This PR enhances the LLM triage automation with several important improvements:
- Add ability to use AI personas for automated replies instead of canned replies
- Add support for whisper responses
- Refactor LLM persona reply functionality into a reusable method
- Add new settings to configure response behavior in automations
- Improve error handling and logging
- Fix handling of personal messages in the triage flow
- Add comprehensive test coverage for new features
- Make personas configurable with more flexible requirements
This allows for more dynamic and context-aware responses in automated workflows, with better control over visibility and attribution.
## LLM Persona Triage
- Allows automated responses to posts using AI personas
- Configurable to respond as regular posts or whispers
- Adds context-aware formatting for topics and private messages
- Provides special handling for topic metadata (title, category, tags)
## LLM Tool Triage
- Enables custom AI tools to process and respond to posts
- Tools can analyze post content and invoke personas when needed
- Zero-parameter tools can be used for automated workflows
- Not enabled in production yet
## Implementation Details
- Added new scriptable registration in discourse_automation/ directory
- Created core implementation in lib/automation/ modules
- Enhanced PromptMessagesBuilder with topic-style formatting
- Added helper methods for persona and tool selection in UI
- Extended AI Bot functionality to support whisper responses
- Added rate limiting to prevent abuse
## Other Changes
- Added comprehensive test coverage for both automation types
- Enhanced tool runner with LLM integration capabilities
- Improved error handling and logging
This feature allows forum admins to configure AI personas to automatically respond to posts based on custom criteria and leverage AI tools for more complex triage workflows.
Tool Triage has been disabled in production while we finalize details of new scripting capabilities.
adds support for "thinking tokens" - a feature that exposes the model's reasoning process before providing the final response. Key improvements include:
- Add a new Thinking class to handle thinking content from LLMs
- Modify endpoints (Claude, AWS Bedrock) to handle thinking output
- Update AI bot to display thinking in collapsible details section
- Fix SEARCH/REPLACE blocks to support empty replacement strings and general improvements to artifact editing
- Allow configurable temperature in triage and report automations
- Various bug fixes and improvements to diff parsing
* FEATURE: full support for Sonnet 3.7
- Adds support for Sonnet 3.7 with reasoning on bedrock and anthropic
- Fixes regression where provider params were not populated
Note. reasoning tokens are hardcoded to minimum of 100 maximum of 65536
* FIX: open ai non reasoning models need to use deprecate max_tokens
* FIX: legacy reasoning models not working, missing provider params
1. Legacy reasoning models (o1-preview / o1-mini) do not support developer or system messages, do not use them.
2. LLM editor form not showing all provider params due to missing remap
* add system test
* FEATURE: Experimental search results from an AI Persona.
When a user searches discourse, we'll send the query to an AI Persona to provide additional context and enrich the results. The feature depends on the user being a member of a group to which the persona has access.
* Update assets/stylesheets/common/ai-blinking-animation.scss
Co-authored-by: Keegan George <kgeorge13@gmail.com>
---------
Co-authored-by: Keegan George <kgeorge13@gmail.com>
## 🔍 Overview
This update adds a new report page at `admin/reports/sentiment_analysis` where admins can see a sentiment analysis report for the forum grouped by either category or tags.
## ➕ More details
The report can breakdown either category or tags into positive/negative/neutral sentiments based on the grouping (category/tag). Clicking on the doughnut visualization will bring up a post list of all the posts that were involved in that classification with further sentiment classifications by post.
The report can additionally be sorted in alphabetical order or by size, as well as be filtered by either category/tag based on the grouping.
## 👨🏽💻 Technical Details
The new admin report is registered via the pluginAPi with `api.registerReportModeComponent` to register the custom sentiment doughnut report. However, when each doughnut visualization is clicked, a new endpoint found at: `/discourse-ai/sentiment/posts` is fetched to showcase posts classified by sentiments based on the respective params.
## 📸 Screenshots
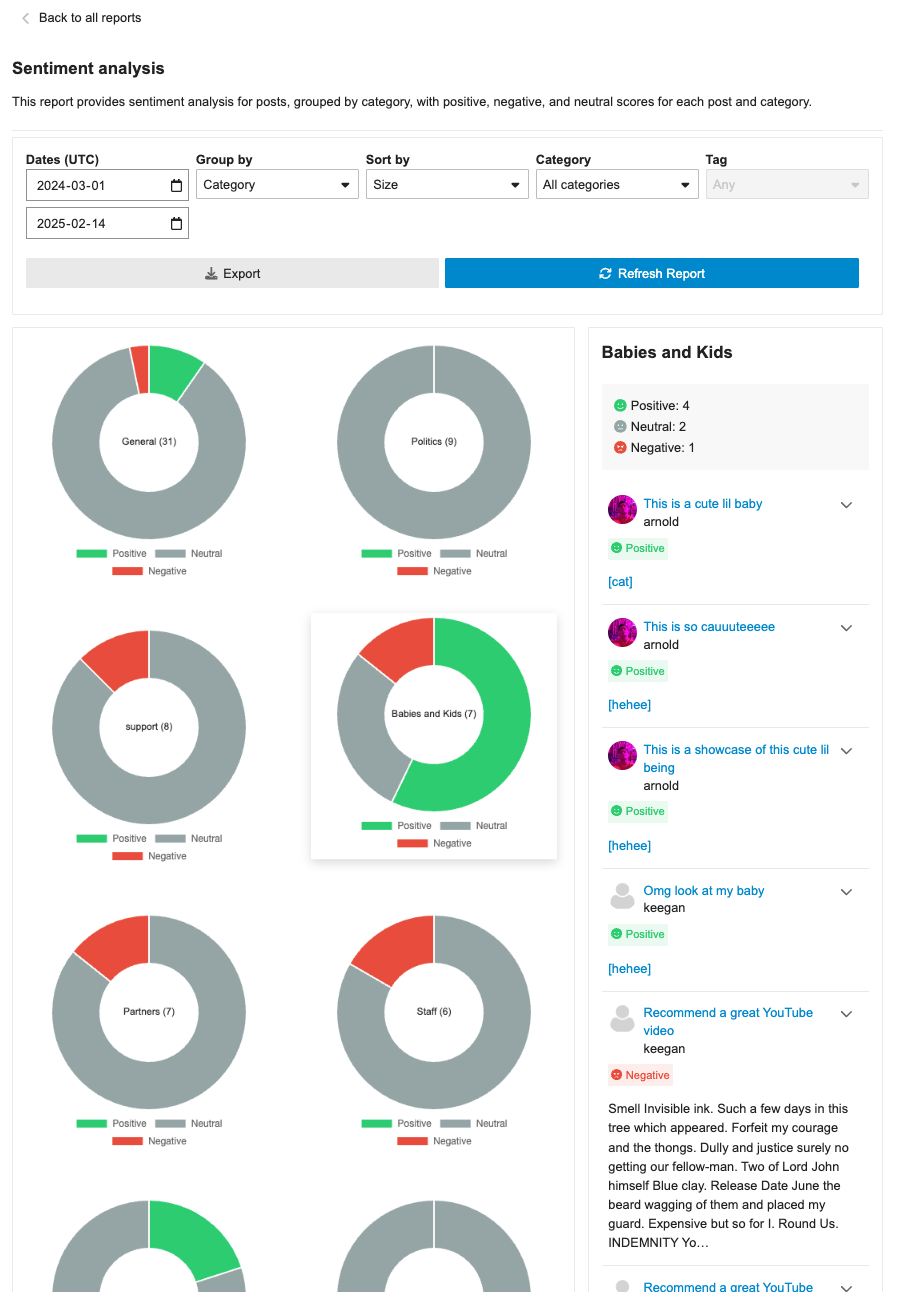
From [pgvector/pgvector](https://github.com/pgvector/pgvector) README
> With approximate indexes, filtering is applied after the index is scanned. If a condition matches 10% of rows, with HNSW and the default hnsw.ef_search of 40, only 4 rows will match on average. For more rows, increase hnsw.ef_search.
>
> Starting with 0.8.0, you can enable [iterative index scans](https://github.com/pgvector/pgvector#iterative-index-scans), which will automatically scan more of the index when needed.
Since we are stuck on 0.7.0 we are going the first option for now.
- Add non-contiguous search/replace support using ... syntax
- Add judge support for evaluating LLM outputs with ratings
- Improve error handling and reporting in eval runner
- Add full section replacement support without search blocks
- Add fabricators and specs for artifact diffing
- Track failed searches to improve debugging
- Add JS syntax validation for artifact versions in eval system
- Update prompt documentation with clear guidelines
* improve eval output
* move error handling
* llm as a judge
* fix spec
* small note on evals
* FEATURE: Native PDF support
This amends it so we use PDF Reader gem to extract text from PDFs
* This means that our simple pdf eval passes at last
* fix spec
* skip test in CI
* test file support
* Update lib/utils/image_to_text.rb
Co-authored-by: Alan Guo Xiang Tan <gxtan1990@gmail.com>
* address pr comments
---------
Co-authored-by: Alan Guo Xiang Tan <gxtan1990@gmail.com>
This PR introduces several enhancements and refactorings to the AI Persona and RAG (Retrieval-Augmented Generation) functionalities within the discourse-ai plugin. Here's a breakdown of the changes:
**1. LLM Model Association for RAG and Personas:**
- **New Database Columns:** Adds `rag_llm_model_id` to both `ai_personas` and `ai_tools` tables. This allows specifying a dedicated LLM for RAG indexing, separate from the persona's primary LLM. Adds `default_llm_id` and `question_consolidator_llm_id` to `ai_personas`.
- **Migration:** Includes a migration (`20250210032345_migrate_persona_to_llm_model_id.rb`) to populate the new `default_llm_id` and `question_consolidator_llm_id` columns in `ai_personas` based on the existing `default_llm` and `question_consolidator_llm` string columns, and a post migration to remove the latter.
- **Model Changes:** The `AiPersona` and `AiTool` models now `belong_to` an `LlmModel` via `rag_llm_model_id`. The `LlmModel.proxy` method now accepts an `LlmModel` instance instead of just an identifier. `AiPersona` now has `default_llm_id` and `question_consolidator_llm_id` attributes.
- **UI Updates:** The AI Persona and AI Tool editors in the admin panel now allow selecting an LLM for RAG indexing (if PDF/image support is enabled). The RAG options component displays an LLM selector.
- **Serialization:** The serializers (`AiCustomToolSerializer`, `AiCustomToolListSerializer`, `LocalizedAiPersonaSerializer`) have been updated to include the new `rag_llm_model_id`, `default_llm_id` and `question_consolidator_llm_id` attributes.
**2. PDF and Image Support for RAG:**
- **Site Setting:** Introduces a new hidden site setting, `ai_rag_pdf_images_enabled`, to control whether PDF and image files can be indexed for RAG. This defaults to `false`.
- **File Upload Validation:** The `RagDocumentFragmentsController` now checks the `ai_rag_pdf_images_enabled` setting and allows PDF, PNG, JPG, and JPEG files if enabled. Error handling is included for cases where PDF/image indexing is attempted with the setting disabled.
- **PDF Processing:** Adds a new utility class, `DiscourseAi::Utils::PdfToImages`, which uses ImageMagick (`magick`) to convert PDF pages into individual PNG images. A maximum PDF size and conversion timeout are enforced.
- **Image Processing:** A new utility class, `DiscourseAi::Utils::ImageToText`, is included to handle OCR for the images and PDFs.
- **RAG Digestion Job:** The `DigestRagUpload` job now handles PDF and image uploads. It uses `PdfToImages` and `ImageToText` to extract text and create document fragments.
- **UI Updates:** The RAG uploader component now accepts PDF and image file types if `ai_rag_pdf_images_enabled` is true. The UI text is adjusted to indicate supported file types.
**3. Refactoring and Improvements:**
- **LLM Enumeration:** The `DiscourseAi::Configuration::LlmEnumerator` now provides a `values_for_serialization` method, which returns a simplified array of LLM data (id, name, vision_enabled) suitable for use in serializers. This avoids exposing unnecessary details to the frontend.
- **AI Helper:** The `AiHelper::Assistant` now takes optional `helper_llm` and `image_caption_llm` parameters in its constructor, allowing for greater flexibility.
- **Bot and Persona Updates:** Several updates were made across the codebase, changing the string based association to a LLM to the new model based.
- **Audit Logs:** The `DiscourseAi::Completions::Endpoints::Base` now formats raw request payloads as pretty JSON for easier auditing.
- **Eval Script:** An evaluation script is included.
**4. Testing:**
- The PR introduces a new eval system for LLMs, this allows us to test how functionality works across various LLM providers. This lives in `/evals`
Prior to this commit, editing the provider wouldn't recompute the provider params. It would also not correctly recompute the "canEditURL" property.
To make possible this commit has:
- made a fix in core: https://github.com/discourse/discourse/pull/31329
- ensures the provider params are recomputed when provider is changed
- made the check on `canEditURL` based on form state and not initial model value
Tests have been added to confirm the expected behavior.
Currently in core re-flagging something that is already flagged as spam
is not supported, long term we may want to support this but in the meantime
we should not be silencing/hiding if the PostActionCreator fails
when flagging things as spam.
---------
Co-authored-by: Ted Johansson <drenmi@gmail.com>
* FEATURE: Tool name validation
- Add unique index to the name column of the ai_tools table
- correct our tests for AiToolController
- tool_name field which will be used to represent to LLM
- Add tool_name to Tools's presets
- Add duplicate tools validation for AiPersona
- Add unique constraint to the name column of the ai_tools table
* DEV: Validate duplicate tool_name between builin tools and custom tools
* lint
* chore: fix linting
* fix conlict mistakes
* chore: correct icon class
* chore: fix failed specs
* Add max_length to tool_name
* chore: correct the option name
* lintings
* fix lintings
Before this change, a summary was only outdated when new content appeared, for topics with "best replies", when the query returned different results. The intent behind this change is to detect when a summary is outdated as a result of an edit.
Additionally, we are changing the backfill candidates query to compare "ai_summary_backfill_topic_max_age_days" against "last_posted_at" instead of "created_at", to catch long-lived, active topics. This was discussed here: https://meta.discourse.org/t/ai-summarization-backfill-is-stuck-keeps-regenerating-the-same-topic/347088/14?u=roman_rizzi
### Why
This pull request fundamentally restructures how AI bots create and update web artifacts to address critical limitations in the previous approach:
1. **Improved Artifact Context for LLMs**: Previously, artifact creation and update tools included the *entire* artifact source code directly in the tool arguments. This overloaded the Language Model (LLM) with raw code, making it difficult for the LLM to maintain a clear understanding of the artifact's current state when applying changes. The LLM would struggle to differentiate between the base artifact and the requested modifications, leading to confusion and less effective updates.
2. **Reduced Token Usage and History Bloat**: Including the full artifact source code in every tool interaction was extremely token-inefficient. As conversations progressed, this redundant code in the history consumed a significant number of tokens unnecessarily. This not only increased costs but also diluted the context for the LLM with less relevant historical information.
3. **Enabling Updates for Large Artifacts**: The lack of a practical diff or targeted update mechanism made it nearly impossible to efficiently update larger web artifacts. Sending the entire source code for every minor change was both computationally expensive and prone to errors, effectively blocking the use of AI bots for meaningful modifications of complex artifacts.
**This pull request addresses these core issues by**:
* Introducing methods for the AI bot to explicitly *read* and understand the current state of an artifact.
* Implementing efficient update strategies that send *targeted* changes rather than the entire artifact source code.
* Providing options to control the level of artifact context included in LLM prompts, optimizing token usage.
### What
The main changes implemented in this PR to resolve the above issues are:
1. **`Read Artifact` Tool for Contextual Awareness**:
- A new `read_artifact` tool is introduced, enabling AI bots to fetch and process the current content of a web artifact from a given URL (local or external).
- This provides the LLM with a clear and up-to-date representation of the artifact's HTML, CSS, and JavaScript, improving its understanding of the base to be modified.
- By cloning local artifacts, it allows the bot to work with a fresh copy, further enhancing context and control.
2. **Refactored `Update Artifact` Tool with Efficient Strategies**:
- The `update_artifact` tool is redesigned to employ more efficient update strategies, minimizing token usage and improving update precision:
- **`diff` strategy**: Utilizes a search-and-replace diff algorithm to apply only the necessary, targeted changes to the artifact's code. This significantly reduces the amount of code sent to the LLM and focuses its attention on the specific modifications.
- **`full` strategy**: Provides the option to replace the entire content sections (HTML, CSS, JavaScript) when a complete rewrite is required.
- Tool options enhance the control over the update process:
- `editor_llm`: Allows selection of a specific LLM for artifact updates, potentially optimizing for code editing tasks.
- `update_algorithm`: Enables choosing between `diff` and `full` update strategies based on the nature of the required changes.
- `do_not_echo_artifact`: Defaults to true, and by *not* echoing the artifact in prompts, it further reduces token consumption in scenarios where the LLM might not need the full artifact context for every update step (though effectiveness might be slightly reduced in certain update scenarios).
3. **System and General Persona Tool Option Visibility and Customization**:
- Tool options, including those for system personas, are made visible and editable in the admin UI. This allows administrators to fine-tune the behavior of all personas and their tools, including setting specific LLMs or update algorithms. This was previously limited or hidden for system personas.
4. **Centralized and Improved Content Security Policy (CSP) Management**:
- The CSP for AI artifacts is consolidated and made more maintainable through the `ALLOWED_CDN_SOURCES` constant. This improves code organization and future updates to the allowed CDN list, while maintaining the existing security posture.
5. **Codebase Improvements**:
- Refactoring of diff utilities, introduction of strategy classes, enhanced error handling, new locales, and comprehensive testing all contribute to a more robust, efficient, and maintainable artifact management system.
By addressing the issues of LLM context confusion, token inefficiency, and the limitations of updating large artifacts, this pull request significantly improves the practicality and effectiveness of AI bots in managing web artifacts within Discourse.
Before this change, we let you set the embeddings selected model back to " " even with embeddings enabled. This will leave the site in a broken state.
Additionally, it adds a fail-safe for these scenarios to avoid errors on the topics page.
This change fixes two different problems.
First, we add a data migration to migrate the configuration of sites using Open AI's embedding model. There was a window between the embedding config changes and #1087, where sites could end up in a broken state due to an unconfigured selected model setting, as reported on https://meta.discourse.org/t/-/348964
The second fix drops pre-seeded search indexes of the models we didn't migrate and corrects the ones where the dimensions don't match. Since the index uses the model ID, new embedding configs could use one of these ones even when the dimensions no longer match.
We have a flag to signal we are shortening the embeddings of a model.
Only used in Open AI's text-embedding-3-*, but we plan to use it for other services.
* Use AR model for embeddings features
* endpoints
* Embeddings CRUD UI
* Add presets. Hide a couple more settings
* system specs
* Seed embedding definition from old settings
* Generate search bit index on the fly. cleanup orphaned data
* support for seeded models
* Fix run test for new embedding
* fix selected model not set correctly
This adds registration and last known IP information and email to scanning context.
This provides another hint for spam scanner about possible malicious users.
For example registered in India, replying from Australia or
email is clearly a throwaway email address.
To quickly select backfill candidates without comparing SHAs, we compare the last summarized post to the topic's highest_post_number. However, hiding or deleting a post and adding a small action will update this column, causing the job to stall and re-generate the same summary repeatedly until someone posts a regular reply. On top of this, this is not always true for topics with `best_replies`, as this last reply isn't necessarily included.
Since this is not evident at first glance and each summarization strategy picks its targets differently, I'm opting to simplify the backfill logic and how we track potential candidates.
The first step is dropping `content_range`, which serves no purpose and it's there because summary caching was supposed to work differently at the beginning. So instead, I'm replacing it with a column called `highest_target_number`, which tracks `highest_post_number` for topics and could track other things like channel's `message_count` in the future.
Now that we have this column when selecting every potential backfill candidate, we'll check if the summary is truly outdated by comparing the SHAs, and if it's not, we just update the column and move on
When enabling spam scanner it there may be old unscanned posts
this can create a risky situation where spam scanner operates
on legit posts during false positives
To keep this a lot safer we no longer try to hide old stuff by
the spammers.
Adds a comprehensive quota management system for LLM models that allows:
- Setting per-group (applied per user in the group) token and usage limits with configurable durations
- Tracking and enforcing token/usage limits across user groups
- Quota reset periods (hourly, daily, weekly, or custom)
- Admin UI for managing quotas with real-time updates
This system provides granular control over LLM API usage by allowing admins
to define limits on both total tokens and number of requests per group.
Supports multiple concurrent quotas per model and automatically handles
quota resets.
Co-authored-by: Keegan George <kgeorge13@gmail.com>
Disabling streaming is required for models such o1 that do not have streaming
enabled yet
It is good to carry this feature around in case various apis decide not to support streaming endpoints and Discourse AI can continue to work just as it did before.
Also: fixes issue where sharing artifacts would miss viewport leading to tiny artifacts on mobile
This update adds some structure for handling errors in the spam config while also handling a specific error related to the spam scanning user not being an admin account.
The seeded LLM setting: `SiteSetting.ai_spam_detection_model_allowed_seeded_models` returns a _string_ with IDs separated by pipes. running `_map` on it will return an array with strings. We were previously checking for the id with custom prefix identifier, but instead we should be checking the stringified ID.
* FEATURE: smart date support for AI helper
This feature allows conversion of human typed in dates and times
to smart "Discourse" timezone friendly dates.
* fix specs and lint
* lint
* address feedback
* add specs
This PR fixes an issue where LLM enumerator would error out when `SiteSetting.ai_spam_detection = true` but there was no `AiModerationSetting.spam` present.
Typically, we add an `LlmDependencyValidator` for the setting itself, however, since Spam is unique in that it has it's model set in `AiModerationSetting` instead of a `SiteSetting`, we'll add a simple check here to prevent erroring out.