- add sleep function for tool polling with rate limits
- Support base64 encoding for HTTP requests and uploads
- Enhance forum researcher with cost warnings and comprehensive planning
- Add cancellation support for research operations
- Include feature_name parameter for bot analytics
- richer research support (OR queries)
* FEATURE: add inferred concepts system
This commit adds a new inferred concepts system that:
- Creates a model for storing concept labels that can be applied to topics
- Provides AI personas for finding new concepts and matching existing ones
- Adds jobs for generating concepts from popular topics
- Includes a scheduled job that automatically processes engaging topics
* FEATURE: Extend inferred concepts to include posts
* Adds support for concepts to be inferred from and applied to posts
* Replaces daily task with one that handles both topics and posts
* Adds database migration for posts_inferred_concepts join table
* Updates PersonaContext to include inferred concepts
Co-authored-by: Roman Rizzi <rizziromanalejandro@gmail.com>
Co-authored-by: Keegan George <kgeorge13@gmail.com>
* FEATURE: support upload.getUrl in custom tools
Some tools need to share images with an API. A common pattern
is for APIs to expect a URL.
This allows converting upload://123123 to a proper CDN friendly
URL from within a custom tool
* no support for secure uploads, so be explicit about it.
Related: https://github.com/discourse/discourse-translator/pull/310
This commit includes all the jobs and event hooks to localize posts, topics, and categories.
A few notes:
- `feature_name: "translation"` because the site setting is `ai-translation` and module is `Translation`
- we will switch to proper ai-feature in the near future, and can consider using the persona_user as `localization.localizer_user_id`
- keeping things flat within the module for now as we will be moving to ai-feature soon and have to rearrange
- Settings renamed/introduced are:
- ai_translation_backfill_rate (0)
- ai_translation_backfill_limit_to_public_content (true)
- ai_translation_backfill_max_age_days (5)
- ai_translation_verbose_logs (false)
Since we enable/disable `ai_spam_detection_enabled` setting in a custom Spam tab UI in AI, we want to ensure we retain the setting and logging features. To preserve that, we want to update the controller to use `SiteSetting.set_and_log` instead of setting the value directly.
* FIX: Improve MessageBus efficiency and correctly stop streaming
This commit enhances the message bus implementation for AI helper streaming by:
- Adding client_id targeting for message bus publications to ensure only the requesting client receives streaming updates
- Limiting MessageBus backlog size (2) and age (60 seconds) to prevent Redis bloat
- Replacing clearTimeout with Ember's cancel method for proper runloop management, we were leaking a stop
- Adding tests for client-specific message delivery
These changes improve memory usage and make streaming more reliable by ensuring messages are properly directed to the requesting client.
* composer suggestion needed a fix as well.
* backlog size of 2 is risky here cause same channel name is reused between clients
Also allow artifact access to current username
Usage inside artifact is:
1. await window.discourseArtifactReady;
2. access data via window.discourseArtifactData;
AI share page assets are loaded via the app CDN, which means the requests have no authentication and will never appear to the app as "logged in". Therefore we should skip the `redirect_to_login_if_required` before_action.
This change fixes two bugs and adds a safeguard.
The first issue is that the schema Gemini expected differed from the one sent, resulting in 400 errors when performing completions.
The second issue was that creating a new persona won't define a method
for `response_format`. This has to be explicitly defined when we wrap it inside the Persona class. Also, There was a mismatch between the default value and what we stored in the DB. Some parts of the code expected symbols as keys and others as strings.
Finally, we add a safeguard when, even if asked to, the model refuses to reply with a valid JSON. In this case, we are making a best-effort to recover and stream the raw response.
Examples simulate previous interactions with an LLM and come
right after the system prompt. This helps grounding the model and
producing better responses.
* DEV: Use structured responses for summaries
* Fix system specs
* Make response_format a first class citizen and update endpoints to support it
* Response format can be specified in the persona
* lint
* switch to jsonb and make column nullable
* Reify structured output chunks. Move JSON parsing to the depths of Completion
* Switch to JsonStreamingTracker for partial JSON parsing
System personas leaned on reused classes, this was a problem
in a multisite environement cause state, such as "enabled"
ended up being reused between sites.
New implementation ensures state is pristine between sites in
a multisite
* more handling for new superclass story
* small oversight, display name should be used for display
Invalid access error should be populated to user when trying to search for something they do not have permissions for (i.e. anons searching `in:messages`
# Preview
https://github.com/user-attachments/assets/3fe3ac8f-c938-4df4-9afe-11980046944d
# Details
- Group pms by `last_posted_at`. In this first iteration we are group by `7 days`, `30 days`, then by month beyond that.
- I inject a sidebar section link with the relative (last_posted_at) date and then update a tracked value to ensure we don't do it again. Then for each month beyond the first 30days, I add a value to the `loadedMonthLabels` set and we reference that (plus the year) to see if we need to load a new month label.
- I took the creative liberty to remove the `Conversations` section label - this had no purpose
- I hid the _collapse all sidebar sections_ carrot. This had no purpose.
- Swap `BasicTopicSerializer` to `ListableTopicSerializer` to get access to `last_posted_at`
In the last commit, I introduced a topic_custom_field to determine if a PM is indeed a bot PM.
This commit adds a migration to backfill any PM that is between 1 real user, and 1 bot. The correct topic_custom_field is added for these, so they will appear on the bot conversation sidebar properly.
We can also drop the joining to topic_users in the controller for sidebar conversations, and the isPostFromAiBot logic from the sidebar.
Overview
This PR introduces a Bot Homepage that was first introduced at https://ask.discourse.org/.
Key Features:
Add a bot homepage: /discourse-ai/ai-bot/conversations
Display a sidebar with previous bot conversations
Infinite scroll for large counts
Sidebar still visible when navigation mode is header_dropdown
Sidebar visible on homepage and bot PM show view
Add New Question button to the bottom of sidebar on bot PM show view
Add persona picker to homepage
This update adds metrics for estimated spending in AI usage. To make use of it, admins must add cost details to the LLM config page (input, output, and cached input costs per 1M tokens). After doing so, the metrics will appear in the AI usage dashboard as the AI plugin is used.
### 🔍 Overview
This update performs some enhancements to the LLM configuration screen. In particular, it renames the UI for the number of tokens for the prompt to "Context window" since the naming can be confusing to the user. Additionally, it adds a new optional field called "Max output tokens".
In this feature update, we add the UI for the ability to easily configure persona backed AI-features. The feature will still be hidden until structured responses are complete.
* REFACTOR: Move personas into it's own module.
* WIP: Use personas for summarization
* Prioritize persona default LLM or fallback to newest one
* Simplify summarization strategy
* Keep ai_sumarization_model as a fallback
This feature update allows for continuing the conversation with Discobot Discoveries in an AI bot chat. After discoveries gives you a response to your search you can continue with the existing context.
This change moves all the personas code into its own module. We want to treat them as a building block features can built on top of, same as `Completions::Llm`.
The code to title a message was moved from `Bot` to `Playground`.
* DEV: refactor bot internals
This introduces a proper object for bot context, this makes
it simpler to improve context management as we go cause we
have a nice object to work with
Starts refactoring allowing for a single message to have
multiple uploads throughout
* transplant method to message builder
* chipping away at inline uploads
* image support is improved but not fully fixed yet
partially working in anthropic, still got quite a few dialects to go
* open ai and claude are now working
* Gemini is now working as well
* fix nova
* more dialects...
* fix ollama
* fix specs
* update artifact fixed
* more tests
* spam scanner
* pass more specs
* bunch of specs improved
* more bug fixes.
* all the rest of the tests are working
* improve tests coverage and ensure custom tools are aware of new context object
* tests are working, but we need more tests
* resolve merge conflict
* new preamble and expanded specs on ai tool
* remove concept of "standalone tools"
This is no longer needed, we can set custom raw, tool details are injected into tool calls
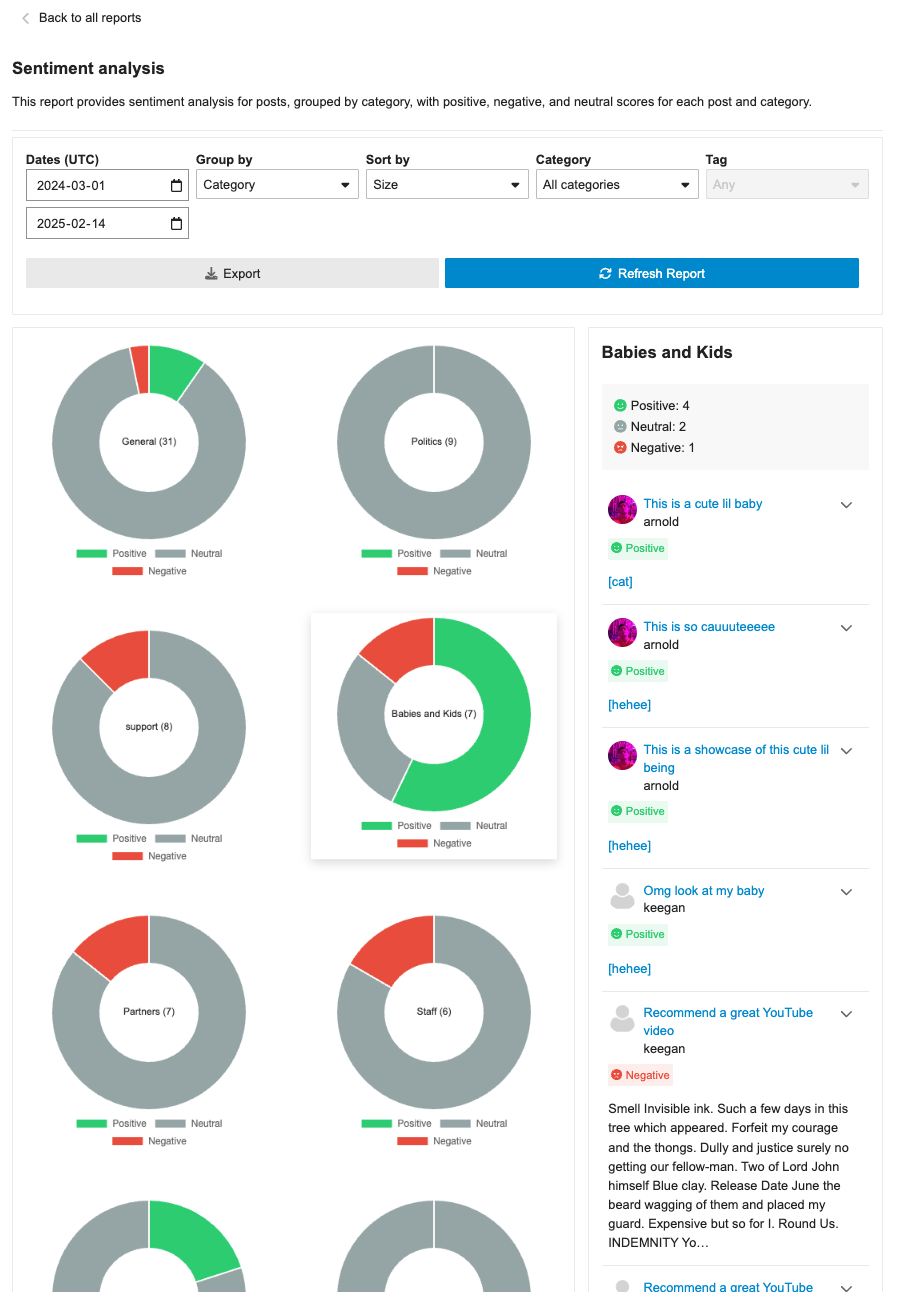
This PR ensures that the category badges are present in the sentiment analysis report. Since the core change in https://github.com/discourse/discourse/pull/31795, there was a regression in the post list drill-down where category badges were not being shown. This PR fixes that and also ensures icons/emojis are shown when categories make use of them. This PR also adds the category badge in the table list.
When editing a topic (instead of creating one) and using the
tag/category suggestion buttons. We want to use existing topic
embeddings instead of creating new ones.
thinking models such as Claude 3.7 Thinking and o1 / o3 do not
support top_p or temp.
Previously you would have to carefully remove it from everywhere
by having it be a provider param we now support blanker removing
without forcing people to update automation rules or personas
**This PR includes a variety of updates to the Sentiment Analysis report:**
- [X] Conditionally showing sentiment reports based on `sentiment_enabled` setting
- [X] Sentiment reports should only be visible in sidebar if data is in the reports
- [X] Fix infinite loading of posts in drill down
- [x] Fix markdown emojis showing not showing as emoji representation
- [x] Drill down of posts should have URL
- [x] ~~Different doughnut sizing based on post count~~ [reverting and will address in follow-up (see: `/t/146786/47`)]
- [X] Hide non-functional export button
- [X] Sticky drill down filter nav
This update improves some of the UI around sentiment analysis reports:
1. Improve titles so it is above and truncated when long
2. Change doughnut to only show total count
3. Ensures sentiment posts have dates
4. Ensure expand post doesn't appear on short posts
* FEATURE: full support for Sonnet 3.7
- Adds support for Sonnet 3.7 with reasoning on bedrock and anthropic
- Fixes regression where provider params were not populated
Note. reasoning tokens are hardcoded to minimum of 100 maximum of 65536
* FIX: open ai non reasoning models need to use deprecate max_tokens
* FEATURE: Experimental search results from an AI Persona.
When a user searches discourse, we'll send the query to an AI Persona to provide additional context and enrich the results. The feature depends on the user being a member of a group to which the persona has access.
* Update assets/stylesheets/common/ai-blinking-animation.scss
Co-authored-by: Keegan George <kgeorge13@gmail.com>
---------
Co-authored-by: Keegan George <kgeorge13@gmail.com>
## 🔍 Overview
This update adds a new report page at `admin/reports/sentiment_analysis` where admins can see a sentiment analysis report for the forum grouped by either category or tags.
## ➕ More details
The report can breakdown either category or tags into positive/negative/neutral sentiments based on the grouping (category/tag). Clicking on the doughnut visualization will bring up a post list of all the posts that were involved in that classification with further sentiment classifications by post.
The report can additionally be sorted in alphabetical order or by size, as well as be filtered by either category/tag based on the grouping.
## 👨🏽💻 Technical Details
The new admin report is registered via the pluginAPi with `api.registerReportModeComponent` to register the custom sentiment doughnut report. However, when each doughnut visualization is clicked, a new endpoint found at: `/discourse-ai/sentiment/posts` is fetched to showcase posts classified by sentiments based on the respective params.
## 📸 Screenshots
- Add non-contiguous search/replace support using ... syntax
- Add judge support for evaluating LLM outputs with ratings
- Improve error handling and reporting in eval runner
- Add full section replacement support without search blocks
- Add fabricators and specs for artifact diffing
- Track failed searches to improve debugging
- Add JS syntax validation for artifact versions in eval system
- Update prompt documentation with clear guidelines
* improve eval output
* move error handling
* llm as a judge
* fix spec
* small note on evals
* FEATURE: Native PDF support
This amends it so we use PDF Reader gem to extract text from PDFs
* This means that our simple pdf eval passes at last
* fix spec
* skip test in CI
* test file support
* Update lib/utils/image_to_text.rb
Co-authored-by: Alan Guo Xiang Tan <gxtan1990@gmail.com>
* address pr comments
---------
Co-authored-by: Alan Guo Xiang Tan <gxtan1990@gmail.com>
This PR introduces several enhancements and refactorings to the AI Persona and RAG (Retrieval-Augmented Generation) functionalities within the discourse-ai plugin. Here's a breakdown of the changes:
**1. LLM Model Association for RAG and Personas:**
- **New Database Columns:** Adds `rag_llm_model_id` to both `ai_personas` and `ai_tools` tables. This allows specifying a dedicated LLM for RAG indexing, separate from the persona's primary LLM. Adds `default_llm_id` and `question_consolidator_llm_id` to `ai_personas`.
- **Migration:** Includes a migration (`20250210032345_migrate_persona_to_llm_model_id.rb`) to populate the new `default_llm_id` and `question_consolidator_llm_id` columns in `ai_personas` based on the existing `default_llm` and `question_consolidator_llm` string columns, and a post migration to remove the latter.
- **Model Changes:** The `AiPersona` and `AiTool` models now `belong_to` an `LlmModel` via `rag_llm_model_id`. The `LlmModel.proxy` method now accepts an `LlmModel` instance instead of just an identifier. `AiPersona` now has `default_llm_id` and `question_consolidator_llm_id` attributes.
- **UI Updates:** The AI Persona and AI Tool editors in the admin panel now allow selecting an LLM for RAG indexing (if PDF/image support is enabled). The RAG options component displays an LLM selector.
- **Serialization:** The serializers (`AiCustomToolSerializer`, `AiCustomToolListSerializer`, `LocalizedAiPersonaSerializer`) have been updated to include the new `rag_llm_model_id`, `default_llm_id` and `question_consolidator_llm_id` attributes.
**2. PDF and Image Support for RAG:**
- **Site Setting:** Introduces a new hidden site setting, `ai_rag_pdf_images_enabled`, to control whether PDF and image files can be indexed for RAG. This defaults to `false`.
- **File Upload Validation:** The `RagDocumentFragmentsController` now checks the `ai_rag_pdf_images_enabled` setting and allows PDF, PNG, JPG, and JPEG files if enabled. Error handling is included for cases where PDF/image indexing is attempted with the setting disabled.
- **PDF Processing:** Adds a new utility class, `DiscourseAi::Utils::PdfToImages`, which uses ImageMagick (`magick`) to convert PDF pages into individual PNG images. A maximum PDF size and conversion timeout are enforced.
- **Image Processing:** A new utility class, `DiscourseAi::Utils::ImageToText`, is included to handle OCR for the images and PDFs.
- **RAG Digestion Job:** The `DigestRagUpload` job now handles PDF and image uploads. It uses `PdfToImages` and `ImageToText` to extract text and create document fragments.
- **UI Updates:** The RAG uploader component now accepts PDF and image file types if `ai_rag_pdf_images_enabled` is true. The UI text is adjusted to indicate supported file types.
**3. Refactoring and Improvements:**
- **LLM Enumeration:** The `DiscourseAi::Configuration::LlmEnumerator` now provides a `values_for_serialization` method, which returns a simplified array of LLM data (id, name, vision_enabled) suitable for use in serializers. This avoids exposing unnecessary details to the frontend.
- **AI Helper:** The `AiHelper::Assistant` now takes optional `helper_llm` and `image_caption_llm` parameters in its constructor, allowing for greater flexibility.
- **Bot and Persona Updates:** Several updates were made across the codebase, changing the string based association to a LLM to the new model based.
- **Audit Logs:** The `DiscourseAi::Completions::Endpoints::Base` now formats raw request payloads as pretty JSON for easier auditing.
- **Eval Script:** An evaluation script is included.
**4. Testing:**
- The PR introduces a new eval system for LLMs, this allows us to test how functionality works across various LLM providers. This lives in `/evals`
When you already have embeddings for a model stored and change models,
our backfill script was failing to backfill the newly configured model.
Regression introduced most likely in 1686a8a
Currently in core re-flagging something that is already flagged as spam
is not supported, long term we may want to support this but in the meantime
we should not be silencing/hiding if the PostActionCreator fails
when flagging things as spam.
---------
Co-authored-by: Ted Johansson <drenmi@gmail.com>
* FEATURE: Tool name validation
- Add unique index to the name column of the ai_tools table
- correct our tests for AiToolController
- tool_name field which will be used to represent to LLM
- Add tool_name to Tools's presets
- Add duplicate tools validation for AiPersona
- Add unique constraint to the name column of the ai_tools table
* DEV: Validate duplicate tool_name between builin tools and custom tools
* lint
* chore: fix linting
* fix conlict mistakes
* chore: correct icon class
* chore: fix failed specs
* Add max_length to tool_name
* chore: correct the option name
* lintings
* fix lintings
Before this change, a summary was only outdated when new content appeared, for topics with "best replies", when the query returned different results. The intent behind this change is to detect when a summary is outdated as a result of an edit.
Additionally, we are changing the backfill candidates query to compare "ai_summary_backfill_topic_max_age_days" against "last_posted_at" instead of "created_at", to catch long-lived, active topics. This was discussed here: https://meta.discourse.org/t/ai-summarization-backfill-is-stuck-keeps-regenerating-the-same-topic/347088/14?u=roman_rizzi