4a40f4bb2d5 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNNumericResultBuilder.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNNumericResultBuilder.java
@@ -23,6 +23,7 @@ import com.google.common.collect.Maps;
import com.google.common.collect.MinMaxPriorityQueue;
import io.druid.query.Result;
import io.druid.query.aggregation.AggregatorFactory;
+import io.druid.query.aggregation.AggregatorUtil;
import io.druid.query.aggregation.PostAggregator;
import io.druid.query.dimension.DimensionSpec;
import org.joda.time.DateTime;
@@ -40,7 +41,8 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
private final DateTime timestamp;
private final DimensionSpec dimSpec;
private final String metricName;
-
+ private final List aggFactories;
+ private final List postAggs;
private MinMaxPriorityQueue pQueue = null;
public TopNNumericResultBuilder(
@@ -48,12 +50,16 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
DimensionSpec dimSpec,
String metricName,
int threshold,
- final Comparator comparator
+ final Comparator comparator,
+ List aggFactories,
+ List postAggs
)
{
this.timestamp = timestamp;
this.dimSpec = dimSpec;
this.metricName = metricName;
+ this.aggFactories = aggFactories;
+ this.postAggs = AggregatorUtil.pruneDependentPostAgg(postAggs, this.metricName);
instantiatePQueue(threshold, comparator);
}
@@ -62,9 +68,7 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
public TopNResultBuilder addEntry(
String dimName,
Object dimValIndex,
- Object[] metricVals,
- List aggFactories,
- List postAggs
+ Object[] metricVals
)
{
Map metricValues = Maps.newLinkedHashMap();
@@ -75,6 +79,7 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
for (Object metricVal : metricVals) {
metricValues.put(aggFactoryIter.next().getName(), metricVal);
}
+
for (PostAggregator postAgg : postAggs) {
metricValues.put(postAgg.getName(), postAgg.compute(metricValues));
}
diff --git a/processing/src/main/java/io/druid/query/topn/TopNQueryEngine.java b/processing/src/main/java/io/druid/query/topn/TopNQueryEngine.java
index 09a158b31de..1f3a8892733 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNQueryEngine.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNQueryEngine.java
@@ -21,7 +21,7 @@ package io.druid.query.topn;
import com.google.common.base.Function;
import com.google.common.base.Preconditions;
-import com.google.common.collect.Lists;
+import com.metamx.common.ISE;
import com.metamx.common.guava.FunctionalIterable;
import com.metamx.common.logger.Logger;
import io.druid.collections.StupidPool;
@@ -53,6 +53,12 @@ public class TopNQueryEngine
public Iterable> query(final TopNQuery query, final StorageAdapter adapter)
{
+ if (adapter == null) {
+ throw new ISE(
+ "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
+ );
+ }
+
final List queryIntervals = query.getQuerySegmentSpec().getIntervals();
final Filter filter = Filters.convertDimensionFilters(query.getDimensionsFilter());
final QueryGranularity granularity = query.getGranularity();
@@ -62,10 +68,6 @@ public class TopNQueryEngine
queryIntervals.size() == 1, "Can only handle a single interval, got[%s]", queryIntervals
);
- if (mapFn == null) {
- return Lists.newArrayList();
- }
-
return FunctionalIterable
.create(adapter.makeCursors(filter, queryIntervals.get(0), granularity))
.transform(
@@ -84,13 +86,6 @@ public class TopNQueryEngine
private Function> getMapFn(TopNQuery query, final StorageAdapter adapter)
{
- if (adapter == null) {
- log.warn(
- "Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped. Returning empty results."
- );
- return null;
- }
-
final Capabilities capabilities = adapter.getCapabilities();
final int cardinality = adapter.getDimensionCardinality(query.getDimensionSpec().getDimension());
int numBytesPerRecord = 0;
diff --git a/processing/src/main/java/io/druid/query/topn/TopNQueryQueryToolChest.java b/processing/src/main/java/io/druid/query/topn/TopNQueryQueryToolChest.java
index a7d77fde396..5db416f1d0b 100644
--- a/processing/src/main/java/io/druid/query/topn/TopNQueryQueryToolChest.java
+++ b/processing/src/main/java/io/druid/query/topn/TopNQueryQueryToolChest.java
@@ -46,6 +46,7 @@ import io.druid.query.Result;
import io.druid.query.ResultGranularTimestampComparator;
import io.druid.query.ResultMergeQueryRunner;
import io.druid.query.aggregation.AggregatorFactory;
+import io.druid.query.aggregation.AggregatorUtil;
import io.druid.query.aggregation.MetricManipulationFn;
import io.druid.query.aggregation.PostAggregator;
import io.druid.query.filter.DimFilter;
@@ -64,11 +65,13 @@ import java.util.Map;
public class TopNQueryQueryToolChest extends QueryToolChest, TopNQuery>
{
private static final byte TOPN_QUERY = 0x1;
-
private static final Joiner COMMA_JOIN = Joiner.on(",");
- private static final TypeReference> TYPE_REFERENCE = new TypeReference>(){};
-
- private static final TypeReference