* feat: integrate long-term memory system into SRE agent - Add AgentCore Memory integration with three memory strategies: * User preferences (escalation, notification, workflow preferences) * Infrastructure knowledge (dependencies, patterns, baselines) * Investigation summaries (timeline, actions, findings) - Implement memory tools for save/retrieve operations - Add automatic memory capture through hooks and pattern recognition - Extend agent state to support memory context - Integrate memory-aware planning in supervisor agent - Add comprehensive test coverage for memory functionality - Create detailed documentation with usage examples This transforms the SRE agent from stateless to learning assistant that becomes more valuable over time by remembering user preferences, infrastructure patterns, and investigation outcomes. Addresses issue #164 * feat: environment variable config, agent routing fixes, and project organization - Move USER_ID/SESSION_ID from metadata parsing to environment variables - Add .memory_id to .gitignore for local memory state - Update .gitignore to use .scratchpad/ folder instead of .scratchpad.md - Fix agent routing issues with supervisor prompt and graph node naming - Add conversation memory tracking for all agents and supervisor - Improve agent metadata system with centralized constants - Add comprehensive logging and debugging for agent tool access - Update deployment script to pass user_id/session_id in payload - Create .scratchpad/ folder structure for better project organization * feat: enhance SRE agent with automatic report archiving and error fixes - Add automatic archiving system for reports by date - Include user_id in report filenames for better organization - Fix Pydantic validation error with string-to-list conversion for investigation steps - Add content length truncation for memory storage to prevent validation errors - Remove status line from report output for cleaner formatting - Implement date-based folder organization (YYYY-MM-DD format) - Add memory content length limits configuration in constants Key improvements: - Reports now auto-archive old files when saving new ones - User-specific filenames: query_user_id_UserName_YYYYMMDD_HHMMSS.md - Robust error handling for memory content length limits - Backward compatibility with existing filename formats * feat: fix memory retrieval system for cross-session searches and user personalization Key fixes and improvements: - Fix case preservation in actor_id sanitization (Carol remains Carol, not carol) - Enable cross-session memory searches for infrastructure and investigation memories - Add XML parsing support for investigation summaries stored in XML format - Enhance user preference integration throughout the system - Add comprehensive debug logging for memory retrieval processes - Update prompts to support user-specific communication styles and preferences Memory system now properly: - Preserves user case in memory namespaces (/sre/users/Carol vs /sre/users/carol) - Searches across all sessions for planning context vs session-specific for current state - Parses both JSON and XML formatted investigation memories - Adapts investigation approach based on user preferences and historical patterns - Provides context-aware planning using infrastructure knowledge and past investigations * feat: enhance SRE agent with user-specific memory isolation and anti-hallucination measures Memory System Improvements: - Fix memory isolation to retrieve only user-specific memories (Alice doesn't see Carol's data) - Implement proper namespace handling for cross-session vs session-specific searches - Add detailed logging for memory retrieval debugging and verification - Remove verbose success logs, keep only error logs for cleaner output Anti-Hallucination Enhancements: - Add tool output validation requirements to agent prompts - Implement timestamp fabrication prevention (use 2024-* format from backend) - Require tool attribution for all metrics and findings in reports - Add backend data alignment patterns for consistent data references - Update supervisor aggregation prompts to flag unverified claims Code Organization: - Extract hardcoded prompts from supervisor.py to external prompt files - Add missing session_id parameters to SaveInfrastructureTool and SaveInvestigationTool - Improve memory client namespace documentation and cross-session search logic - Reduce debug logging noise while maintaining error tracking Verification Complete: - Memory isolation working correctly (only user-specific data retrieval) - Cross-session memory usage properly configured for planning and investigations - Memory integration confirmed in report generation pipeline - Anti-hallucination measures prevent fabricated metrics and timestamps * feat: organize utility scripts in dedicated scripts folder Script Organization: - Move manage_memories.py to scripts/ folder with updated import paths - Move configure_gateway.sh to scripts/ folder with corrected PROJECT_ROOT path - Copy user_config.yaml to scripts/ folder for self-contained script usage Path Fixes: - Update manage_memories.py to import sre_agent module from correct relative path - Fix .memory_id file path resolution for new script location - Update configure_gateway.sh PROJECT_ROOT to point to correct parent directory - Add fallback logic to find user_config.yaml in scripts/ or project root Script Improvements: - Update help text and examples to use 'uv run python scripts/' syntax - Make manage_memories.py executable with proper permissions - Maintain backward compatibility for custom config file paths - Self-contained scripts folder with all required dependencies Verification: - All scripts work correctly from new location - Memory management functions operate properly - Gateway configuration handles paths correctly - User preferences loading works from scripts directory * docs: update SSL certificate paths to use /opt/ssl standard location - Update README.md to reference /opt/ssl for SSL certificate paths - Update docs/demo-environment.md to use /opt/ssl paths - Clean up scripts/configure_gateway.sh SSL fallback paths - Remove duplicate and outdated SSL path references - Establish /opt/ssl as the standard SSL certificate location This ensures consistent SSL certificate management across all documentation and scripts, supporting the established /opt/ssl directory with proper ubuntu:ubuntu ownership. * feat: enhance memory system with infrastructure parsing fix and user personalization analysis Infrastructure Memory Parsing Improvements: - Fix infrastructure memory parsing to handle both JSON and plain text formats - Convert plain text memories to structured InfrastructureKnowledge objects - Change warning logs to debug level for normal text-to-structure conversion - Ensure all infrastructure memories are now retrievable and usable User Personalization Documentation: - Add comprehensive memory system analysis comparing Alice vs Carol reports - Create docs/examples/ folder with real investigation reports demonstrating personalization - Document side-by-side communication differences based on user preferences - Show how same technical incident produces different reports for different user roles Example Reports Added: - Alice's technical detailed investigation report (technical role preferences) - Carol's business-focused executive summary report (executive role preferences) - Memory system analysis with extensive side-by-side comparisons This demonstrates the memory system's ability to: - Maintain technical accuracy while adapting presentation style - Apply user-specific escalation procedures and communication channels - Build institutional knowledge about recurring infrastructure patterns - Personalize identical technical incidents for different organizational roles * feat: enhance memory system with automatic pattern extraction and improved logging ## Memory System Enhancements - **Individual agent memory integration**: Every agent response now triggers automatic memory pattern extraction through on_agent_response() hooks - **Enhanced conversation logging**: Added detailed message breakdown showing USER/ASSISTANT/TOOL message counts and tool names called - **Fixed infrastructure extraction**: Resolved hardcoded agent name issues by using SREConstants for agent identification - **Comprehensive memory persistence**: All agent responses and tool executions stored as conversation memory with proper session tracking ## Tool Architecture Clarification - **Centralized memory access**: Confirmed only supervisor agent has direct access to memory tools (retrieve_memory, save_*) - **Individual agent focus**: Individual agents have NO memory tools, only domain-specific tools (5 tools each for metrics, logs, k8s, runbooks) - **Automatic pattern recognition**: Memory capture happens automatically through hooks, not manual tool calls by individual agents ## Documentation Updates - **Updated memory-system.md**: Comprehensive design documentation reflecting current implementation - **Added example analyses**: Created flight-booking-analysis.md and api-response-time-analysis.md in docs/examples/ - **Enhanced README.md**: Added memory system overview and personalized investigation examples - **Updated .gitignore**: Now ignores entire reports/ folder instead of just .md files ## Implementation Improvements - **Event ID tracking**: All memory operations generate and log event IDs for verification - **Pattern extraction confirmation**: Logs confirm pattern extraction working for all agent types - **Memory save verification**: Comprehensive logging shows successful saves across all memory types - **Script enhancements**: manage_memories.py now handles duplicate removal and improved user management * docs: enhance memory system documentation with planning agent memory usage examples - Add real agent.log snippets showing planning agent retrieving and using memory context - Document XML-structured prompts for improved Claude model interaction - Explain JSON response format enforcement and infrastructure knowledge extraction - Add comprehensive logging and monitoring details - Document actor ID design for proper memory namespace isolation - Fix ASCII flow diagram alignment for better readability - Remove temporal framing and present features as current design facts * docs: add AWS documentation links and clean up memory system documentation - Add hyperlink to Amazon Bedrock AgentCore Memory main documentation - Link to Memory Getting Started Guide for the three memory strategies - Remove Legacy Pattern Recognition section from documentation (code remains) - Remove Error Handling and Fallbacks section to focus on core functionality - Keep implementation details in code while streamlining public documentation * docs: reorganize memory-system.md to eliminate redundancies - Merged Memory Tool Architecture and Planning sections into unified section - Consolidated all namespace/actor_id explanations in architecture section - Combined pattern recognition and memory capture content - Created dedicated Agent Memory Integration section with examples - Removed ~15-20% redundant content while improving clarity - Improved document structure for better navigation * style: apply ruff formatting and fix code style issues - Applied ruff auto-formatting to all Python files - Fixed 383 style issues automatically - Remaining issues require manual intervention: - 29 ruff errors (bare except, unused variables, etc.) - 61 mypy type errors (missing annotations, implicit Optional) - Verified memory system functionality matches documentation - Confirmed user personalization working correctly in reports * docs: make benefits section more succinct in memory-system.md - Consolidated 12 bullet points into 5 focused benefits - Removed redundant three-category structure (Users/Teams/Operations) - Maintained all key value propositions while improving readability - Reduced section length by ~60% while preserving essential information * feat: add comprehensive cleanup script with memory deletion - Added cleanup.sh script to delete all AWS resources (gateway, runtime, memory) - Integrated memory deletion using bedrock_agentcore MemoryClient - Added proper error handling and graceful fallbacks - Updated execution order: servers → gateway → memory → runtime → local files - Added memory deletion to README.md cleanup instructions - Includes confirmation prompts and --force option for automation * fix: preserve .env, .venv, and reports in cleanup script - Modified cleanup script to only remove AWS-generated configuration files - Preserved .env files for development continuity - Preserved .venv directories to avoid reinstalling dependencies - Preserved reports/ directory containing investigation history - Files removed: gateway URIs, tokens, agent ARNs, memory IDs only - Updated documentation to clarify preserved vs removed files * fix: use correct bedrock-agentcore-control client for gateway operations - Changed boto3 client from 'bedrock-agentcore' to 'bedrock-agentcore-control' - Fixes 'list_gateways' method not found error during gateway deletion - Both gateway and runtime deletion now use the correct control plane client * docs: add memory system initialization timing guidance - Added note that memory system takes 10-12 minutes to be ready - Added steps to check memory status with list command after 10 minutes - Added instruction to run update command again once memory is ready - Provides clear workflow for memory system setup and prevents user confusion * docs: comprehensive documentation update and cleanup - Remove unused root .env and .env.example files (not referenced by any code) - Update configuration.md with comprehensive config file documentation - Add configuration overview table with setup instructions and auto-generation info - Consolidate specialized-agents.md content into system-components.md - Update system-components.md with complete AgentCore architecture - Add detailed sections for AgentCore Runtime, Gateway, and Memory primitives - Remove cli-reference.md (excessive documentation for limited use) - Update README.md to reference configuration guide in setup section - Clean up documentation links and organization The documentation now provides a clear, consolidated view of the system architecture and configuration with proper cross-references and setup guidance. * feat: improve runtime deployment and invocation robustness - Increase deletion wait time to 150s for agent runtime cleanup - Add retry logic with exponential backoff for MCP rate limiting (429 errors) - Add session_id and user_id to agent state for memory retrieval - Filter out /ping endpoint logs to reduce noise - Increase boto3 read timeout to 5 minutes for long-running operations - Add clear error messages for agent name conflicts - Update README to clarify virtual environment requirement for scripts - Fix session ID generation to meet 33+ character requirement These changes improve reliability when deploying and invoking agents, especially under heavy load or with complex queries that take time. * chore: remove accidentally committed reports folder Removed 130+ markdown report files from the reports/ directory that were accidentally committed. The .gitignore already includes reports/ to prevent future commits of these generated files.
SRE Agent - Multi-Agent Site Reliability Engineering Assistant
Overview
The SRE Agent is a multi-agent system for Site Reliability Engineers that helps investigate infrastructure issues. Built on the Model Context Protocol (MCP) and powered by Amazon Nova and Anthropic Claude models (Claude can be accessed through Amazon Bedrock or directly through Anthropic), this system uses specialized AI agents that collaborate to investigate issues, analyze logs, monitor performance metrics, and execute operational procedures. The AgentCore Gateway provides access to data sources and systems available as MCP tools. This example also demonstrates how to deploy the agent using the Amazon Bedrock AgentCore Runtime for production environments.
Use case details
| Information | Details |
|---|---|
| Use case type | conversational |
| Agent type | Multi-agent |
| Use case components | Tools (MCP-based), observability (logs, metrics), operational runbooks |
| Use case vertical | DevOps/SRE |
| Example complexity | Advanced |
| SDK used | Amazon Bedrock AgentCore SDK, LangGraph, MCP |
Use case Architecture
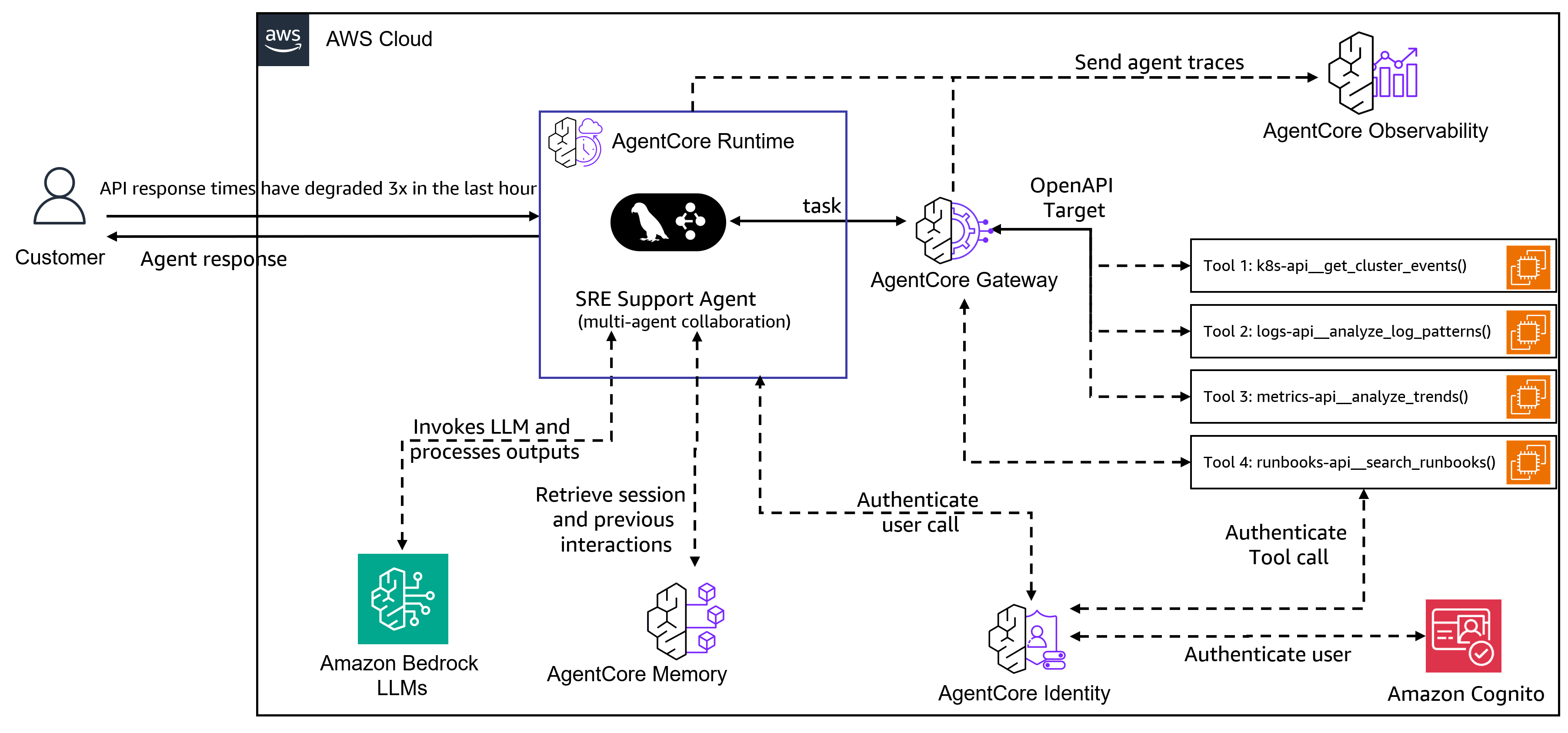
Use case key Features
- Multi-Agent Orchestration: Specialized agents collaborate on infrastructure investigations with real-time streaming
- Conversational Interface: Single-query investigations and interactive multi-turn conversations with context preservation
- Long-term Memory Integration: Amazon Bedrock Agent Memory provides persistent user preferences and infrastructure knowledge across sessions
- User Personalization: Tailored reports and escalation procedures based on individual user preferences and roles
- MCP-based Integration: AgentCore Gateway provides secure API access with authentication and health monitoring
- Specialized Agents: Four domain-specific agents for Kubernetes, logs, metrics, and operational procedures
- Documentation and Reporting: Markdown reports generated for each investigation with audit trail
Detailed Documentation
For comprehensive information about the SRE Agent system, please refer to the following detailed documentation:
- System Components - In-depth architecture and component explanations
- Memory System - Long-term memory integration, user personalization, and cross-session learning
- Configuration - Complete configuration guides for environment variables, agents, and gateway
- Deployment Guide - Complete deployment guide for Amazon Bedrock AgentCore Runtime
- Security - Security best practices and considerations for production deployment
- Demo Environment - Demo scenarios, data customization, and testing setup
- Example Use Cases - Detailed walkthroughs and interactive troubleshooting examples
- Verification - Ground truth verification and report validation
- Development - Testing, code quality, and contribution guidelines
Prerequisites
| Requirement | Description |
|---|---|
Python 3.12+ and uv |
Python runtime and package manager. See use-case setup |
| Amazon EC2 Instance | Recommended: t3.xlarge or larger |
| Valid SSL certificates | ⚠️ IMPORTANT: Amazon Bedrock AgentCore Gateway only works with HTTPS endpoints. For example, you can register your Amazon EC2 with no-ip.com and obtain a certificate from letsencrypt.org, or use any other domain registration and SSL certificate provider. You'll need the domain name as BACKEND_DOMAIN and certificate paths in the use-case setup section |
| EC2 instance port configuration | Required inbound ports (443, 8011-8014). See EC2 instance port configuration |
| IAM role with BedrockAgentCoreFullAccess policy | Required permissions and trust policy for AgentCore service. See IAM role with BedrockAgentCoreFullAccess policy |
| Identity Provider (IDP) | Amazon Cognito, Auth0, or Okta for JWT authentication. For automated Cognito setup, use deployment/setup_cognito.sh. See Authentication setup |
Note: All prerequisites must be completed before proceeding to the use case setup. The setup will fail without proper SSL certificates, IAM permissions, and identity provider configuration.
Use case setup
Configuration Guide: For detailed information about all configuration files used in this project, see the Configuration Documentation.
# Clone the repository
git clone https://github.com/awslabs/amazon-bedrock-agentcore-samples
cd amazon-bedrock-agentcore-samples/02-use-cases/SRE-agent
# Create and activate a virtual environment
uv venv --python 3.12
source .venv/bin/activate # On Windows: .venv\Scripts\activate
# Install the SRE Agent and dependencies
uv pip install -e .
# Configure environment variables
cp .env.example sre_agent/.env
# Edit sre_agent/.env and add your Anthropic API key:
# ANTHROPIC_API_KEY=sk-ant-your-key-here
# Openapi Templates get replaced with your backend domain and saved as .yaml
BACKEND_DOMAIN=api.mycompany.com ./backend/openapi_specs/generate_specs.sh
# Get your EC2 instance private IP for server binding
TOKEN=$(curl -X PUT "http://169.254.169.254/latest/api/token" \
-H "X-aws-ec2-metadata-token-ttl-seconds: 21600" -s)
PRIVATE_IP=$(curl -H "X-aws-ec2-metadata-token: $TOKEN" \
-s http://169.254.169.254/latest/meta-data/local-ipv4)
# Start the demo backend servers with SSL
cd backend
./scripts/start_demo_backend.sh \
--host $PRIVATE_IP \
--ssl-keyfile /opt/ssl/privkey.pem \
--ssl-certfile /opt/ssl/fullchain.pem
cd ..
# Create and configure the AgentCore Gateway
cd gateway
./create_gateway.sh
./mcp_cmds.sh
cd ..
# Update the gateway URI in agent configuration
GATEWAY_URI=$(cat gateway/.gateway_uri)
sed -i "s|uri: \".*\"|uri: \"$GATEWAY_URI\"|" sre_agent/config/agent_config.yaml
# Copy the gateway access token to your .env file
sed -i '/^GATEWAY_ACCESS_TOKEN=/d' sre_agent/.env
echo "GATEWAY_ACCESS_TOKEN=$(cat gateway/.access_token)" >> sre_agent/.env
# Initialize memory system and add user preferences
uv run python scripts/manage_memories.py update
# Note: Memory system takes 10-12 minutes to be ready
# Check memory status after 10 minutes:
uv run python scripts/manage_memories.py list
# Once memory shows as ready, run update again to ensure preferences are loaded:
uv run python scripts/manage_memories.py update
Local Setup Complete: Your SRE Agent is now running locally on your EC2 instance and is exercising the AgentCore Gateway and Memory services. If you want to deploy this agent on AgentCore Runtime so you can integrate it into your applications (like a chatbot, Slack bot, etc.), follow the instructions in the Development to Production Deployment Flow section below.
Execution instructions
Memory-Enhanced Personalized Investigations
The SRE Agent includes a sophisticated memory system that personalizes investigations based on user preferences. The system comes preconfigured with two user personas in scripts/user_config.yaml:
- Alice: Technical detailed investigations with comprehensive analysis and team alerts
- Carol: Executive-focused investigations with business impact analysis and strategic alerts
When running investigations with different user IDs, the agent produces similar technical findings but presents them according to each user's preferences:
# Alice's detailed technical investigation
USER_ID=Alice sre-agent --prompt "API response times have degraded 3x in the last hour" --provider bedrock
# Carol's executive-focused investigation
USER_ID=Carol sre-agent --prompt "API response times have degraded 3x in the last hour" --provider bedrock
Both commands will identify identical technical issues but present them differently:
- Alice receives detailed technical analysis with step-by-step troubleshooting and team notifications
- Carol receives executive summaries focused on business impact with rapid escalation timelines
For a detailed comparison showing how the memory system personalizes identical incidents, see: Memory System Report Comparison
Single Query Mode
# Investigate specific pod issues
sre-agent --prompt "Why are the payment-service pods crash looping?"
# Analyze performance degradation
sre-agent --prompt "Investigate high latency in the API gateway over the last hour"
# Search for error patterns
sre-agent --prompt "Find all database connection errors in the last 24 hours"
Interactive Mode
# Start interactive conversation
sre-agent --interactive
# Available commands in interactive mode:
# /help - Show available commands
# /agents - List available specialist agents
# /history - Show conversation history
# /save - Save the current conversation
# /clear - Clear conversation history
# /exit - Exit the interactive session
Advanced Options
# Use Amazon Bedrock
sre-agent --provider bedrock --query "Check cluster health"
# Save investigation reports to custom directory
sre-agent --output-dir ./investigations --query "Analyze memory usage trends"
# Use Amazon Bedrock with specific profile
AWS_PROFILE=production sre-agent --provider bedrock --interactive
Development to Production Deployment Flow
The SRE Agent follows a structured deployment process from local development to production on Amazon Bedrock AgentCore Runtime. For detailed instructions, see the Deployment Guide.
STEP 1: LOCAL DEVELOPMENT
┌─────────────────────────────────────────────────────────────────────┐
│ Develop Python Package (sre_agent/) │
│ └─> Test locally with CLI: uv run sre-agent --prompt "..." │
│ └─> Agent connects to AgentCore Gateway via MCP protocol │
└─────────────────────────────────────────────────────────────────────┘
↓
STEP 2: CONTAINERIZATION
┌─────────────────────────────────────────────────────────────────────┐
│ Add agent_runtime.py (FastAPI server wrapper) │
│ └─> Create Dockerfile (ARM64 for AgentCore) │
│ └─> Uses deployment/build_and_deploy.sh script │
└─────────────────────────────────────────────────────────────────────┘
↓
STEP 3: LOCAL CONTAINER TESTING
┌─────────────────────────────────────────────────────────────────────┐
│ Build: LOCAL_BUILD=true ./deployment/build_and_deploy.sh │
│ └─> Run: docker run -p 8080:8080 sre_agent:latest │
│ └─> Test: curl -X POST http://localhost:8080/invocations │
│ └─> Container connects to same AgentCore Gateway │
└─────────────────────────────────────────────────────────────────────┘
↓
STEP 4: PRODUCTION DEPLOYMENT
┌─────────────────────────────────────────────────────────────────────┐
│ Build & Push: ./deployment/build_and_deploy.sh │
│ └─> Pushes container to Amazon ECR │
│ └─> deployment/deploy_agent_runtime.py deploys to AgentCore │
│ └─> Test: uv run python deployment/invoke_agent_runtime.py │
│ └─> Production agent uses production Gateway │
└─────────────────────────────────────────────────────────────────────┘
Key Points:
• Core agent code (sre_agent/) remains unchanged
• Deployment/ folder contains all deployment-specific utilities
• Same agent works locally and in production via environment config
• AgentCore Gateway provides MCP tools access at all stages
Deploying Your Agent on Amazon Bedrock AgentCore Runtime
For production deployments, you can deploy the SRE Agent directly to Amazon Bedrock AgentCore Runtime. This provides a scalable, managed environment for running your agent with enterprise-grade security and monitoring.
The AgentCore Runtime deployment supports:
- Container-based deployment with automatic scaling
- Multiple LLM providers (Amazon Bedrock or Anthropic Claude)
- Debug mode for troubleshooting and development
- Environment-based configuration for different deployment stages
- Secure credential management through AWS IAM and environment variables
For complete step-by-step instructions including local testing, container building, and production deployment, see the Deployment Guide.
Maintenance and Operations
Restarting Backend Servers and Refreshing Access Token
To maintain connectivity with the Amazon Bedrock AgentCore Gateway, you need to periodically restart backend servers and refresh the access token. Run the gateway configuration script:
# Important: Run this from within the virtual environment
source .venv/bin/activate # If not already activated
./scripts/configure_gateway.sh
What this script does:
- Stops running backend servers to ensure clean restart
- Generates a new access token for AgentCore Gateway authentication
- Gets the EC2 instance private IP for proper SSL binding
- Starts backend servers with SSL certificates (HTTPS) or HTTP fallback
- Updates gateway URI in the agent configuration from
gateway/.gateway_uri - Updates access token in the
.envfile for agent authentication
Important: You must run this script every 24 hours because the access token expires after 24 hours. If you don't refresh the token:
- The SRE agent will lose connection to the AgentCore gateway
- No MCP tools will be available (Kubernetes, logs, metrics, runbooks APIs)
- Investigations will fail as agents cannot access backend services
For more details, see the configure_gateway.sh script.
Troubleshooting Gateway Connection Issues
If you encounter "gateway connection failed" or "MCP tools unavailable" errors:
- Check if the access token has expired (24-hour limit)
- Run
./scripts/configure_gateway.shto refresh authentication (from within the virtual environment) - Verify backend servers are running with
ps aux | grep python - Check SSL certificate validity if using HTTPS
Clean up instructions
Complete AWS Resource Cleanup
For complete cleanup of all AWS resources (Gateway, Runtime, and local files):
# Complete cleanup - deletes AWS resources and local files
./scripts/cleanup.sh
# Or with custom names
./scripts/cleanup.sh --gateway-name my-gateway --runtime-name my-runtime
# Force cleanup without confirmation prompts
./scripts/cleanup.sh --force
This script will:
- Stop backend servers
- Delete the AgentCore Gateway and all its targets
- Delete memory resources
- Delete the AgentCore Runtime
- Remove generated files (gateway URIs, tokens, agent ARNs, memory IDs)
Manual Local Cleanup Only
If you only want to clean up local files without touching AWS resources:
# Stop all demo servers
cd backend
./scripts/stop_demo_backend.sh
cd ..
# Clean up generated files only
rm -rf gateway/.gateway_uri gateway/.access_token
rm -rf deployment/.agent_arn .memory_id
# Note: .env, .venv, and reports/ are preserved for development continuity
Disclaimer
The examples provided in this repository are for experimental and educational purposes only. They demonstrate concepts and techniques but are not intended for direct use in production environments. Make sure to have Amazon Bedrock Guardrails in place to protect against prompt injection.
Important Note: The data in backend/data is synthetically generated, and the backend directory contains stub servers that showcase how a real SRE agent backend could work. In a production environment, these implementations would need to be replaced with real implementations that connect to actual systems, use vector databases, and integrate with other data sources.