mirror of https://github.com/apache/druid.git
Merge branch 'master' of github.com:metamx/druid into move-firehose
This commit is contained in:
commit
eef034ca7e
Binary file not shown.
Binary file not shown.
2
build.sh
2
build.sh
|
|
@ -30,4 +30,4 @@ echo "For examples, see: "
|
|||
echo " "
|
||||
ls -1 examples/*/*sh
|
||||
echo " "
|
||||
echo "See also http://druid.io/docs/0.6.81"
|
||||
echo "See also http://druid.io/docs/latest"
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
|
|||
|
|
@ -167,9 +167,20 @@ For example, data for a day may be split by the dimension "last\_name" into two
|
|||
In hashed partition type, the number of partitions is determined based on the targetPartitionSize and cardinality of input set and the data is partitioned based on the hashcode of the row.
|
||||
|
||||
It is recommended to use Hashed partition as it is more efficient than singleDimension since it does not need to determine the dimension for creating partitions.
|
||||
Hashing also gives better distribution of data resulting in equal sized partitons and improving query performance
|
||||
Hashing also gives better distribution of data resulting in equal sized partitions and improving query performance
|
||||
|
||||
To use this option, the indexer must be given a target partition size. It can then find a good set of partition ranges on its own.
|
||||
To use this druid to automatically determine optimal partitions indexer must be given a target partition size. It can then find a good set of partition ranges on its own.
|
||||
|
||||
#### Configuration for disabling auto-sharding and creating Fixed number of partitions
|
||||
Druid can be configured to NOT run determine partitions and create a fixed number of shards by specifying numShards in hashed partitionsSpec.
|
||||
e.g This configuration will skip determining optimal partitions and always create 4 shards for every segment granular interval
|
||||
|
||||
```json
|
||||
"partitionsSpec": {
|
||||
"type": "hashed"
|
||||
"numShards": 4
|
||||
}
|
||||
```
|
||||
|
||||
|property|description|required?|
|
||||
|--------|-----------|---------|
|
||||
|
|
@ -177,6 +188,7 @@ To use this option, the indexer must be given a target partition size. It can th
|
|||
|targetPartitionSize|target number of rows to include in a partition, should be a number that targets segments of 700MB\~1GB.|yes|
|
||||
|partitionDimension|the dimension to partition on. Leave blank to select a dimension automatically.|no|
|
||||
|assumeGrouped|assume input data has already been grouped on time and dimensions. This is faster, but can choose suboptimal partitions if the assumption is violated.|no|
|
||||
|numShards|provides a way to manually override druid-auto sharding and specify the number of shards to create for each segment granular interval.It is only supported by hashed partitionSpec and targetPartitionSize must be set to -1|no|
|
||||
|
||||
### Updater job spec
|
||||
|
||||
|
|
|
|||
|
|
@ -81,7 +81,7 @@ druid.server.http.numThreads=50
|
|||
druid.request.logging.type=emitter
|
||||
druid.request.logging.feed=druid_requests
|
||||
|
||||
druid.monitoring.monitors=["com.metamx.metrics.SysMonitor","com.metamx.metrics.JvmMonitor", "io.druid.client.cache.CacheMonitor"]
|
||||
druid.monitoring.monitors=["com.metamx.metrics.SysMonitor","com.metamx.metrics.JvmMonitor"]
|
||||
|
||||
# Emit metrics over http
|
||||
druid.emitter=http
|
||||
|
|
@ -106,16 +106,16 @@ The broker module uses several of the default modules in [Configuration](Configu
|
|||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.broker.cache.sizeInBytes`|Maximum size of the cache. If this is zero, cache is disabled.|10485760 (10MB)|
|
||||
|`druid.broker.cache.initialSize`|The initial size of the cache in bytes.|500000|
|
||||
|`druid.broker.cache.logEvictionCount`|If this is non-zero, there will be an eviction of entries.|0|
|
||||
|`druid.broker.cache.sizeInBytes`|Maximum cache size in bytes. Zero disables caching.|0|
|
||||
|`druid.broker.cache.initialSize`|Initial size of the hashtable backing the cache.|500000|
|
||||
|`druid.broker.cache.logEvictionCount`|If non-zero, log cache eviction every `logEvictionCount` items.|0|
|
||||
|
||||
#### Memcache
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.broker.cache.expiration`|Memcache [expiration time ](https://code.google.com/p/memcached/wiki/NewCommands#Standard_Protocol).|2592000 (30 days)|
|
||||
|`druid.broker.cache.timeout`|Maximum time in milliseconds to wait for a response from Memcache.|500|
|
||||
|`druid.broker.cache.hosts`|Memcache hosts.|none|
|
||||
|`druid.broker.cache.maxObjectSize`|Maximum object size in bytes for a Memcache object.|52428800 (50 MB)|
|
||||
|`druid.broker.cache.memcachedPrefix`|Key prefix for all keys in Memcache.|druid|
|
||||
|`druid.broker.cache.expiration`|Memcached [expiration time](https://code.google.com/p/memcached/wiki/NewCommands#Standard_Protocol).|2592000 (30 days)|
|
||||
|`druid.broker.cache.timeout`|Maximum time in milliseconds to wait for a response from Memcached.|500|
|
||||
|`druid.broker.cache.hosts`|Command separated list of Memcached hosts `<host:port>`.|none|
|
||||
|`druid.broker.cache.maxObjectSize`|Maximum object size in bytes for a Memcached object.|52428800 (50 MB)|
|
||||
|`druid.broker.cache.memcachedPrefix`|Key prefix for all keys in Memcached.|druid|
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ layout: doc_page
|
|||
|
||||
# Configuring Druid
|
||||
|
||||
This describes the basic server configuration that is loaded by all the server processes; the same file is loaded by all. See also the json "specFile" descriptions in [Realtime](Realtime.html) and [Batch-ingestion](Batch-ingestion.html).
|
||||
This describes the basic server configuration that is loaded by all Druid server processes; the same file is loaded by all. See also the JSON "specFile" descriptions in [Realtime](Realtime.html) and [Batch-ingestion](Batch-ingestion.html).
|
||||
|
||||
## JVM Configuration Best Practices
|
||||
|
||||
|
|
@ -26,7 +26,7 @@ Note: as a future item, we’d like to consolidate all of the various configurat
|
|||
|
||||
### Emitter Module
|
||||
|
||||
The Druid servers emit various metrics and alerts via something we call an Emitter. There are two emitter implementations included with the code, one that just logs to log4j and one that does POSTs of JSON events to a server. The properties for using the logging emitter are described below.
|
||||
The Druid servers emit various metrics and alerts via something we call an Emitter. There are two emitter implementations included with the code, one that just logs to log4j ("logging", which is used by default if no emitter is specified) and one that does POSTs of JSON events to a server ("http"). The properties for using the logging emitter are described below.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|
|
@ -47,7 +47,7 @@ The Druid servers emit various metrics and alerts via something we call an Emitt
|
|||
|`druid.emitter.http.timeOut`|The timeout for data reads.|PT5M|
|
||||
|`druid.emitter.http.flushMillis`|How often to internal message buffer is flushed (data is sent).|60000|
|
||||
|`druid.emitter.http.flushCount`|How many messages can the internal message buffer hold before flushing (sending).|500|
|
||||
|`druid.emitter.http.recipientBaseUrl`|The base URL to emit messages to.|none|
|
||||
|`druid.emitter.http.recipientBaseUrl`|The base URL to emit messages to. Druid will POST JSON to be consumed at the HTTP endpoint specified by this property.|none|
|
||||
|
||||
### Http Client Module
|
||||
|
||||
|
|
@ -56,7 +56,7 @@ This is the HTTP client used by [Broker](Broker.html) nodes.
|
|||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.broker.http.numConnections`|Size of connection pool for the Broker to connect to historical and real-time nodes. If there are more queries than this number that all need to speak to the same node, then they will queue up.|5|
|
||||
|`druid.broker.http.readTimeout`|The timeout for data reads.|none|
|
||||
|`druid.broker.http.readTimeout`|The timeout for data reads.|PT15M|
|
||||
|
||||
### Curator Module
|
||||
|
||||
|
|
@ -64,17 +64,17 @@ Druid uses [Curator](http://curator.incubator.apache.org/) for all [Zookeeper](h
|
|||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.zk.service.host`|The Zookeeper hosts to connect to.|none|
|
||||
|`druid.zk.service.sessionTimeoutMs`|Zookeeper session timeout.|30000|
|
||||
|`druid.zk.service.host`|The ZooKeeper hosts to connect to. This is a REQUIRED property and therefore a host address must be supplied.|none|
|
||||
|`druid.zk.service.sessionTimeoutMs`|ZooKeeper session timeout, in milliseconds.|30000|
|
||||
|`druid.curator.compress`|Boolean flag for whether or not created Znodes should be compressed.|false|
|
||||
|
||||
### Announcer Module
|
||||
|
||||
The announcer module is used to announce and unannounce Znodes in Zookeeper (using Curator).
|
||||
The announcer module is used to announce and unannounce Znodes in ZooKeeper (using Curator).
|
||||
|
||||
#### Zookeeper Paths
|
||||
#### ZooKeeper Paths
|
||||
|
||||
See [Zookeeper](Zookeeper.html).
|
||||
See [ZooKeeper](ZooKeeper.html).
|
||||
|
||||
#### Data Segment Announcer
|
||||
|
||||
|
|
@ -84,11 +84,11 @@ Data segment announcers are used to announce segments.
|
|||
|--------|-----------|-------|
|
||||
|`druid.announcer.type`|Choices: legacy or batch. The type of data segment announcer to use.|legacy|
|
||||
|
||||
#### Single Data Segment Announcer
|
||||
##### Single Data Segment Announcer
|
||||
|
||||
In legacy Druid, each segment served by a node would be announced as an individual Znode.
|
||||
|
||||
#### Batch Data Segment Announcer
|
||||
##### Batch Data Segment Announcer
|
||||
|
||||
In current Druid, multiple data segments may be announced under the same Znode.
|
||||
|
||||
|
|
@ -105,16 +105,8 @@ This module contains query processing functionality.
|
|||
|--------|-----------|-------|
|
||||
|`druid.processing.buffer.sizeBytes`|This specifies a buffer size for the storage of intermediate results. The computation engine in both the Historical and Realtime nodes will use a scratch buffer of this size to do all of their intermediate computations off-heap. Larger values allow for more aggregations in a single pass over the data while smaller values can require more passes depending on the query that is being executed.|1073741824 (1GB)|
|
||||
|`druid.processing.formatString`|Realtime and historical nodes use this format string to name their processing threads.|processing-%s|
|
||||
|`druid.processing.numThreads`|The number of processing threads to have available for parallel processing of segments. Our rule of thumb is `num_cores - 1`, this means that even under heavy load there will still be one core available to do background tasks like talking with ZK and pulling down segments.|1|
|
||||
|`druid.processing.numThreads`|The number of processing threads to have available for parallel processing of segments. Our rule of thumb is `num_cores - 1`, which means that even under heavy load there will still be one core available to do background tasks like talking with ZooKeeper and pulling down segments. If only one core is available, this property defaults to the value `1`.|Number of cores - 1 (or 1)|
|
||||
|
||||
### AWS Module
|
||||
|
||||
This module is used to interact with S3.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.s3.accessKey`|The access key to use to access S3.|none|
|
||||
|`druid.s3.secretKey`|The secret key to use to access S3.|none|
|
||||
|
||||
### Metrics Module
|
||||
|
||||
|
|
@ -123,7 +115,15 @@ The metrics module is used to track Druid metrics.
|
|||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.monitoring.emissionPeriod`|How often metrics are emitted.|PT1m|
|
||||
|`druid.monitoring.monitors`|List of Druid monitors.|none|
|
||||
|`druid.monitoring.monitors`|Sets list of Druid monitors used by a node. Each monitor is specified as `com.metamx.metrics.<monitor-name>` (see below for names and more information). For example, you can specify monitors for a Broker with `druid.monitoring.monitors=["com.metamx.metrics.SysMonitor","com.metamx.metrics.JvmMonitor"]`.|none (no monitors)|
|
||||
|
||||
The following monitors are available:
|
||||
|
||||
* CacheMonitor – Emits metrics (to logs) about the segment results cache for Historical and Broker nodes. Reports typical cache statistics include hits, misses, rates, and size (bytes and number of entries), as well as timeouts and and errors.
|
||||
* SysMonitor – This uses the [SIGAR library](http://www.hyperic.com/products/sigar) to report on various system activities and statuses.
|
||||
* ServerMonitor – Reports statistics on Historical nodes.
|
||||
* JvmMonitor – Reports JVM-related statistics.
|
||||
* RealtimeMetricsMonitor – Reports statistics on Realtime nodes.
|
||||
|
||||
### Server Module
|
||||
|
||||
|
|
@ -137,22 +137,24 @@ This module is used for Druid server nodes.
|
|||
|
||||
### Storage Node Module
|
||||
|
||||
This module is used by nodes that store data (historical and real-time nodes).
|
||||
This module is used by nodes that store data (Historical and Realtime).
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.server.maxSize`|The maximum number of bytes worth of segments that the node wants assigned to it. This is not a limit that the historical nodes actually enforce, they just publish it to the coordinator and trust the coordinator to do the right thing|0|
|
||||
|`druid.server.tier`|Druid server host port.|none|
|
||||
|`druid.server.maxSize`|The maximum number of bytes-worth of segments that the node wants assigned to it. This is not a limit that Historical nodes actually enforce, just a value published to the Coordinator node so it can plan accordingly.|0|
|
||||
|`druid.server.tier`| A string to name the distribution tier that the storage node belongs to. Many of the [rules Coordinator nodes use](Rule-Configuration.html) to manage segments can be keyed on tiers. | `_default_tier` |
|
||||
|`druid.server.priority`|In a tiered architecture, the priority of the tier, thus allowing control over which nodes are queried. Higher numbers mean higher priority. The default (no priority) works for architecture with no cross replication (tiers that have no data-storage overlap). Data centers typically have equal priority. | 0 |
|
||||
|
||||
|
||||
#### Segment Cache
|
||||
|
||||
Druid storage nodes maintain information about segments they have already downloaded.
|
||||
Druid storage nodes maintain information about segments they have already downloaded, and a disk cache to store that data.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.segmentCache.locations`|Segments assigned to a historical node are first stored on the local file system and then served by the historical node. These locations define where that local cache resides|none|
|
||||
|`druid.segmentCache.locations`|Segments assigned to a Historical node are first stored on the local file system (in a disk cache) and then served by the Historical node. These locations define where that local cache resides. | none (no caching) |
|
||||
|`druid.segmentCache.deleteOnRemove`|Delete segment files from cache once a node is no longer serving a segment.|true|
|
||||
|`druid.segmentCache.infoDir`|Historical nodes keep track of the segments they are serving so that when the process is restarted they can reload the same segments without waiting for the coordinator to reassign. This path defines where this metadata is kept. Directory will be created if needed.|${first_location}/info_dir|
|
||||
|`druid.segmentCache.infoDir`|Historical nodes keep track of the segments they are serving so that when the process is restarted they can reload the same segments without waiting for the Coordinator to reassign. This path defines where this metadata is kept. Directory will be created if needed.|${first_location}/info_dir|
|
||||
|
||||
### Jetty Server Module
|
||||
|
||||
|
|
@ -193,7 +195,7 @@ This module is required by nodes that can serve queries.
|
|||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.query.chunkPeriod`|Long interval queries may be broken into shorter interval queries.|0|
|
||||
|`druid.query.chunkPeriod`|Long-interval queries (of any type) may be broken into shorter interval queries, reducing the impact on resources. Use ISO 8601 periods. For example, if this property is set to `P1M` (one month), then a query covering a year would be broken into 12 smaller queries. |0 (off)|
|
||||
|
||||
#### GroupBy Query Config
|
||||
|
||||
|
|
@ -210,17 +212,28 @@ This module is required by nodes that can serve queries.
|
|||
|--------|-----------|-------|
|
||||
|`druid.query.search.maxSearchLimit`|Maximum number of search results to return.|1000|
|
||||
|
||||
|
||||
### Discovery Module
|
||||
|
||||
The discovery module is used for service discovery.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.discovery.curator.path`|Services announce themselves under this Zookeeper path.|/druid/discovery|
|
||||
|`druid.discovery.curator.path`|Services announce themselves under this ZooKeeper path.|/druid/discovery|
|
||||
|
||||
|
||||
#### Indexing Service Discovery Module
|
||||
|
||||
This module is used to find the [Indexing Service](Indexing-Service.html) using Curator service discovery.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.selectors.indexing.serviceName`|The druid.service name of the indexing service Overlord node. To start the Overlord with a different name, set it with this property. |overlord|
|
||||
|
||||
|
||||
### Server Inventory View Module
|
||||
|
||||
This module is used to read announcements of segments in Zookeeper. The configs are identical to the Announcer Module.
|
||||
This module is used to read announcements of segments in ZooKeeper. The configs are identical to the Announcer Module.
|
||||
|
||||
### Database Connector Module
|
||||
|
||||
|
|
@ -228,7 +241,6 @@ These properties specify the jdbc connection and other configuration around the
|
|||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.db.connector.pollDuration`|The jdbc connection URI.|none|
|
||||
|`druid.db.connector.user`|The username to connect with.|none|
|
||||
|`druid.db.connector.password`|The password to connect with.|none|
|
||||
|`druid.db.connector.createTables`|If Druid requires a table and it doesn't exist, create it?|true|
|
||||
|
|
@ -250,13 +262,6 @@ The Jackson Config manager reads and writes config entries from the Druid config
|
|||
|--------|-----------|-------|
|
||||
|`druid.manager.config.pollDuration`|How often the manager polls the config table for updates.|PT1m|
|
||||
|
||||
### Indexing Service Discovery Module
|
||||
|
||||
This module is used to find the [Indexing Service](Indexing-Service.html) using Curator service discovery.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.selectors.indexing.serviceName`|The druid.service name of the indexing service Overlord node.|none|
|
||||
|
||||
### DataSegment Pusher/Puller Module
|
||||
|
||||
|
|
@ -290,6 +295,16 @@ This deep storage is used to interface with Amazon's S3.
|
|||
|`druid.storage.archiveBucket`|S3 bucket name for archiving when running the indexing-service *archive task*.|none|
|
||||
|`druid.storage.archiveBaseKey`|S3 object key prefix for archiving.|none|
|
||||
|
||||
#### AWS Module
|
||||
|
||||
This module is used to interact with S3.
|
||||
|
||||
|Property|Description|Default|
|
||||
|--------|-----------|-------|
|
||||
|`druid.s3.accessKey`|The access key to use to access S3.|none|
|
||||
|`druid.s3.secretKey`|The secret key to use to access S3.|none|
|
||||
|
||||
|
||||
#### HDFS Deep Storage
|
||||
|
||||
This deep storage is used to interface with HDFS.
|
||||
|
|
|
|||
|
|
@ -19,13 +19,13 @@ Clone Druid and build it:
|
|||
git clone https://github.com/metamx/druid.git druid
|
||||
cd druid
|
||||
git fetch --tags
|
||||
git checkout druid-0.6.81
|
||||
git checkout druid-0.6.101
|
||||
./build.sh
|
||||
```
|
||||
|
||||
### Downloading the DSK (Druid Standalone Kit)
|
||||
|
||||
[Download](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz) a stand-alone tarball and run it:
|
||||
[Download](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz) a stand-alone tarball and run it:
|
||||
|
||||
``` bash
|
||||
tar -xzf druid-services-0.X.X-bin.tar.gz
|
||||
|
|
|
|||
|
|
@ -66,7 +66,7 @@ druid.host=#{IP_ADDR}:8080
|
|||
druid.port=8080
|
||||
druid.service=druid/prod/indexer
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101"]
|
||||
|
||||
druid.zk.service.host=#{ZK_IPs}
|
||||
druid.zk.paths.base=/druid/prod
|
||||
|
|
@ -115,7 +115,7 @@ druid.host=#{IP_ADDR}:8080
|
|||
druid.port=8080
|
||||
druid.service=druid/prod/worker
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81","io.druid.extensions:druid-kafka-seven:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101","io.druid.extensions:druid-kafka-seven:0.6.101"]
|
||||
|
||||
druid.zk.service.host=#{ZK_IPs}
|
||||
druid.zk.paths.base=/druid/prod
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ druid.host=localhost
|
|||
druid.service=realtime
|
||||
druid.port=8083
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-kafka-seven:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-kafka-seven:0.6.101"]
|
||||
|
||||
|
||||
druid.zk.service.host=localhost
|
||||
|
|
@ -76,7 +76,7 @@ druid.host=#{IP_ADDR}:8080
|
|||
druid.port=8080
|
||||
druid.service=druid/prod/realtime
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81","io.druid.extensions:druid-kafka-seven:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101","io.druid.extensions:druid-kafka-seven:0.6.101"]
|
||||
|
||||
druid.zk.service.host=#{ZK_IPs}
|
||||
druid.zk.paths.base=/druid/prod
|
||||
|
|
|
|||
|
|
@ -0,0 +1,142 @@
|
|||
---
|
||||
layout: doc_page
|
||||
---
|
||||
# Select Queries
|
||||
Select queries return raw Druid rows and support pagination.
|
||||
|
||||
```json
|
||||
{
|
||||
"queryType": "select",
|
||||
"dataSource": "wikipedia",
|
||||
"dimensions":[],
|
||||
"metrics":[],
|
||||
"granularity": "all",
|
||||
"intervals": [
|
||||
"2013-01-01/2013-01-02"
|
||||
],
|
||||
"pagingSpec":{"pagingIdentifiers": {}, "threshold":5}
|
||||
}
|
||||
```
|
||||
|
||||
There are several main parts to a select query:
|
||||
|
||||
|property|description|required?|
|
||||
|--------|-----------|---------|
|
||||
|queryType|This String should always be "select"; this is the first thing Druid looks at to figure out how to interpret the query|yes|
|
||||
|dataSource|A String defining the data source to query, very similar to a table in a relational database|yes|
|
||||
|intervals|A JSON Object representing ISO-8601 Intervals. This defines the time ranges to run the query over.|yes|
|
||||
|dimensions|The list of dimensions to select. If left empty, all dimensions are returned.|no|
|
||||
|metrics|The list of metrics to select. If left empty, all metrics are returned.|no|
|
||||
|pagingSpec|A JSON object indicating offsets into different scanned segments. Select query results will return a pagingSpec that can be reused for pagination.|yes|
|
||||
|context|An additional JSON Object which can be used to specify certain flags.|no|
|
||||
|
||||
The format of the result is:
|
||||
|
||||
```json
|
||||
[{
|
||||
"timestamp" : "2013-01-01T00:00:00.000Z",
|
||||
"result" : {
|
||||
"pagingIdentifiers" : {
|
||||
"wikipedia_2012-12-29T00:00:00.000Z_2013-01-10T08:00:00.000Z_2013-01-10T08:13:47.830Z_v9" : 4
|
||||
},
|
||||
"events" : [ {
|
||||
"segmentId" : "wikipedia_editstream_2012-12-29T00:00:00.000Z_2013-01-10T08:00:00.000Z_2013-01-10T08:13:47.830Z_v9",
|
||||
"offset" : 0,
|
||||
"event" : {
|
||||
"timestamp" : "2013-01-01T00:00:00.000Z",
|
||||
"robot" : "1",
|
||||
"namespace" : "article",
|
||||
"anonymous" : "0",
|
||||
"unpatrolled" : "0",
|
||||
"page" : "11._korpus_(NOVJ)",
|
||||
"language" : "sl",
|
||||
"newpage" : "0",
|
||||
"user" : "EmausBot",
|
||||
"count" : 1.0,
|
||||
"added" : 39.0,
|
||||
"delta" : 39.0,
|
||||
"variation" : 39.0,
|
||||
"deleted" : 0.0
|
||||
}
|
||||
}, {
|
||||
"segmentId" : "wikipedia_2012-12-29T00:00:00.000Z_2013-01-10T08:00:00.000Z_2013-01-10T08:13:47.830Z_v9",
|
||||
"offset" : 1,
|
||||
"event" : {
|
||||
"timestamp" : "2013-01-01T00:00:00.000Z",
|
||||
"robot" : "0",
|
||||
"namespace" : "article",
|
||||
"anonymous" : "0",
|
||||
"unpatrolled" : "0",
|
||||
"page" : "112_U.S._580",
|
||||
"language" : "en",
|
||||
"newpage" : "1",
|
||||
"user" : "MZMcBride",
|
||||
"count" : 1.0,
|
||||
"added" : 70.0,
|
||||
"delta" : 70.0,
|
||||
"variation" : 70.0,
|
||||
"deleted" : 0.0
|
||||
}
|
||||
}, {
|
||||
"segmentId" : "wikipedia_2012-12-29T00:00:00.000Z_2013-01-10T08:00:00.000Z_2013-01-10T08:13:47.830Z_v9",
|
||||
"offset" : 2,
|
||||
"event" : {
|
||||
"timestamp" : "2013-01-01T00:00:00.000Z",
|
||||
"robot" : "0",
|
||||
"namespace" : "article",
|
||||
"anonymous" : "0",
|
||||
"unpatrolled" : "0",
|
||||
"page" : "113_U.S._243",
|
||||
"language" : "en",
|
||||
"newpage" : "1",
|
||||
"user" : "MZMcBride",
|
||||
"count" : 1.0,
|
||||
"added" : 77.0,
|
||||
"delta" : 77.0,
|
||||
"variation" : 77.0,
|
||||
"deleted" : 0.0
|
||||
}
|
||||
}, {
|
||||
"segmentId" : "wikipedia_2012-12-29T00:00:00.000Z_2013-01-10T08:00:00.000Z_2013-01-10T08:13:47.830Z_v9",
|
||||
"offset" : 3,
|
||||
"event" : {
|
||||
"timestamp" : "2013-01-01T00:00:00.000Z",
|
||||
"robot" : "0",
|
||||
"namespace" : "article",
|
||||
"anonymous" : "0",
|
||||
"unpatrolled" : "0",
|
||||
"page" : "113_U.S._73",
|
||||
"language" : "en",
|
||||
"newpage" : "1",
|
||||
"user" : "MZMcBride",
|
||||
"count" : 1.0,
|
||||
"added" : 70.0,
|
||||
"delta" : 70.0,
|
||||
"variation" : 70.0,
|
||||
"deleted" : 0.0
|
||||
}
|
||||
}, {
|
||||
"segmentId" : "wikipedia_2012-12-29T00:00:00.000Z_2013-01-10T08:00:00.000Z_2013-01-10T08:13:47.830Z_v9",
|
||||
"offset" : 4,
|
||||
"event" : {
|
||||
"timestamp" : "2013-01-01T00:00:00.000Z",
|
||||
"robot" : "0",
|
||||
"namespace" : "article",
|
||||
"anonymous" : "0",
|
||||
"unpatrolled" : "0",
|
||||
"page" : "113_U.S._756",
|
||||
"language" : "en",
|
||||
"newpage" : "1",
|
||||
"user" : "MZMcBride",
|
||||
"count" : 1.0,
|
||||
"added" : 68.0,
|
||||
"delta" : 68.0,
|
||||
"variation" : 68.0,
|
||||
"deleted" : 0.0
|
||||
}
|
||||
} ]
|
||||
}
|
||||
} ]
|
||||
```
|
||||
|
||||
The result returns a global pagingSpec that can be reused for the next select query. The offset will need to be increased by 1 on the client side.
|
||||
|
|
@ -51,12 +51,12 @@ The Index Task is a simpler variation of the Index Hadoop task that is designed
|
|||
|--------|-----------|---------|
|
||||
|type|The task type, this should always be "index".|yes|
|
||||
|id|The task ID. If this is not explicitly specified, Druid generates the task ID using the name of the task file and date-time stamp. |no|
|
||||
|granularitySpec|Specifies the segment chunks that the task will process. `type` is always "uniform"; `gran` sets the granularity of the chunks ("DAY" means all segments containing timestamps in the same day, while `intervals` sets the interval that the chunks will cover.|yes|
|
||||
|granularitySpec|Specifies the segment chunks that the task will process. `type` is always "uniform"; `gran` sets the granularity of the chunks ("DAY" means all segments containing timestamps in the same day), while `intervals` sets the interval that the chunks will cover.|yes|
|
||||
|spatialDimensions|Dimensions to build spatial indexes over. See [Geographic Queries](GeographicQueries.html).|no|
|
||||
|aggregators|The metrics to aggregate in the data set. For more info, see [Aggregations](Aggregations.html)|yes|
|
||||
|aggregators|The metrics to aggregate in the data set. For more info, see [Aggregations](Aggregations.html).|yes|
|
||||
|indexGranularity|The rollup granularity for timestamps. See [Realtime Ingestion](Realtime-ingestion.html) for more information. |no|
|
||||
|targetPartitionSize|Used in sharding. Determines how many rows are in each segment.|no|
|
||||
|firehose|The input source of data. For more info, see [Firehose](Firehose.html)|yes|
|
||||
|firehose|The input source of data. For more info, see [Firehose](Firehose.html).|yes|
|
||||
|rowFlushBoundary|Used in determining when intermediate persist should occur to disk.|no|
|
||||
|
||||
### Index Hadoop Task
|
||||
|
|
@ -74,14 +74,14 @@ The Hadoop Index Task is used to index larger data sets that require the paralle
|
|||
|--------|-----------|---------|
|
||||
|type|The task type, this should always be "index_hadoop".|yes|
|
||||
|config|A Hadoop Index Config. See [Batch Ingestion](Batch-ingestion.html)|yes|
|
||||
|hadoopCoordinates|The Maven \<groupId\>:\<artifactId\>:\<version\> of Hadoop to use. The default is "org.apache.hadoop:hadoop-core:1.0.3".|no|
|
||||
|hadoopCoordinates|The Maven \<groupId\>:\<artifactId\>:\<version\> of Hadoop to use. The default is "org.apache.hadoop:hadoop-client:2.3.0".|no|
|
||||
|
||||
|
||||
The Hadoop Index Config submitted as part of an Hadoop Index Task is identical to the Hadoop Index Config used by the `HadoopBatchIndexer` except that three fields must be omitted: `segmentOutputPath`, `workingPath`, `updaterJobSpec`. The Indexing Service takes care of setting these fields internally.
|
||||
|
||||
#### Using your own Hadoop distribution
|
||||
|
||||
Druid is compiled against Apache hadoop-core 1.0.3. However, if you happen to use a different flavor of hadoop that is API compatible with hadoop-core 1.0.3, you should only have to change the hadoopCoordinates property to point to the maven artifact used by your distribution.
|
||||
Druid is compiled against Apache hadoop-client 2.3.0. However, if you happen to use a different flavor of hadoop that is API compatible with hadoop-client 2.3.0, you should only have to change the hadoopCoordinates property to point to the maven artifact used by your distribution.
|
||||
|
||||
#### Resolving dependency conflicts running HadoopIndexTask
|
||||
|
||||
|
|
|
|||
|
|
@ -49,7 +49,7 @@ There are two ways to setup Druid: download a tarball, or [Build From Source](Bu
|
|||
|
||||
### Download a Tarball
|
||||
|
||||
We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz). Download this file to a directory of your choosing.
|
||||
We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz). Download this file to a directory of your choosing.
|
||||
|
||||
You can extract the awesomeness within by issuing:
|
||||
|
||||
|
|
@ -60,7 +60,7 @@ tar -zxvf druid-services-*-bin.tar.gz
|
|||
Not too lost so far right? That's great! If you cd into the directory:
|
||||
|
||||
```
|
||||
cd druid-services-0.6.81
|
||||
cd druid-services-0.6.101
|
||||
```
|
||||
|
||||
You should see a bunch of files:
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ Metrics (things to aggregate over):
|
|||
Setting Up
|
||||
----------
|
||||
|
||||
At this point, you should already have Druid downloaded and are comfortable with running a Druid cluster locally. If you are not, see [here](Tutiroal%3A-The-Druid-Cluster.html).
|
||||
At this point, you should already have Druid downloaded and are comfortable with running a Druid cluster locally. If you are not, see [here](Tutorial%3A-The-Druid-Cluster.html).
|
||||
|
||||
Let's start from our usual starting point in the tarball directory.
|
||||
|
||||
|
|
@ -136,7 +136,7 @@ Indexing the Data
|
|||
To index the data and build a Druid segment, we are going to need to submit a task to the indexing service. This task should already exist:
|
||||
|
||||
```
|
||||
examples/indexing/index_task.json
|
||||
examples/indexing/wikipedia_index_task.json
|
||||
```
|
||||
|
||||
Open up the file to see the following:
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ In this tutorial, we will set up other types of Druid nodes and external depende
|
|||
|
||||
If you followed the first tutorial, you should already have Druid downloaded. If not, let's go back and do that first.
|
||||
|
||||
You can download the latest version of druid [here](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz)
|
||||
You can download the latest version of druid [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz)
|
||||
|
||||
and untar the contents within by issuing:
|
||||
|
||||
|
|
@ -149,7 +149,7 @@ druid.port=8081
|
|||
|
||||
druid.zk.service.host=localhost
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101"]
|
||||
|
||||
# Dummy read only AWS account (used to download example data)
|
||||
druid.s3.secretKey=QyyfVZ7llSiRg6Qcrql1eEUG7buFpAK6T6engr1b
|
||||
|
|
@ -240,7 +240,7 @@ druid.port=8083
|
|||
|
||||
druid.zk.service.host=localhost
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.81","io.druid.extensions:druid-kafka-seven:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.101","io.druid.extensions:druid-kafka-seven:0.6.101"]
|
||||
|
||||
# Change this config to db to hand off to the rest of the Druid cluster
|
||||
druid.publish.type=noop
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ There are two ways to setup Druid: download a tarball, or [Build From Source](Bu
|
|||
|
||||
h3. Download a Tarball
|
||||
|
||||
We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz)
|
||||
We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz)
|
||||
Download this file to a directory of your choosing.
|
||||
You can extract the awesomeness within by issuing:
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ tar zxvf druid-services-*-bin.tar.gz
|
|||
Not too lost so far right? That's great! If you cd into the directory:
|
||||
|
||||
```
|
||||
cd druid-services-0.6.81
|
||||
cd druid-services-0.6.101
|
||||
```
|
||||
|
||||
You should see a bunch of files:
|
||||
|
|
|
|||
|
|
@ -1,77 +1,93 @@
|
|||
---
|
||||
layout: doc_page
|
||||
---
|
||||
Greetings! We see you've taken an interest in Druid. That's awesome! Hopefully this tutorial will help clarify some core Druid concepts. We will go through one of the Real-time "Examples":Examples.html, and issue some basic Druid queries. The data source we'll be working with is the "Twitter spritzer stream":https://dev.twitter.com/docs/streaming-apis/streams/public. If you are ready to explore Druid, brave its challenges, and maybe learn a thing or two, read on!
|
||||
Greetings! We see you've taken an interest in Druid. That's awesome! Hopefully this tutorial will help clarify some core Druid concepts. We will go through one of the Real-time [Examples](Examples.html), and issue some basic Druid queries. The data source we'll be working with is the [Twitter spritzer stream](https://dev.twitter.com/docs/streaming-apis/streams/public). If you are ready to explore Druid, brave its challenges, and maybe learn a thing or two, read on!
|
||||
|
||||
h2. Setting Up
|
||||
# Setting Up
|
||||
|
||||
There are two ways to setup Druid: download a tarball, or build it from source.
|
||||
|
||||
h3. Download a Tarball
|
||||
# Download a Tarball
|
||||
|
||||
We've built a tarball that contains everything you'll need. You'll find it "here":http://static.druid.io/artifacts/releases/druid-services-0.6.81-bin.tar.gz.
|
||||
We've built a tarball that contains everything you'll need. You'll find it [here](http://static.druid.io/artifacts/releases/druid-services-0.6.101-bin.tar.gz).
|
||||
Download this bad boy to a directory of your choosing.
|
||||
|
||||
You can extract the awesomeness within by issuing:
|
||||
|
||||
pre. tar -zxvf druid-services-0.X.X.tar.gz
|
||||
```
|
||||
tar -zxvf druid-services-0.X.X.tar.gz
|
||||
```
|
||||
|
||||
Not too lost so far right? That's great! If you cd into the directory:
|
||||
|
||||
pre. cd druid-services-0.X.X
|
||||
```
|
||||
cd druid-services-0.X.X
|
||||
```
|
||||
|
||||
You should see a bunch of files:
|
||||
|
||||
* run_example_server.sh
|
||||
* run_example_client.sh
|
||||
* LICENSE, config, examples, lib directories
|
||||
|
||||
h3. Clone and Build from Source
|
||||
# Clone and Build from Source
|
||||
|
||||
The other way to setup Druid is from source via git. To do so, run these commands:
|
||||
|
||||
<pre><code>git clone git@github.com:metamx/druid.git
|
||||
```
|
||||
git clone git@github.com:metamx/druid.git
|
||||
cd druid
|
||||
git checkout druid-0.X.X
|
||||
./build.sh
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
You should see a bunch of files:
|
||||
|
||||
<pre><code>DruidCorporateCLA.pdf README common examples indexer pom.xml server
|
||||
```
|
||||
DruidCorporateCLA.pdf README common examples indexer pom.xml server
|
||||
DruidIndividualCLA.pdf build.sh doc group_by.body install publications services
|
||||
LICENSE client eclipse_formatting.xml index-common merger realtime
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
You can find the example executables in the examples/bin directory:
|
||||
|
||||
* run_example_server.sh
|
||||
* run_example_client.sh
|
||||
|
||||
h2. Running Example Scripts
|
||||
# Running Example Scripts
|
||||
|
||||
Let's start doing stuff. You can start a Druid "Realtime":Realtime.html node by issuing:
|
||||
<code>./run_example_server.sh</code>
|
||||
Let's start doing stuff. You can start a Druid [Realtime](Realtime.html) node by issuing:
|
||||
|
||||
```
|
||||
./run_example_server.sh
|
||||
```
|
||||
|
||||
Select "twitter".
|
||||
|
||||
You'll need to register a new application with the twitter API, which only takes a minute. Go to "https://twitter.com/oauth_clients/new":https://twitter.com/oauth_clients/new and fill out the form and submit. Don't worry, the home page and callback url can be anything. This will generate keys for the Twitter example application. Take note of the values for consumer key/secret and access token/secret.
|
||||
You'll need to register a new application with the twitter API, which only takes a minute. Go to [this link](https://twitter.com/oauth_clients/new":https://twitter.com/oauth_clients/new) and fill out the form and submit. Don't worry, the home page and callback url can be anything. This will generate keys for the Twitter example application. Take note of the values for consumer key/secret and access token/secret.
|
||||
|
||||
Enter your credentials when prompted.
|
||||
|
||||
Once the node starts up you will see a bunch of logs about setting up properties and connecting to the data source. If everything was successful, you should see messages of the form shown below. If you see crazy exceptions, you probably typed in your login information incorrectly.
|
||||
<pre><code>2013-05-17 23:04:40,934 INFO [main] org.mortbay.log - Started SelectChannelConnector@0.0.0.0:8080
|
||||
|
||||
```
|
||||
2013-05-17 23:04:40,934 INFO [main] org.mortbay.log - Started SelectChannelConnector@0.0.0.0:8080
|
||||
2013-05-17 23:04:40,935 INFO [main] com.metamx.common.lifecycle.Lifecycle$AnnotationBasedHandler - Invoking start method[public void com.metamx.druid.http.FileRequestLogger.start()] on object[com.metamx.druid.http.FileRequestLogger@42bb0406].
|
||||
2013-05-17 23:04:41,578 INFO [Twitter Stream consumer-1[Establishing connection]] twitter4j.TwitterStreamImpl - Connection established.
|
||||
2013-05-17 23:04:41,578 INFO [Twitter Stream consumer-1[Establishing connection]] io.druid.examples.twitter.TwitterSpritzerFirehoseFactory - Connected_to_Twitter
|
||||
2013-05-17 23:04:41,578 INFO [Twitter Stream consumer-1[Establishing connection]] twitter4j.TwitterStreamImpl - Receiving status stream.
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
Periodically, you'll also see messages of the form:
|
||||
<pre><code>2013-05-17 23:04:59,793 INFO [chief-twitterstream] io.druid.examples.twitter.TwitterSpritzerFirehoseFactory - nextRow() has returned 1,000 InputRows
|
||||
</code></pre>
|
||||
|
||||
```
|
||||
2013-05-17 23:04:59,793 INFO [chief-twitterstream] io.druid.examples.twitter.TwitterSpritzerFirehoseFactory - nextRow() has returned 1,000 InputRows
|
||||
```
|
||||
|
||||
These messages indicate you are ingesting events. The Druid real time-node ingests events in an in-memory buffer. Periodically, these events will be persisted to disk. Persisting to disk generates a whole bunch of logs:
|
||||
|
||||
<pre><code>2013-05-17 23:06:40,918 INFO [chief-twitterstream] com.metamx.druid.realtime.plumber.RealtimePlumberSchool - Submitting persist runnable for dataSource[twitterstream]
|
||||
```
|
||||
2013-05-17 23:06:40,918 INFO [chief-twitterstream] com.metamx.druid.realtime.plumber.RealtimePlumberSchool - Submitting persist runnable for dataSource[twitterstream]
|
||||
2013-05-17 23:06:40,920 INFO [twitterstream-incremental-persist] com.metamx.druid.realtime.plumber.RealtimePlumberSchool - DataSource[twitterstream], Interval[2013-05-17T23:00:00.000Z/2013-05-18T00:00:00.000Z], persisting Hydrant[FireHydrant{index=com.metamx.druid.index.v1.IncrementalIndex@126212dd, queryable=com.metamx.druid.index.IncrementalIndexSegment@64c47498, count=0}]
|
||||
2013-05-17 23:06:40,937 INFO [twitterstream-incremental-persist] com.metamx.druid.index.v1.IndexMerger - Starting persist for interval[2013-05-17T23:00:00.000Z/2013-05-17T23:07:00.000Z], rows[4,666]
|
||||
2013-05-17 23:06:41,039 INFO [twitterstream-incremental-persist] com.metamx.druid.index.v1.IndexMerger - outDir[/tmp/example/twitter_realtime/basePersist/twitterstream/2013-05-17T23:00:00.000Z_2013-05-18T00:00:00.000Z/0/v8-tmp] completed index.drd in 11 millis.
|
||||
|
|
@ -88,16 +104,20 @@ These messages indicate you are ingesting events. The Druid real time-node inges
|
|||
2013-05-17 23:06:41,425 INFO [twitterstream-incremental-persist] com.metamx.druid.index.v1.IndexIO$DefaultIndexIOHandler - Converting v8[/tmp/example/twitter_realtime/basePersist/twitterstream/2013-05-17T23:00:00.000Z_2013-05-18T00:00:00.000Z/0/v8-tmp] to v9[/tmp/example/twitter_realtime/basePersist/twitterstream/2013-05-17T23:00:00.000Z_2013-05-18T00:00:00.000Z/0]
|
||||
2013-05-17 23:06:41,426 INFO [twitterstream-incremental-persist]
|
||||
... ETC
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
The logs are about building different columns, probably not the most exciting stuff (they might as well be in Vulcan) if are you learning about Druid for the first time. Nevertheless, if you are interested in the details of our real-time architecture and why we persist indexes to disk, I suggest you read our "White Paper":http://static.druid.io/docs/druid.pdf.
|
||||
|
||||
Okay, things are about to get real (-time). To query the real-time node you've spun up, you can issue:
|
||||
<pre>./run_example_client.sh</pre>
|
||||
|
||||
Select "twitter" once again. This script issues ["GroupByQuery":GroupByQuery.html]s to the twitter data we've been ingesting. The query looks like this:
|
||||
```
|
||||
./run_example_client.sh
|
||||
```
|
||||
|
||||
<pre><code>{
|
||||
Select "twitter" once again. This script issues [GroupByQueries](GroupByQuery.html) to the twitter data we've been ingesting. The query looks like this:
|
||||
|
||||
```json
|
||||
{
|
||||
"queryType": "groupBy",
|
||||
"dataSource": "twitterstream",
|
||||
"granularity": "all",
|
||||
|
|
@ -109,13 +129,14 @@ Select "twitter" once again. This script issues ["GroupByQuery":GroupByQuery.htm
|
|||
"filter": { "type": "selector", "dimension": "lang", "value": "en" },
|
||||
"intervals":["2012-10-01T00:00/2020-01-01T00"]
|
||||
}
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
This is a **groupBy** query, which you may be familiar with from SQL. We are grouping, or aggregating, via the **dimensions** field: ["lang", "utc_offset"]. We are **filtering** via the **"lang"** dimension, to only look at english tweets. Our **aggregations** are what we are calculating: a row count, and the sum of the tweets in our data.
|
||||
|
||||
The result looks something like this:
|
||||
|
||||
<pre><code>[
|
||||
```json
|
||||
[
|
||||
{
|
||||
"version": "v1",
|
||||
"timestamp": "2012-10-01T00:00:00.000Z",
|
||||
|
|
@ -137,41 +158,48 @@ The result looks something like this:
|
|||
}
|
||||
},
|
||||
...
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
This data, plotted in a time series/distribution, looks something like this:
|
||||
|
||||
!http://metamarkets.com/wp-content/uploads/2013/06/tweets_timezone_offset.png(Timezone / Tweets Scatter Plot)!
|
||||
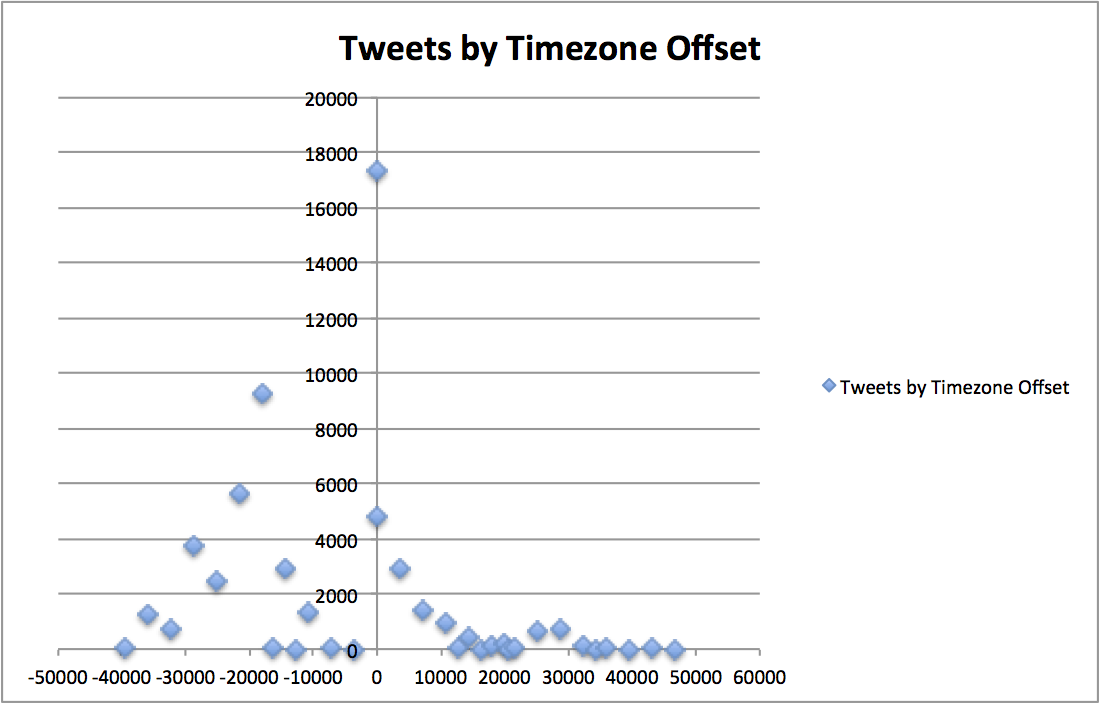
|
||||
|
||||
This groupBy query is a bit complicated and we'll return to it later. For the time being, just make sure you are getting some blocks of data back. If you are having problems, make sure you have "curl":http://curl.haxx.se/ installed. Control+C to break out of the client script.
|
||||
This groupBy query is a bit complicated and we'll return to it later. For the time being, just make sure you are getting some blocks of data back. If you are having problems, make sure you have [curl](http://curl.haxx.se/) installed. Control+C to break out of the client script.
|
||||
|
||||
h2. Querying Druid
|
||||
# Querying Druid
|
||||
|
||||
In your favorite editor, create the file:
|
||||
<pre>time_boundary_query.body</pre>
|
||||
|
||||
```
|
||||
time_boundary_query.body
|
||||
```
|
||||
|
||||
Druid queries are JSON blobs which are relatively painless to create programmatically, but an absolute pain to write by hand. So anyway, we are going to create a Druid query by hand. Add the following to the file you just created:
|
||||
<pre><code>{
|
||||
|
||||
```json
|
||||
{
|
||||
"queryType" : "timeBoundary",
|
||||
"dataSource" : "twitterstream"
|
||||
}
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
The "TimeBoundaryQuery":TimeBoundaryQuery.html is one of the simplest Druid queries. To run the query, you can issue:
|
||||
<pre><code>
|
||||
|
||||
```
|
||||
curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @time_boundary_query.body
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
We get something like this JSON back:
|
||||
|
||||
<pre><code>[ {
|
||||
```json
|
||||
{
|
||||
"timestamp" : "2013-06-10T19:09:00.000Z",
|
||||
"result" : {
|
||||
"minTime" : "2013-06-10T19:09:00.000Z",
|
||||
"maxTime" : "2013-06-10T20:50:00.000Z"
|
||||
}
|
||||
} ]
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
That's the result. What information do you think the result is conveying?
|
||||
...
|
||||
|
|
@ -179,11 +207,14 @@ If you said the result is indicating the maximum and minimum timestamps we've se
|
|||
|
||||
Return to your favorite editor and create the file:
|
||||
|
||||
<pre>timeseries_query.body</pre>
|
||||
```
|
||||
timeseries_query.body
|
||||
```
|
||||
|
||||
We are going to make a slightly more complicated query, the "TimeseriesQuery":TimeseriesQuery.html. Copy and paste the following into the file:
|
||||
We are going to make a slightly more complicated query, the [TimeseriesQuery](TimeseriesQuery.html). Copy and paste the following into the file:
|
||||
|
||||
<pre><code>{
|
||||
```json
|
||||
{
|
||||
"queryType":"timeseries",
|
||||
"dataSource":"twitterstream",
|
||||
"intervals":["2010-01-01/2020-01-01"],
|
||||
|
|
@ -193,22 +224,26 @@ We are going to make a slightly more complicated query, the "TimeseriesQuery":Ti
|
|||
{ "type": "doubleSum", "fieldName": "tweets", "name": "tweets"}
|
||||
]
|
||||
}
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
You are probably wondering, what are these "Granularities":Granularities.html and "Aggregations":Aggregations.html things? What the query is doing is aggregating some metrics over some span of time.
|
||||
You are probably wondering, what are these [Granularities](Granularities.html) and [Aggregations](Aggregations.html) things? What the query is doing is aggregating some metrics over some span of time.
|
||||
To issue the query and get some results, run the following in your command line:
|
||||
<pre><code>curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @timeseries_query.body</code></pre>
|
||||
|
||||
```
|
||||
curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @timeseries_query.body
|
||||
```
|
||||
|
||||
Once again, you should get a JSON blob of text back with your results, that looks something like this:
|
||||
|
||||
<pre><code>[ {
|
||||
```json
|
||||
[ {
|
||||
"timestamp" : "2013-06-10T19:09:00.000Z",
|
||||
"result" : {
|
||||
"tweets" : 358562.0,
|
||||
"rows" : 272271
|
||||
}
|
||||
} ]
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
If you issue the query again, you should notice your results updating.
|
||||
|
||||
|
|
@ -216,7 +251,8 @@ Right now all the results you are getting back are being aggregated into a singl
|
|||
|
||||
If you loudly exclaimed "we can change granularity to minute", you are absolutely correct again! We can specify different granularities to bucket our results, like so:
|
||||
|
||||
<pre><code>{
|
||||
```json
|
||||
{
|
||||
"queryType":"timeseries",
|
||||
"dataSource":"twitterstream",
|
||||
"intervals":["2010-01-01/2020-01-01"],
|
||||
|
|
@ -226,11 +262,12 @@ If you loudly exclaimed "we can change granularity to minute", you are absolutel
|
|||
{ "type": "doubleSum", "fieldName": "tweets", "name": "tweets"}
|
||||
]
|
||||
}
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
This gives us something like the following:
|
||||
|
||||
<pre><code>[ {
|
||||
```json
|
||||
[ {
|
||||
"timestamp" : "2013-06-10T19:09:00.000Z",
|
||||
"result" : {
|
||||
"tweets" : 2650.0,
|
||||
|
|
@ -250,16 +287,21 @@ This gives us something like the following:
|
|||
}
|
||||
},
|
||||
...
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
h2. Solving a Problem
|
||||
# Solving a Problem
|
||||
|
||||
One of Druid's main powers (see what we did there?) is to provide answers to problems, so let's pose a problem. What if we wanted to know what the top hash tags are, ordered by the number tweets, where the language is english, over the last few minutes you've been reading this tutorial? To solve this problem, we have to return to the query we introduced at the very beginning of this tutorial, the "GroupByQuery":GroupByQuery.html. It would be nice if we could group by results by dimension value and somehow sort those results... and it turns out we can!
|
||||
|
||||
Let's create the file:
|
||||
<pre>group_by_query.body</pre>
|
||||
|
||||
```
|
||||
group_by_query.body
|
||||
```
|
||||
and put the following in there:
|
||||
<pre><code>{
|
||||
|
||||
```json
|
||||
{
|
||||
"queryType": "groupBy",
|
||||
"dataSource": "twitterstream",
|
||||
"granularity": "all",
|
||||
|
|
@ -271,16 +313,20 @@ and put the following in there:
|
|||
"filter": {"type": "selector", "dimension": "lang", "value": "en" },
|
||||
"intervals":["2012-10-01T00:00/2020-01-01T00"]
|
||||
}
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
Woah! Our query just got a way more complicated. Now we have these "Filters":Filters.html things and this "OrderBy":OrderBy.html thing. Fear not, it turns out the new objects we've introduced to our query can help define the format of our results and provide an answer to our question.
|
||||
|
||||
If you issue the query:
|
||||
<pre><code>curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @group_by_query.body</code></pre>
|
||||
|
||||
```
|
||||
curl -X POST 'http://localhost:8080/druid/v2/?pretty' -H 'content-type: application/json' -d @group_by_query.body
|
||||
```
|
||||
|
||||
You should hopefully see an answer to our question. For my twitter stream, it looks like this:
|
||||
|
||||
<pre><code>[ {
|
||||
```json
|
||||
[ {
|
||||
"version" : "v1",
|
||||
"timestamp" : "2012-10-01T00:00:00.000Z",
|
||||
"event" : {
|
||||
|
|
@ -316,12 +362,12 @@ You should hopefully see an answer to our question. For my twitter stream, it lo
|
|||
"htags" : "IDidntTextYouBackBecause"
|
||||
}
|
||||
} ]
|
||||
</code></pre>
|
||||
```
|
||||
|
||||
Feel free to tweak other query parameters to answer other questions you may have about the data.
|
||||
|
||||
h2. Additional Information
|
||||
# Additional Information
|
||||
|
||||
This tutorial is merely showcasing a small fraction of what Druid can do. Next, continue on to "The Druid Cluster":./Tutorial:-The-Druid-Cluster.html.
|
||||
This tutorial is merely showcasing a small fraction of what Druid can do. Next, continue on to [The Druid Cluster](./Tutorial:-The-Druid-Cluster.html).
|
||||
|
||||
And thus concludes our journey! Hopefully you learned a thing or two about Druid real-time ingestion, querying Druid, and how Druid can be used to solve problems. If you have additional questions, feel free to post in our "google groups page":http://www.groups.google.com/forum/#!forum/druid-development.
|
||||
And thus concludes our journey! Hopefully you learned a thing or two about Druid real-time ingestion, querying Druid, and how Druid can be used to solve problems. If you have additional questions, feel free to post in our [google groups page](http://www.groups.google.com/forum/#!forum/druid-development).
|
||||
|
|
@ -22,12 +22,6 @@ h2. Configuration
|
|||
* "Broker":Broker-Config.html
|
||||
* "Indexing Service":Indexing-Service-Config.html
|
||||
|
||||
h2. Operations
|
||||
* "Extending Druid":./Modules.html
|
||||
* "Cluster Setup":./Cluster-setup.html
|
||||
* "Booting a Production Cluster":./Booting-a-production-cluster.html
|
||||
* "Performance FAQ":./Performance-FAQ.html
|
||||
|
||||
h2. Data Ingestion
|
||||
* "Realtime":./Realtime-ingestion.html
|
||||
* "Batch":./Batch-ingestion.html
|
||||
|
|
@ -36,6 +30,12 @@ h2. Data Ingestion
|
|||
* "Data Formats":./Data_formats.html
|
||||
* "Ingestion FAQ":./Ingestion-FAQ.html
|
||||
|
||||
h2. Operations
|
||||
* "Extending Druid":./Modules.html
|
||||
* "Cluster Setup":./Cluster-setup.html
|
||||
* "Booting a Production Cluster":./Booting-a-production-cluster.html
|
||||
* "Performance FAQ":./Performance-FAQ.html
|
||||
|
||||
h2. Querying
|
||||
* "Querying":./Querying.html
|
||||
** "Filters":./Filters.html
|
||||
|
|
@ -75,6 +75,7 @@ h2. Architecture
|
|||
h2. Experimental
|
||||
* "About Experimental Features":./About-Experimental-Features.html
|
||||
* "Geographic Queries":./GeographicQueries.html
|
||||
* "Select Query":./SelectQuery.html
|
||||
|
||||
h2. Development
|
||||
* "Versioning":./Versioning.html
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ druid.port=8081
|
|||
|
||||
druid.zk.service.host=localhost
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-s3-extensions:0.6.101"]
|
||||
|
||||
# Dummy read only AWS account (used to download example data)
|
||||
druid.s3.secretKey=QyyfVZ7llSiRg6Qcrql1eEUG7buFpAK6T6engr1b
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ druid.port=8083
|
|||
|
||||
druid.zk.service.host=localhost
|
||||
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.81","io.druid.extensions:druid-kafka-seven:0.6.81","io.druid.extensions:druid-rabbitmq:0.6.81"]
|
||||
druid.extensions.coordinates=["io.druid.extensions:druid-examples:0.6.101","io.druid.extensions:druid-kafka-seven:0.6.101","io.druid.extensions:druid-rabbitmq:0.6.101"]
|
||||
|
||||
# Change this config to db to hand off to the rest of the Druid cluster
|
||||
druid.publish.type=noop
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
@ -58,6 +58,11 @@
|
|||
<artifactId>twitter4j-stream</artifactId>
|
||||
<version>3.0.3</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>commons-validator</groupId>
|
||||
<artifactId>commons-validator</artifactId>
|
||||
<version>1.4.0</version>
|
||||
</dependency>
|
||||
|
||||
<!-- For tests! -->
|
||||
<dependency>
|
||||
|
|
@ -82,14 +87,14 @@
|
|||
${project.build.directory}/${project.artifactId}-${project.version}-selfcontained.jar
|
||||
</outputFile>
|
||||
<filters>
|
||||
<filter>
|
||||
<artifact>*:*</artifact>
|
||||
<excludes>
|
||||
<exclude>META-INF/*.SF</exclude>
|
||||
<exclude>META-INF/*.DSA</exclude>
|
||||
<exclude>META-INF/*.RSA</exclude>
|
||||
</excludes>
|
||||
</filter>
|
||||
<filter>
|
||||
<artifact>*:*</artifact>
|
||||
<excludes>
|
||||
<exclude>META-INF/*.SF</exclude>
|
||||
<exclude>META-INF/*.DSA</exclude>
|
||||
<exclude>META-INF/*.RSA</exclude>
|
||||
</excludes>
|
||||
</filter>
|
||||
</filters>
|
||||
</configuration>
|
||||
</execution>
|
||||
|
|
|
|||
|
|
@ -19,8 +19,11 @@
|
|||
|
||||
package io.druid.examples.web;
|
||||
|
||||
import com.google.api.client.repackaged.com.google.common.base.Throwables;
|
||||
import com.google.common.base.Preconditions;
|
||||
import com.google.common.io.InputSupplier;
|
||||
import com.metamx.emitter.EmittingLogger;
|
||||
import org.apache.commons.validator.routines.UrlValidator;
|
||||
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
|
|
@ -31,25 +34,25 @@ import java.net.URLConnection;
|
|||
public class WebJsonSupplier implements InputSupplier<BufferedReader>
|
||||
{
|
||||
private static final EmittingLogger log = new EmittingLogger(WebJsonSupplier.class);
|
||||
private static final UrlValidator urlValidator = new UrlValidator();
|
||||
|
||||
private String urlString;
|
||||
private URL url;
|
||||
|
||||
public WebJsonSupplier(String urlString)
|
||||
{
|
||||
this.urlString = urlString;
|
||||
Preconditions.checkState(urlValidator.isValid(urlString));
|
||||
|
||||
try {
|
||||
this.url = new URL(urlString);
|
||||
}
|
||||
catch (Exception e) {
|
||||
log.error(e,"Malformed url");
|
||||
throw Throwables.propagate(e);
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
public BufferedReader getInput() throws IOException
|
||||
{
|
||||
URL url = new URL(urlString);
|
||||
URLConnection connection = url.openConnection();
|
||||
connection.setDoInput(true);
|
||||
return new BufferedReader(new InputStreamReader(url.openStream()));
|
||||
|
|
|
|||
|
|
@ -22,15 +22,14 @@ package io.druid.examples.web;
|
|||
import org.junit.Test;
|
||||
|
||||
import java.io.IOException;
|
||||
import java.net.MalformedURLException;
|
||||
|
||||
public class WebJsonSupplierTest
|
||||
{
|
||||
@Test(expected = IOException.class)
|
||||
@Test(expected = IllegalStateException.class)
|
||||
public void checkInvalidUrl() throws Exception
|
||||
{
|
||||
|
||||
String invalidURL = "http://invalid.url.";
|
||||
WebJsonSupplier supplier = new WebJsonSupplier(invalidURL);
|
||||
supplier.getInput();
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
@ -52,7 +52,7 @@
|
|||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.hadoop</groupId>
|
||||
<artifactId>hadoop-core</artifactId>
|
||||
<artifactId>hadoop-client</artifactId>
|
||||
<scope>compile</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
@ -67,7 +67,7 @@
|
|||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.hadoop</groupId>
|
||||
<artifactId>hadoop-core</artifactId>
|
||||
<artifactId>hadoop-client</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.fasterxml.jackson.core</groupId>
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@ import com.google.common.collect.ImmutableMap;
|
|||
import com.metamx.common.logger.Logger;
|
||||
import io.druid.db.DbConnector;
|
||||
import io.druid.timeline.DataSegment;
|
||||
import io.druid.timeline.partition.NoneShardSpec;
|
||||
import org.joda.time.DateTime;
|
||||
import org.skife.jdbi.v2.Handle;
|
||||
import org.skife.jdbi.v2.IDBI;
|
||||
|
|
@ -39,13 +40,15 @@ public class DbUpdaterJob implements Jobby
|
|||
|
||||
private final HadoopDruidIndexerConfig config;
|
||||
private final IDBI dbi;
|
||||
private final DbConnector dbConnector;
|
||||
|
||||
public DbUpdaterJob(
|
||||
HadoopDruidIndexerConfig config
|
||||
)
|
||||
{
|
||||
this.config = config;
|
||||
this.dbi = new DbConnector(config.getUpdaterJobSpec(), null).getDBI();
|
||||
this.dbConnector = new DbConnector(config.getUpdaterJobSpec(), null);
|
||||
this.dbi = this.dbConnector.getDBI();
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
@ -61,8 +64,11 @@ public class DbUpdaterJob implements Jobby
|
|||
{
|
||||
final PreparedBatch batch = handle.prepareBatch(
|
||||
String.format(
|
||||
"INSERT INTO %s (id, dataSource, created_date, start, end, partitioned, version, used, payload) "
|
||||
+ "VALUES (:id, :dataSource, :created_date, :start, :end, :partitioned, :version, :used, :payload)",
|
||||
dbConnector.isPostgreSQL() ?
|
||||
"INSERT INTO %s (id, dataSource, created_date, start, \"end\", partitioned, version, used, payload) "
|
||||
+ "VALUES (:id, :dataSource, :created_date, :start, :end, :partitioned, :version, :used, :payload)" :
|
||||
"INSERT INTO %s (id, dataSource, created_date, start, end, partitioned, version, used, payload) "
|
||||
+ "VALUES (:id, :dataSource, :created_date, :start, :end, :partitioned, :version, :used, :payload)",
|
||||
config.getUpdaterJobSpec().getSegmentTable()
|
||||
)
|
||||
);
|
||||
|
|
@ -75,7 +81,7 @@ public class DbUpdaterJob implements Jobby
|
|||
.put("created_date", new DateTime().toString())
|
||||
.put("start", segment.getInterval().getStart().toString())
|
||||
.put("end", segment.getInterval().getEnd().toString())
|
||||
.put("partitioned", segment.getShardSpec().getPartitionNum())
|
||||
.put("partitioned", (segment.getShardSpec() instanceof NoneShardSpec) ? 0 : 1)
|
||||
.put("version", segment.getVersion())
|
||||
.put("used", true)
|
||||
.put("payload", HadoopDruidIndexerConfig.jsonMapper.writeValueAsString(segment))
|
||||
|
|
|
|||
|
|
@ -37,6 +37,7 @@ import io.druid.indexer.granularity.UniformGranularitySpec;
|
|||
import io.druid.query.aggregation.hyperloglog.HyperLogLogCollector;
|
||||
import io.druid.timeline.partition.HashBasedNumberedShardSpec;
|
||||
import io.druid.timeline.partition.NoneShardSpec;
|
||||
import org.apache.hadoop.conf.Configurable;
|
||||
import org.apache.hadoop.conf.Configuration;
|
||||
import org.apache.hadoop.fs.FileSystem;
|
||||
import org.apache.hadoop.fs.Path;
|
||||
|
|
@ -45,6 +46,7 @@ import org.apache.hadoop.io.LongWritable;
|
|||
import org.apache.hadoop.io.NullWritable;
|
||||
import org.apache.hadoop.io.Text;
|
||||
import org.apache.hadoop.mapreduce.Job;
|
||||
import org.apache.hadoop.mapreduce.Partitioner;
|
||||
import org.apache.hadoop.mapreduce.Reducer;
|
||||
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
|
||||
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
|
||||
|
|
@ -65,7 +67,6 @@ import java.util.Set;
|
|||
*/
|
||||
public class DetermineHashedPartitionsJob implements Jobby
|
||||
{
|
||||
private static final int MAX_SHARDS = 128;
|
||||
private static final Logger log = new Logger(DetermineHashedPartitionsJob.class);
|
||||
private final HadoopDruidIndexerConfig config;
|
||||
|
||||
|
|
@ -98,8 +99,11 @@ public class DetermineHashedPartitionsJob implements Jobby
|
|||
groupByJob.setOutputKeyClass(NullWritable.class);
|
||||
groupByJob.setOutputValueClass(NullWritable.class);
|
||||
groupByJob.setOutputFormatClass(SequenceFileOutputFormat.class);
|
||||
groupByJob.setPartitionerClass(DetermineHashedPartitionsPartitioner.class);
|
||||
if (!config.getSegmentGranularIntervals().isPresent()) {
|
||||
groupByJob.setNumReduceTasks(1);
|
||||
} else {
|
||||
groupByJob.setNumReduceTasks(config.getSegmentGranularIntervals().get().size());
|
||||
}
|
||||
JobHelper.setupClasspath(config, groupByJob);
|
||||
|
||||
|
|
@ -124,9 +128,6 @@ public class DetermineHashedPartitionsJob implements Jobby
|
|||
if (!config.getSegmentGranularIntervals().isPresent()) {
|
||||
final Path intervalInfoPath = config.makeIntervalInfoPath();
|
||||
fileSystem = intervalInfoPath.getFileSystem(groupByJob.getConfiguration());
|
||||
if (!fileSystem.exists(intervalInfoPath)) {
|
||||
throw new ISE("Path[%s] didn't exist!?", intervalInfoPath);
|
||||
}
|
||||
List<Interval> intervals = config.jsonMapper.readValue(
|
||||
Utils.openInputStream(groupByJob, intervalInfoPath), new TypeReference<List<Interval>>()
|
||||
{
|
||||
|
|
@ -144,37 +145,25 @@ public class DetermineHashedPartitionsJob implements Jobby
|
|||
if (fileSystem == null) {
|
||||
fileSystem = partitionInfoPath.getFileSystem(groupByJob.getConfiguration());
|
||||
}
|
||||
if (fileSystem.exists(partitionInfoPath)) {
|
||||
Long cardinality = config.jsonMapper.readValue(
|
||||
Utils.openInputStream(groupByJob, partitionInfoPath), new TypeReference<Long>()
|
||||
{
|
||||
}
|
||||
);
|
||||
int numberOfShards = (int) Math.ceil((double) cardinality / config.getTargetPartitionSize());
|
||||
|
||||
if (numberOfShards > MAX_SHARDS) {
|
||||
throw new ISE(
|
||||
"Number of shards [%d] exceed the maximum limit of [%d], either targetPartitionSize is too low or data volume is too high",
|
||||
numberOfShards,
|
||||
MAX_SHARDS
|
||||
);
|
||||
}
|
||||
|
||||
List<HadoopyShardSpec> actualSpecs = Lists.newArrayListWithExpectedSize(numberOfShards);
|
||||
if (numberOfShards == 1) {
|
||||
actualSpecs.add(new HadoopyShardSpec(new NoneShardSpec(), shardCount++));
|
||||
} else {
|
||||
for (int i = 0; i < numberOfShards; ++i) {
|
||||
actualSpecs.add(new HadoopyShardSpec(new HashBasedNumberedShardSpec(i, numberOfShards), shardCount++));
|
||||
log.info("DateTime[%s], partition[%d], spec[%s]", bucket, i, actualSpecs.get(i));
|
||||
}
|
||||
}
|
||||
|
||||
shardSpecs.put(bucket, actualSpecs);
|
||||
|
||||
} else {
|
||||
log.info("Path[%s] didn't exist!?", partitionInfoPath);
|
||||
final Long cardinality = config.jsonMapper.readValue(
|
||||
Utils.openInputStream(groupByJob, partitionInfoPath), new TypeReference<Long>()
|
||||
{
|
||||
}
|
||||
);
|
||||
final int numberOfShards = (int) Math.ceil((double) cardinality / config.getTargetPartitionSize());
|
||||
|
||||
List<HadoopyShardSpec> actualSpecs = Lists.newArrayListWithExpectedSize(numberOfShards);
|
||||
if (numberOfShards == 1) {
|
||||
actualSpecs.add(new HadoopyShardSpec(new NoneShardSpec(), shardCount++));
|
||||
} else {
|
||||
for (int i = 0; i < numberOfShards; ++i) {
|
||||
actualSpecs.add(new HadoopyShardSpec(new HashBasedNumberedShardSpec(i, numberOfShards), shardCount++));
|
||||
log.info("DateTime[%s], partition[%d], spec[%s]", bucket, i, actualSpecs.get(i));
|
||||
}
|
||||
}
|
||||
|
||||
shardSpecs.put(bucket, actualSpecs);
|
||||
|
||||
}
|
||||
config.setShardSpecs(shardSpecs);
|
||||
log.info(
|
||||
|
|
@ -319,13 +308,6 @@ public class DetermineHashedPartitionsJob implements Jobby
|
|||
}
|
||||
}
|
||||
|
||||
private byte[] getDataBytes(BytesWritable writable)
|
||||
{
|
||||
byte[] rv = new byte[writable.getLength()];
|
||||
System.arraycopy(writable.getBytes(), 0, rv, 0, writable.getLength());
|
||||
return rv;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void run(Context context)
|
||||
throws IOException, InterruptedException
|
||||
|
|
@ -353,6 +335,50 @@ public class DetermineHashedPartitionsJob implements Jobby
|
|||
}
|
||||
}
|
||||
}
|
||||
|
||||
public static class DetermineHashedPartitionsPartitioner
|
||||
extends Partitioner<LongWritable, BytesWritable> implements Configurable
|
||||
{
|
||||
private Configuration config;
|
||||
private boolean determineIntervals;
|
||||
private Map<LongWritable, Integer> reducerLookup;
|
||||
|
||||
@Override
|
||||
public int getPartition(LongWritable interval, BytesWritable text, int numPartitions)
|
||||
{
|
||||
|
||||
if (config.get("mapred.job.tracker").equals("local") || determineIntervals) {
|
||||
return 0;
|
||||
} else {
|
||||
return reducerLookup.get(interval);
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
public Configuration getConf()
|
||||
{
|
||||
return config;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setConf(Configuration config)
|
||||
{
|
||||
this.config = config;
|
||||
HadoopDruidIndexerConfig hadoopConfig = HadoopDruidIndexerConfigBuilder.fromConfiguration(config);
|
||||
if (hadoopConfig.getSegmentGranularIntervals().isPresent()) {
|
||||
determineIntervals = false;
|
||||
int reducerNumber = 0;
|
||||
ImmutableMap.Builder<LongWritable, Integer> builder = ImmutableMap.builder();
|
||||
for (Interval interval : hadoopConfig.getSegmentGranularIntervals().get()) {
|
||||
builder.put(new LongWritable(interval.getStartMillis()), reducerNumber++);
|
||||
}
|
||||
reducerLookup = builder.build();
|
||||
} else {
|
||||
determineIntervals = true;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -215,23 +215,20 @@ public class DeterminePartitionsJob implements Jobby
|
|||
if (fileSystem == null) {
|
||||
fileSystem = partitionInfoPath.getFileSystem(dimSelectionJob.getConfiguration());
|
||||
}
|
||||
if (fileSystem.exists(partitionInfoPath)) {
|
||||
List<ShardSpec> specs = config.jsonMapper.readValue(
|
||||
Utils.openInputStream(dimSelectionJob, partitionInfoPath), new TypeReference<List<ShardSpec>>()
|
||||
{
|
||||
}
|
||||
);
|
||||
|
||||
List<HadoopyShardSpec> actualSpecs = Lists.newArrayListWithExpectedSize(specs.size());
|
||||
for (int i = 0; i < specs.size(); ++i) {
|
||||
actualSpecs.add(new HadoopyShardSpec(specs.get(i), shardCount++));
|
||||
log.info("DateTime[%s], partition[%d], spec[%s]", segmentGranularity, i, actualSpecs.get(i));
|
||||
}
|
||||
|
||||
shardSpecs.put(segmentGranularity.getStart(), actualSpecs);
|
||||
} else {
|
||||
log.info("Path[%s] didn't exist!?", partitionInfoPath);
|
||||
List<ShardSpec> specs = config.jsonMapper.readValue(
|
||||
Utils.openInputStream(dimSelectionJob, partitionInfoPath), new TypeReference<List<ShardSpec>>()
|
||||
{
|
||||
}
|
||||
);
|
||||
|
||||
List<HadoopyShardSpec> actualSpecs = Lists.newArrayListWithExpectedSize(specs.size());
|
||||
for (int i = 0; i < specs.size(); ++i) {
|
||||
actualSpecs.add(new HadoopyShardSpec(specs.get(i), shardCount++));
|
||||
log.info("DateTime[%s], partition[%d], spec[%s]", segmentGranularity, i, actualSpecs.get(i));
|
||||
}
|
||||
|
||||
shardSpecs.put(segmentGranularity.getStart(), actualSpecs);
|
||||
|
||||
}
|
||||
config.setShardSpecs(shardSpecs);
|
||||
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@ import com.google.common.collect.Lists;
|
|||
import com.google.common.collect.Maps;
|
||||
import com.google.inject.Inject;
|
||||
import com.metamx.common.logger.Logger;
|
||||
import io.druid.timeline.partition.HashBasedNumberedShardSpec;
|
||||
import io.druid.timeline.partition.NoneShardSpec;
|
||||
import org.joda.time.DateTime;
|
||||
import org.joda.time.DateTimeComparator;
|
||||
|
|
@ -56,13 +57,28 @@ public class HadoopDruidDetermineConfigurationJob implements Jobby
|
|||
if (config.isDeterminingPartitions()) {
|
||||
jobs.add(config.getPartitionsSpec().getPartitionJob(config));
|
||||
} else {
|
||||
int shardsPerInterval = config.getPartitionsSpec().getNumShards();
|
||||
Map<DateTime, List<HadoopyShardSpec>> shardSpecs = Maps.newTreeMap(DateTimeComparator.getInstance());
|
||||
int shardCount = 0;
|
||||
for (Interval segmentGranularity : config.getSegmentGranularIntervals().get()) {
|
||||
DateTime bucket = segmentGranularity.getStart();
|
||||
final HadoopyShardSpec spec = new HadoopyShardSpec(new NoneShardSpec(), shardCount++);
|
||||
shardSpecs.put(bucket, Lists.newArrayList(spec));
|
||||
log.info("DateTime[%s], spec[%s]", bucket, spec);
|
||||
if (shardsPerInterval > 0) {
|
||||
List<HadoopyShardSpec> specs = Lists.newArrayListWithCapacity(shardsPerInterval);
|
||||
for (int i = 0; i < shardsPerInterval; i++) {
|
||||
specs.add(
|
||||
new HadoopyShardSpec(
|
||||
new HashBasedNumberedShardSpec(i, shardsPerInterval),
|
||||
shardCount++
|
||||
)
|
||||
);
|
||||
}
|
||||
shardSpecs.put(bucket, specs);
|
||||
log.info("DateTime[%s], spec[%s]", bucket, specs);
|
||||
} else {
|
||||
final HadoopyShardSpec spec = new HadoopyShardSpec(new NoneShardSpec(), shardCount++);
|
||||
shardSpecs.put(bucket, Lists.newArrayList(spec));
|
||||
log.info("DateTime[%s], spec[%s]", bucket, spec);
|
||||
}
|
||||
}
|
||||
config.setShardSpecs(shardSpecs);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -20,6 +20,7 @@
|
|||
package io.druid.indexer.partitions;
|
||||
|
||||
import com.fasterxml.jackson.annotation.JsonProperty;
|
||||
import com.google.common.base.Preconditions;
|
||||
|
||||
|
||||
public abstract class AbstractPartitionsSpec implements PartitionsSpec
|
||||
|
|
@ -28,11 +29,13 @@ public abstract class AbstractPartitionsSpec implements PartitionsSpec
|
|||
private final long targetPartitionSize;
|
||||
private final long maxPartitionSize;
|
||||
private final boolean assumeGrouped;
|
||||
private final int numShards;
|
||||
|
||||
public AbstractPartitionsSpec(
|
||||
Long targetPartitionSize,
|
||||
Long maxPartitionSize,
|
||||
Boolean assumeGrouped
|
||||
Boolean assumeGrouped,
|
||||
Integer numShards
|
||||
)
|
||||
{
|
||||
this.targetPartitionSize = targetPartitionSize == null ? -1 : targetPartitionSize;
|
||||
|
|
@ -40,6 +43,11 @@ public abstract class AbstractPartitionsSpec implements PartitionsSpec
|
|||
? (long) (this.targetPartitionSize * DEFAULT_OVERSIZE_THRESHOLD)
|
||||
: maxPartitionSize;
|
||||
this.assumeGrouped = assumeGrouped == null ? false : assumeGrouped;
|
||||
this.numShards = numShards == null ? -1 : numShards;
|
||||
Preconditions.checkArgument(
|
||||
this.targetPartitionSize == -1 || this.numShards == -1,
|
||||
"targetPartitionsSize and shardCount both cannot be set"
|
||||
);
|
||||
}
|
||||
|
||||
@JsonProperty
|
||||
|
|
@ -65,4 +73,10 @@ public abstract class AbstractPartitionsSpec implements PartitionsSpec
|
|||
{
|
||||
return targetPartitionSize > 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getNumShards()
|
||||
{
|
||||
return numShards;
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -33,10 +33,11 @@ public class HashedPartitionsSpec extends AbstractPartitionsSpec
|
|||
public HashedPartitionsSpec(
|
||||
@JsonProperty("targetPartitionSize") @Nullable Long targetPartitionSize,
|
||||
@JsonProperty("maxPartitionSize") @Nullable Long maxPartitionSize,
|
||||
@JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped
|
||||
@JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped,
|
||||
@JsonProperty("numShards") @Nullable Integer numShards
|
||||
)
|
||||
{
|
||||
super(targetPartitionSize, maxPartitionSize, assumeGrouped);
|
||||
super(targetPartitionSize, maxPartitionSize, assumeGrouped, numShards);
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
|
|||
|
|
@ -49,4 +49,7 @@ public interface PartitionsSpec
|
|||
@JsonIgnore
|
||||
public boolean isDeterminingPartitions();
|
||||
|
||||
@JsonProperty
|
||||
public int getNumShards();
|
||||
|
||||
}
|
||||
|
|
|
|||
|
|
@ -21,9 +21,6 @@ package io.druid.indexer.partitions;
|
|||
|
||||
import com.fasterxml.jackson.annotation.JsonCreator;
|
||||
import com.fasterxml.jackson.annotation.JsonProperty;
|
||||
import io.druid.indexer.DetermineHashedPartitionsJob;
|
||||
import io.druid.indexer.HadoopDruidIndexerConfig;
|
||||
import io.druid.indexer.Jobby;
|
||||
|
||||
import javax.annotation.Nullable;
|
||||
|
||||
|
|
@ -35,9 +32,10 @@ public class RandomPartitionsSpec extends HashedPartitionsSpec
|
|||
public RandomPartitionsSpec(
|
||||
@JsonProperty("targetPartitionSize") @Nullable Long targetPartitionSize,
|
||||
@JsonProperty("maxPartitionSize") @Nullable Long maxPartitionSize,
|
||||
@JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped
|
||||
@JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped,
|
||||
@JsonProperty("numShards") @Nullable Integer numShards
|
||||
)
|
||||
{
|
||||
super(targetPartitionSize, maxPartitionSize, assumeGrouped);
|
||||
super(targetPartitionSize, maxPartitionSize, assumeGrouped, numShards);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -41,7 +41,7 @@ public class SingleDimensionPartitionsSpec extends AbstractPartitionsSpec
|
|||
@JsonProperty("assumeGrouped") @Nullable Boolean assumeGrouped
|
||||
)
|
||||
{
|
||||
super(targetPartitionSize, maxPartitionSize, assumeGrouped);
|
||||
super(targetPartitionSize, maxPartitionSize, assumeGrouped, null);
|
||||
this.partitionDimension = partitionDimension;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -216,10 +216,10 @@ public class HadoopDruidIndexerConfigTest
|
|||
150
|
||||
);
|
||||
|
||||
Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof SingleDimensionPartitionsSpec);
|
||||
Assert.assertTrue("partitionsSpec", partitionsSpec instanceof SingleDimensionPartitionsSpec);
|
||||
Assert.assertEquals(
|
||||
"getPartitionDimension",
|
||||
((SingleDimensionPartitionsSpec)partitionsSpec).getPartitionDimension(),
|
||||
((SingleDimensionPartitionsSpec) partitionsSpec).getPartitionDimension(),
|
||||
"foo"
|
||||
);
|
||||
}
|
||||
|
|
@ -262,10 +262,10 @@ public class HadoopDruidIndexerConfigTest
|
|||
150
|
||||
);
|
||||
|
||||
Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof SingleDimensionPartitionsSpec);
|
||||
Assert.assertTrue("partitionsSpec", partitionsSpec instanceof SingleDimensionPartitionsSpec);
|
||||
Assert.assertEquals(
|
||||
"getPartitionDimension",
|
||||
((SingleDimensionPartitionsSpec)partitionsSpec).getPartitionDimension(),
|
||||
((SingleDimensionPartitionsSpec) partitionsSpec).getPartitionDimension(),
|
||||
"foo"
|
||||
);
|
||||
}
|
||||
|
|
@ -311,10 +311,10 @@ public class HadoopDruidIndexerConfigTest
|
|||
200
|
||||
);
|
||||
|
||||
Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof SingleDimensionPartitionsSpec);
|
||||
Assert.assertTrue("partitionsSpec", partitionsSpec instanceof SingleDimensionPartitionsSpec);
|
||||
Assert.assertEquals(
|
||||
"getPartitionDimension",
|
||||
((SingleDimensionPartitionsSpec)partitionsSpec).getPartitionDimension(),
|
||||
((SingleDimensionPartitionsSpec) partitionsSpec).getPartitionDimension(),
|
||||
"foo"
|
||||
);
|
||||
}
|
||||
|
|
@ -503,7 +503,8 @@ public class HadoopDruidIndexerConfigTest
|
|||
}
|
||||
|
||||
@Test
|
||||
public void testRandomPartitionsSpec() throws Exception{
|
||||
public void testRandomPartitionsSpec() throws Exception
|
||||
{
|
||||
{
|
||||
final HadoopDruidIndexerConfig cfg;
|
||||
|
||||
|
|
@ -542,12 +543,13 @@ public class HadoopDruidIndexerConfigTest
|
|||
150
|
||||
);
|
||||
|
||||
Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof RandomPartitionsSpec);
|
||||
Assert.assertTrue("partitionsSpec", partitionsSpec instanceof RandomPartitionsSpec);
|
||||
}
|
||||
}
|
||||
|
||||
@Test
|
||||
public void testHashedPartitionsSpec() throws Exception{
|
||||
public void testHashedPartitionsSpec() throws Exception
|
||||
{
|
||||
{
|
||||
final HadoopDruidIndexerConfig cfg;
|
||||
|
||||
|
|
@ -586,7 +588,57 @@ public class HadoopDruidIndexerConfigTest
|
|||
150
|
||||
);
|
||||
|
||||
Assert.assertTrue("partitionsSpec" , partitionsSpec instanceof HashedPartitionsSpec);
|
||||
Assert.assertTrue("partitionsSpec", partitionsSpec instanceof HashedPartitionsSpec);
|
||||
}
|
||||
}
|
||||
|
||||
@Test
|
||||
public void testHashedPartitionsSpecShardCount() throws Exception
|
||||
{
|
||||
final HadoopDruidIndexerConfig cfg;
|
||||
|
||||
try {
|
||||
cfg = jsonReadWriteRead(
|
||||
"{"
|
||||
+ "\"partitionsSpec\":{"
|
||||
+ " \"type\":\"hashed\","
|
||||
+ " \"numShards\":2"
|
||||
+ " }"
|
||||
+ "}",
|
||||
HadoopDruidIndexerConfig.class
|
||||
);
|
||||
}
|
||||
catch (Exception e) {
|
||||
throw Throwables.propagate(e);
|
||||
}
|
||||
|
||||
final PartitionsSpec partitionsSpec = cfg.getPartitionsSpec();
|
||||
|
||||
Assert.assertEquals(
|
||||
"isDeterminingPartitions",
|
||||
partitionsSpec.isDeterminingPartitions(),
|
||||
false
|
||||
);
|
||||
|
||||
Assert.assertEquals(
|
||||
"getTargetPartitionSize",
|
||||
partitionsSpec.getTargetPartitionSize(),
|
||||
-1
|
||||
);
|
||||
|
||||
Assert.assertEquals(
|
||||
"getMaxPartitionSize",
|
||||
partitionsSpec.getMaxPartitionSize(),
|
||||
-1
|
||||
);
|
||||
|
||||
Assert.assertEquals(
|
||||
"shardCount",
|
||||
partitionsSpec.getNumShards(),
|
||||
2
|
||||
);
|
||||
|
||||
Assert.assertTrue("partitionsSpec", partitionsSpec instanceof HashedPartitionsSpec);
|
||||
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
@ -71,7 +71,7 @@
|
|||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.hadoop</groupId>
|
||||
<artifactId>hadoop-core</artifactId>
|
||||
<artifactId>hadoop-client</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
|
|
|
|||
|
|
@ -64,7 +64,7 @@ public abstract class AbstractTask implements Task
|
|||
this.id = Preconditions.checkNotNull(id, "id");
|
||||
this.groupId = Preconditions.checkNotNull(groupId, "groupId");
|
||||
this.taskResource = Preconditions.checkNotNull(taskResource, "resource");
|
||||
this.dataSource = Preconditions.checkNotNull(dataSource, "dataSource");
|
||||
this.dataSource = Preconditions.checkNotNull(dataSource.toLowerCase(), "dataSource");
|
||||
}
|
||||
|
||||
@JsonProperty
|
||||
|
|
|
|||
|
|
@ -66,7 +66,8 @@ public class HadoopIndexTask extends AbstractTask
|
|||
extensionsConfig = Initialization.makeStartupInjector().getInstance(ExtensionsConfig.class);
|
||||
}
|
||||
|
||||
private static String defaultHadoopCoordinates = "org.apache.hadoop:hadoop-core:1.0.3";
|
||||
public static String DEFAULT_HADOOP_COORDINATES = "org.apache.hadoop:hadoop-client:2.3.0";
|
||||
|
||||
@JsonIgnore
|
||||
private final HadoopDruidIndexerSchema schema;
|
||||
@JsonIgnore
|
||||
|
|
@ -102,7 +103,7 @@ public class HadoopIndexTask extends AbstractTask
|
|||
|
||||
this.schema = schema;
|
||||
this.hadoopDependencyCoordinates = hadoopDependencyCoordinates == null ? Arrays.<String>asList(
|
||||
hadoopCoordinates == null ? defaultHadoopCoordinates : hadoopCoordinates
|
||||
hadoopCoordinates == null ? DEFAULT_HADOOP_COORDINATES : hadoopCoordinates
|
||||
) : hadoopDependencyCoordinates;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -33,6 +33,7 @@ import io.druid.db.DbTablesConfig;
|
|||
import io.druid.timeline.DataSegment;
|
||||
import io.druid.timeline.TimelineObjectHolder;
|
||||
import io.druid.timeline.VersionedIntervalTimeline;
|
||||
import io.druid.timeline.partition.NoneShardSpec;
|
||||
import org.joda.time.DateTime;
|
||||
import org.joda.time.Interval;
|
||||
import org.skife.jdbi.v2.FoldController;
|
||||
|
|
@ -193,7 +194,7 @@ public class IndexerDBCoordinator
|
|||
.bind("created_date", new DateTime().toString())
|
||||
.bind("start", segment.getInterval().getStart().toString())
|
||||
.bind("end", segment.getInterval().getEnd().toString())
|
||||
.bind("partitioned", segment.getShardSpec().getPartitionNum())
|
||||
.bind("partitioned", (segment.getShardSpec() instanceof NoneShardSpec) ? 0 : 1)
|
||||
.bind("version", segment.getVersion())
|
||||
.bind("used", true)
|
||||
.bind("payload", jsonMapper.writeValueAsString(segment))
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
|
|||
28
pom.xml
28
pom.xml
|
|
@ -23,14 +23,14 @@
|
|||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<packaging>pom</packaging>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
<name>druid</name>
|
||||
<description>druid</description>
|
||||
<scm>
|
||||
<connection>scm:git:ssh://git@github.com/metamx/druid.git</connection>
|
||||
<developerConnection>scm:git:ssh://git@github.com/metamx/druid.git</developerConnection>
|
||||
<url>http://www.github.com/metamx/druid</url>
|
||||
<tag>druid-0.6.81-SNAPSHOT</tag>
|
||||
<tag>druid-0.6.100-SNAPSHOT</tag>
|
||||
</scm>
|
||||
|
||||
<prerequisites>
|
||||
|
|
@ -39,7 +39,7 @@
|
|||
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<metamx.java-util.version>0.25.3</metamx.java-util.version>
|
||||
<metamx.java-util.version>0.25.4</metamx.java-util.version>
|
||||
<apache.curator.version>2.4.0</apache.curator.version>
|
||||
<druid.api.version>0.1.11</druid.api.version>
|
||||
</properties>
|
||||
|
|
@ -74,12 +74,12 @@
|
|||
<dependency>
|
||||
<groupId>com.metamx</groupId>
|
||||
<artifactId>emitter</artifactId>
|
||||
<version>0.2.9</version>
|
||||
<version>0.2.11</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.metamx</groupId>
|
||||
<artifactId>http-client</artifactId>
|
||||
<version>0.8.5</version>
|
||||
<version>0.9.2</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.metamx</groupId>
|
||||
|
|
@ -174,6 +174,12 @@
|
|||
<groupId>org.apache.curator</groupId>
|
||||
<artifactId>curator-framework</artifactId>
|
||||
<version>${apache.curator.version}</version>
|
||||
<exclusions>
|
||||
<exclusion>
|
||||
<groupId>org.jboss.netty</groupId>
|
||||
<artifactId>netty</artifactId>
|
||||
</exclusion>
|
||||
</exclusions>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.curator</groupId>
|
||||
|
|
@ -313,17 +319,17 @@
|
|||
<dependency>
|
||||
<groupId>org.eclipse.jetty</groupId>
|
||||
<artifactId>jetty-server</artifactId>
|
||||
<version>9.1.3.v20140225</version>
|
||||
<version>9.1.4.v20140401</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.eclipse.jetty</groupId>
|
||||
<artifactId>jetty-servlet</artifactId>
|
||||
<version>9.1.3.v20140225</version>
|
||||
<version>9.1.4.v20140401</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.eclipse.jetty</groupId>
|
||||
<artifactId>jetty-servlets</artifactId>
|
||||
<version>9.1.3.v20140225</version>
|
||||
<version>9.1.4.v20140401</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>joda-time</groupId>
|
||||
|
|
@ -373,7 +379,7 @@
|
|||
<dependency>
|
||||
<groupId>com.google.protobuf</groupId>
|
||||
<artifactId>protobuf-java</artifactId>
|
||||
<version>2.4.0a</version>
|
||||
<version>2.5.0</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>io.tesla.aether</groupId>
|
||||
|
|
@ -402,8 +408,8 @@
|
|||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.apache.hadoop</groupId>
|
||||
<artifactId>hadoop-core</artifactId>
|
||||
<version>1.0.3</version>
|
||||
<artifactId>hadoop-client</artifactId>
|
||||
<version>2.3.0</version>
|
||||
<scope>provided</scope>
|
||||
</dependency>
|
||||
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
<parent>
|
||||
<groupId>io.druid</groupId>
|
||||
<artifactId>druid</artifactId>
|
||||
<version>0.6.83-SNAPSHOT</version>
|
||||
<version>0.6.102-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@ import com.fasterxml.jackson.annotation.JsonProperty;
|
|||
import com.google.common.base.Preconditions;
|
||||
import com.google.common.collect.ImmutableMap;
|
||||
import com.google.common.collect.Maps;
|
||||
import com.metamx.common.ISE;
|
||||
import com.metamx.common.guava.Sequence;
|
||||
import io.druid.query.spec.QuerySegmentSpec;
|
||||
import org.joda.time.Duration;
|
||||
|
|
@ -120,6 +121,67 @@ public abstract class BaseQuery<T> implements Query<T>
|
|||
return retVal == null ? defaultValue : retVal;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getContextPriority(int defaultValue)
|
||||
{
|
||||
if (context == null) {
|
||||
return defaultValue;
|
||||
}
|
||||
Object val = context.get("priority");
|
||||
if (val == null) {
|
||||
return defaultValue;
|
||||
}
|
||||
if (val instanceof String) {
|
||||
return Integer.parseInt((String) val);
|
||||
} else if (val instanceof Integer) {
|
||||
return (int) val;
|
||||
} else {
|
||||
throw new ISE("Unknown type [%s]", val.getClass());
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean getContextBySegment(boolean defaultValue)
|
||||
{
|
||||
return parseBoolean("bySegment", defaultValue);
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean getContextPopulateCache(boolean defaultValue)
|
||||
{
|
||||
return parseBoolean("populateCache", defaultValue);
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean getContextUseCache(boolean defaultValue)
|
||||
{
|
||||
return parseBoolean("useCache", defaultValue);
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean getContextFinalize(boolean defaultValue)
|
||||
{
|
||||
return parseBoolean("finalize", defaultValue);
|
||||
}
|
||||
|
||||
private boolean parseBoolean(String key, boolean defaultValue)
|
||||
{
|
||||
if (context == null) {
|
||||
return defaultValue;
|
||||
}
|
||||
Object val = context.get(key);
|
||||
if (val == null) {
|
||||
return defaultValue;
|
||||
}
|
||||
if (val instanceof String) {
|
||||
return Boolean.parseBoolean((String) val);
|
||||
} else if (val instanceof Boolean) {
|
||||
return (boolean) val;
|
||||
} else {
|
||||
throw new ISE("Unknown type [%s]. Cannot parse!", val.getClass());
|
||||
}
|
||||
}
|
||||
|
||||
protected Map<String, Object> computeOverridenContext(Map<String, Object> overrides)
|
||||
{
|
||||
Map<String, Object> overridden = Maps.newTreeMap();
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ public class BySegmentQueryRunner<T> implements QueryRunner<T>
|
|||
@SuppressWarnings("unchecked")
|
||||
public Sequence<T> run(final Query<T> query)
|
||||
{
|
||||
if (Boolean.parseBoolean(query.<String>getContextValue("bySegment"))) {
|
||||
if (query.getContextBySegment(false)) {
|
||||
final Sequence<T> baseSequence = base.run(query);
|
||||
return new Sequence<T>()
|
||||
{
|
||||
|
|
|
|||
|
|
@ -64,10 +64,44 @@ public class BySegmentResultValueClass<T>
|
|||
@Override
|
||||
public String toString()
|
||||
{
|
||||
return "BySegmentTimeseriesResultValue{" +
|
||||
return "BySegmentResultValue{" +
|
||||
"results=" + results +
|
||||
", segmentId='" + segmentId + '\'' +
|
||||
", interval='" + interval + '\'' +
|
||||
'}';
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean equals(Object o)
|
||||
{
|
||||
if (this == o) {
|
||||
return true;
|
||||
}
|
||||
if (o == null || getClass() != o.getClass()) {
|
||||
return false;
|
||||
}
|
||||
|
||||
BySegmentResultValueClass that = (BySegmentResultValueClass) o;
|
||||
|
||||
if (interval != null ? !interval.equals(that.interval) : that.interval != null) {
|
||||
return false;
|
||||
}
|
||||
if (results != null ? !results.equals(that.results) : that.results != null) {
|
||||
return false;
|
||||
}
|
||||
if (segmentId != null ? !segmentId.equals(that.segmentId) : that.segmentId != null) {
|
||||
return false;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int hashCode()
|
||||
{
|
||||
int result = results != null ? results.hashCode() : 0;
|
||||
result = 31 * result + (segmentId != null ? segmentId.hashCode() : 0);
|
||||
result = 31 * result + (interval != null ? interval.hashCode() : 0);
|
||||
return result;
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ public abstract class BySegmentSkippingQueryRunner<T> implements QueryRunner<T>
|
|||
@Override
|
||||
public Sequence<T> run(Query<T> query)
|
||||
{
|
||||
if (Boolean.parseBoolean(query.<String>getContextValue("bySegment"))) {
|
||||
if (query.getContextBySegment(false)) {
|
||||
return baseRunner.run(query);
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -35,8 +35,10 @@ import com.metamx.common.logger.Logger;
|
|||
import java.util.Arrays;
|
||||
import java.util.Iterator;
|
||||
import java.util.List;
|
||||
import java.util.concurrent.Callable;
|
||||
import java.util.concurrent.ExecutionException;
|
||||
import java.util.concurrent.ExecutorService;
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.Future;
|
||||
|
||||
/**
|
||||
|
|
@ -83,7 +85,7 @@ public class ChainedExecutionQueryRunner<T> implements QueryRunner<T>
|
|||
@Override
|
||||
public Sequence<T> run(final Query<T> query)
|
||||
{
|
||||
final int priority = Integer.parseInt((String) query.getContextValue("priority", "0"));
|
||||
final int priority = query.getContextPriority(0);
|
||||
|
||||
return new BaseSequence<T, Iterator<T>>(
|
||||
new BaseSequence.IteratorMaker<T, Iterator<T>>()
|
||||
|
|
@ -110,7 +112,18 @@ public class ChainedExecutionQueryRunner<T> implements QueryRunner<T>
|
|||
if (input == null) {
|
||||
throw new ISE("Input is null?! How is this possible?!");
|
||||
}
|
||||
return Sequences.toList(input.run(query), Lists.<T>newArrayList());
|
||||
|
||||
Sequence<T> result = input.run(query);
|
||||
if (result == null) {
|
||||
throw new ISE("Got a null result! Segments are missing!");
|
||||
}
|
||||
|
||||
List<T> retVal = Sequences.toList(result, Lists.<T>newArrayList());
|
||||
if (retVal == null) {
|
||||
throw new ISE("Got a null list of results! WTF?!");
|
||||
}
|
||||
|
||||
return retVal;
|
||||
}
|
||||
catch (Exception e) {
|
||||
log.error(e, "Exception with one of the sequences!");
|
||||
|
|
|
|||
|
|
@ -24,7 +24,8 @@ import com.google.common.collect.ImmutableMap;
|
|||
import com.google.common.collect.Lists;
|
||||
import com.metamx.common.guava.Sequence;
|
||||
import com.metamx.common.guava.Sequences;
|
||||
import io.druid.query.aggregation.AggregatorFactory;
|
||||
import io.druid.query.aggregation.FinalizeMetricManipulationFn;
|
||||
import io.druid.query.aggregation.IdentityMetricManipulationFn;
|
||||
import io.druid.query.aggregation.MetricManipulationFn;
|
||||
|
||||
import javax.annotation.Nullable;
|
||||
|
|
@ -48,62 +49,55 @@ public class FinalizeResultsQueryRunner<T> implements QueryRunner<T>
|
|||
@Override
|
||||
public Sequence<T> run(final Query<T> query)
|
||||
{
|
||||
final boolean isBySegment = Boolean.parseBoolean(query.<String>getContextValue("bySegment"));
|
||||
final boolean shouldFinalize = Boolean.parseBoolean(query.getContextValue("finalize", "true"));
|
||||
final boolean isBySegment = query.getContextBySegment(false);
|
||||
final boolean shouldFinalize = query.getContextFinalize(true);
|
||||
|
||||
final Query<T> queryToRun;
|
||||
final Function<T, T> finalizerFn;
|
||||
final MetricManipulationFn metricManipulationFn;
|
||||
|
||||
if (shouldFinalize) {
|
||||
Function<T, T> finalizerFn;
|
||||
if (isBySegment) {
|
||||
finalizerFn = new Function<T, T>()
|
||||
{
|
||||
final Function<T, T> baseFinalizer = toolChest.makeMetricManipulatorFn(
|
||||
query,
|
||||
new MetricManipulationFn()
|
||||
{
|
||||
@Override
|
||||
public Object manipulate(AggregatorFactory factory, Object object)
|
||||
{
|
||||
return factory.finalizeComputation(factory.deserialize(object));
|
||||
}
|
||||
}
|
||||
);
|
||||
queryToRun = query.withOverriddenContext(ImmutableMap.<String, Object>of("finalize", false));
|
||||
metricManipulationFn = new FinalizeMetricManipulationFn();
|
||||
|
||||
@Override
|
||||
@SuppressWarnings("unchecked")
|
||||
public T apply(@Nullable T input)
|
||||
{
|
||||
Result<BySegmentResultValueClass<T>> result = (Result<BySegmentResultValueClass<T>>) input;
|
||||
BySegmentResultValueClass<T> resultsClass = result.getValue();
|
||||
|
||||
return (T) new Result<BySegmentResultValueClass>(
|
||||
result.getTimestamp(),
|
||||
new BySegmentResultValueClass(
|
||||
Lists.transform(resultsClass.getResults(), baseFinalizer),
|
||||
resultsClass.getSegmentId(),
|
||||
resultsClass.getInterval()
|
||||
)
|
||||
);
|
||||
}
|
||||
};
|
||||
}
|
||||
else {
|
||||
finalizerFn = toolChest.makeMetricManipulatorFn(
|
||||
query,
|
||||
new MetricManipulationFn()
|
||||
{
|
||||
@Override
|
||||
public Object manipulate(AggregatorFactory factory, Object object)
|
||||
{
|
||||
return factory.finalizeComputation(object);
|
||||
}
|
||||
}
|
||||
);
|
||||
}
|
||||
|
||||
return Sequences.map(
|
||||
baseRunner.run(query.withOverriddenContext(ImmutableMap.<String, Object>of("finalize", "false"))),
|
||||
finalizerFn
|
||||
);
|
||||
} else {
|
||||
queryToRun = query;
|
||||
metricManipulationFn = new IdentityMetricManipulationFn();
|
||||
}
|
||||
return baseRunner.run(query);
|
||||
if (isBySegment) {
|
||||
finalizerFn = new Function<T, T>()
|
||||
{
|
||||
final Function<T, T> baseFinalizer = toolChest.makePostComputeManipulatorFn(
|
||||
query,
|
||||
metricManipulationFn
|
||||
);
|
||||
|
||||
@Override
|
||||
@SuppressWarnings("unchecked")
|
||||
public T apply(@Nullable T input)
|
||||
{
|
||||
Result<BySegmentResultValueClass<T>> result = (Result<BySegmentResultValueClass<T>>) input;
|
||||
BySegmentResultValueClass<T> resultsClass = result.getValue();
|
||||
|
||||
return (T) new Result<BySegmentResultValueClass>(
|
||||
result.getTimestamp(),
|
||||
new BySegmentResultValueClass(
|
||||
Lists.transform(resultsClass.getResults(), baseFinalizer),
|
||||
resultsClass.getSegmentId(),
|
||||
resultsClass.getInterval()
|
||||
)
|
||||
);
|
||||
}
|
||||
};
|
||||
} else {
|
||||
finalizerFn = toolChest.makePostComputeManipulatorFn(query, metricManipulationFn);
|
||||
}
|
||||
|
||||
|
||||
return Sequences.map(
|
||||
baseRunner.run(queryToRun),
|
||||
finalizerFn
|
||||
);
|
||||
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -83,7 +83,7 @@ public class GroupByParallelQueryRunner implements QueryRunner<Row>
|
|||
query,
|
||||
configSupplier.get()
|
||||
);
|
||||
final int priority = Integer.parseInt((String) query.getContextValue("priority", "0"));
|
||||
final int priority = query.getContextPriority(0);
|
||||
|
||||
if (Iterables.isEmpty(queryables)) {
|
||||
log.warn("No queryables found.");
|
||||
|
|
|
|||
|
|
@ -74,6 +74,13 @@ public interface Query<T>
|
|||
|
||||
public <ContextType> ContextType getContextValue(String key, ContextType defaultValue);
|
||||
|
||||
// For backwards compatibility
|
||||
@Deprecated public int getContextPriority(int defaultValue);
|
||||
@Deprecated public boolean getContextBySegment(boolean defaultValue);
|
||||
@Deprecated public boolean getContextPopulateCache(boolean defaultValue);
|
||||
@Deprecated public boolean getContextUseCache(boolean defaultValue);
|
||||
@Deprecated public boolean getContextFinalize(boolean defaultValue);
|
||||
|
||||
public Query<T> withOverriddenContext(Map<String, Object> contextOverride);
|
||||
|
||||
public Query<T> withQuerySegmentSpec(QuerySegmentSpec spec);
|
||||
|
|
|
|||
|
|
@ -44,8 +44,16 @@ public abstract class QueryToolChest<ResultType, QueryType extends Query<ResultT
|
|||
* @return
|
||||
*/
|
||||
public abstract Sequence<ResultType> mergeSequences(Sequence<Sequence<ResultType>> seqOfSequences);
|
||||
|
||||
public abstract ServiceMetricEvent.Builder makeMetricBuilder(QueryType query);
|
||||
public abstract Function<ResultType, ResultType> makeMetricManipulatorFn(QueryType query, MetricManipulationFn fn);
|
||||
|
||||
public abstract Function<ResultType, ResultType> makePreComputeManipulatorFn(QueryType query, MetricManipulationFn fn);
|
||||
|
||||
public Function<ResultType, ResultType> makePostComputeManipulatorFn(QueryType query, MetricManipulationFn fn)
|
||||
{
|
||||
return makePreComputeManipulatorFn(query, fn);
|
||||
}
|
||||
|
||||
public abstract TypeReference<ResultType> getResultTypeReference();
|
||||
|
||||
public <T> CacheStrategy<ResultType, T, QueryType> getCacheStrategy(QueryType query) {
|
||||
|
|
|
|||
|
|
@ -0,0 +1,85 @@
|
|||
/*
|
||||
* Druid - a distributed column store.
|
||||
* Copyright (C) 2012, 2013, 2014 Metamarkets Group Inc.
|
||||
*
|
||||
* This program is free software; you can redistribute it and/or
|
||||
* modify it under the terms of the GNU General Public License
|
||||
* as published by the Free Software Foundation; either version 2
|
||||
* of the License, or (at your option) any later version.
|
||||
*
|
||||
* This program is distributed in the hope that it will be useful,
|
||||
* but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
* GNU General Public License for more details.
|
||||
*
|
||||
* You should have received a copy of the GNU General Public License
|
||||
* along with this program; if not, write to the Free Software
|
||||
* Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
|
||||
*/
|
||||
|
||||
package io.druid.query.aggregation;
|
||||
|
||||
import com.google.common.collect.Lists;
|
||||
import com.metamx.common.ISE;
|
||||
import com.metamx.common.Pair;
|
||||
|
||||
import java.util.HashSet;
|
||||
import java.util.LinkedList;
|
||||
import java.util.List;
|
||||
import java.util.Set;
|
||||
|
||||
public class AggregatorUtil
|
||||
{
|
||||
/**
|
||||
* returns the list of dependent postAggregators that should be calculated in order to calculate given postAgg
|
||||
*
|
||||
* @param postAggregatorList List of postAggregator, there is a restriction that the list should be in an order
|
||||
* such that all the dependencies of any given aggregator should occur before that aggregator.
|
||||
* See AggregatorUtilTest.testOutOfOrderPruneDependentPostAgg for example.
|
||||
* @param postAggName name of the postAgg on which dependency is to be calculated
|
||||
*/
|
||||
public static List<PostAggregator> pruneDependentPostAgg(List<PostAggregator> postAggregatorList, String postAggName)
|
||||
{
|
||||
LinkedList<PostAggregator> rv = Lists.newLinkedList();
|
||||
Set<String> deps = new HashSet<>();
|
||||
deps.add(postAggName);
|
||||
// Iterate backwards to find the last calculated aggregate and add dependent aggregator as we find dependencies in reverse order
|
||||
for (PostAggregator agg : Lists.reverse(postAggregatorList)) {
|
||||
if (deps.contains(agg.getName())) {
|
||||
rv.addFirst(agg); // add to the beginning of List
|
||||
deps.remove(agg.getName());
|
||||
deps.addAll(agg.getDependentFields());
|
||||
}
|
||||
}
|
||||
|
||||
return rv;
|
||||
}
|
||||
|
||||
public static Pair<List<AggregatorFactory>, List<PostAggregator>> condensedAggregators(
|
||||
List<AggregatorFactory> aggList,
|
||||
List<PostAggregator> postAggList,
|
||||
String metric
|
||||
)
|
||||
{
|
||||
|
||||
List<PostAggregator> condensedPostAggs = AggregatorUtil.pruneDependentPostAgg(
|
||||
postAggList,
|
||||
metric
|
||||
);
|
||||
// calculate dependent aggregators for these postAgg
|
||||
Set<String> dependencySet = new HashSet<>();
|
||||
dependencySet.add(metric);
|
||||
for (PostAggregator postAggregator : condensedPostAggs) {
|
||||
dependencySet.addAll(postAggregator.getDependentFields());
|
||||
}
|
||||
|
||||
List<AggregatorFactory> condensedAggs = Lists.newArrayList();
|
||||
for (AggregatorFactory aggregatorSpec : aggList) {
|
||||
if (dependencySet.contains(aggregatorSpec.getName())) {
|
||||
condensedAggs.add(aggregatorSpec);
|
||||
}
|
||||
}
|
||||
return new Pair(condensedAggs, condensedPostAggs);
|
||||
}
|
||||
|
||||
}
|
||||
|
|
@ -88,6 +88,10 @@ public class DoubleSumAggregatorFactory implements AggregatorFactory
|
|||
@Override
|
||||
public Object deserialize(Object object)
|
||||
{
|
||||
// handle "NaN" / "Infinity" values serialized as strings in JSON
|
||||
if (object instanceof String) {
|
||||
return Double.parseDouble((String) object);
|
||||
}
|
||||
return object;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,31 @@
|
|||
/*
|
||||
* Druid - a distributed column store.
|
||||
* Copyright (C) 2012, 2013 Metamarkets Group Inc.
|
||||
*
|
||||
* This program is free software; you can redistribute it and/or
|
||||
* modify it under the terms of the GNU General Public License
|
||||
* as published by the Free Software Foundation; either version 2
|
||||
* of the License, or (at your option) any later version.
|
||||
*
|
||||
* This program is distributed in the hope that it will be useful,
|
||||
* but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
* GNU General Public License for more details.
|
||||
*
|
||||
* You should have received a copy of the GNU General Public License
|
||||
* along with this program; if not, write to the Free Software
|
||||
* Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
|
||||
*/
|
||||
|
||||
package io.druid.query.aggregation;
|
||||
|
||||
/**
|
||||
*/
|
||||
public class FinalizeMetricManipulationFn implements MetricManipulationFn
|
||||
{
|
||||
@Override
|
||||
public Object manipulate(AggregatorFactory factory, Object object)
|
||||
{
|
||||
return factory.finalizeComputation(object);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
/*
|
||||
* Druid - a distributed column store.
|
||||
* Copyright (C) 2012, 2013 Metamarkets Group Inc.
|
||||
*
|
||||
* This program is free software; you can redistribute it and/or
|
||||
* modify it under the terms of the GNU General Public License
|
||||
* as published by the Free Software Foundation; either version 2
|
||||
* of the License, or (at your option) any later version.
|
||||
*
|
||||
* This program is distributed in the hope that it will be useful,
|
||||
* but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
* GNU General Public License for more details.
|
||||
*
|
||||
* You should have received a copy of the GNU General Public License
|
||||
* along with this program; if not, write to the Free Software
|
||||
* Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
|
||||
*/
|
||||
|
||||
package io.druid.query.aggregation;
|
||||
|
||||
/**
|
||||
*/
|
||||
public class IdentityMetricManipulationFn implements MetricManipulationFn
|
||||
{
|
||||
@Override
|
||||
public Object manipulate(AggregatorFactory factory, Object object)
|
||||
{
|
||||
return object;
|
||||
}
|
||||
}
|
||||
|
|
@ -139,6 +139,10 @@ public class JavaScriptAggregatorFactory implements AggregatorFactory
|
|||
@Override
|
||||
public Object deserialize(Object object)
|
||||
{
|
||||
// handle "NaN" / "Infinity" values serialized as strings in JSON
|
||||
if (object instanceof String) {
|
||||
return Double.parseDouble((String) object);
|
||||
}
|
||||
return object;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -85,6 +85,7 @@ public class MaxAggregatorFactory implements AggregatorFactory
|
|||
@Override
|
||||
public Object deserialize(Object object)
|
||||
{
|
||||
// handle "NaN" / "Infinity" values serialized as strings in JSON
|
||||
if (object instanceof String) {
|
||||
return Double.parseDouble((String) object);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -85,6 +85,7 @@ public class MinAggregatorFactory implements AggregatorFactory
|
|||
@Override
|
||||
public Object deserialize(Object object)
|
||||
{
|
||||
// handle "NaN" / "Infinity" values serialized as strings in JSON
|
||||
if (object instanceof String) {
|
||||
return Double.parseDouble((String) object);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -326,27 +326,26 @@ public abstract class HyperLogLogCollector implements Comparable<HyperLogLogColl
|
|||
convertToMutableByteBuffer();
|
||||
}
|
||||
|
||||
if (storageBuffer.remaining() != getNumBytesForDenseStorage()) {
|
||||
convertToDenseStorage();
|
||||
}
|
||||
|
||||
estimatedCardinality = null;
|
||||
|
||||
if (getRegisterOffset() < other.getRegisterOffset()) {
|
||||
// "Swap" the buffers so that we are folding into the one with the higher offset
|
||||
ByteBuffer newStorage = ByteBuffer.allocateDirect(other.storageBuffer.remaining());
|
||||
newStorage.put(other.storageBuffer.asReadOnlyBuffer());
|
||||
newStorage.clear();
|
||||
final ByteBuffer tmpBuffer = ByteBuffer.allocate(storageBuffer.remaining());
|
||||
tmpBuffer.put(storageBuffer.asReadOnlyBuffer());
|
||||
tmpBuffer.clear();
|
||||
|
||||
other.storageBuffer = storageBuffer;
|
||||
other.initPosition = initPosition;
|
||||
storageBuffer = newStorage;
|
||||
initPosition = 0;
|
||||
storageBuffer.duplicate().put(other.storageBuffer.asReadOnlyBuffer());
|
||||
|
||||
other = HyperLogLogCollector.makeCollector(tmpBuffer);
|
||||
}
|
||||
|
||||
final ByteBuffer otherBuffer = other.storageBuffer.asReadOnlyBuffer();
|
||||
final byte otherOffset = other.getRegisterOffset();
|
||||
|
||||
if (storageBuffer.remaining() != getNumBytesForDenseStorage()) {
|
||||
convertToDenseStorage();
|
||||
}
|
||||
|
||||
byte myOffset = getRegisterOffset();
|
||||
short numNonZero = getNumNonZeroRegisters();
|
||||
|
||||
|
|
@ -540,7 +539,7 @@ public abstract class HyperLogLogCollector implements Comparable<HyperLogLogColl
|
|||
|
||||
private void convertToMutableByteBuffer()
|
||||
{
|
||||
ByteBuffer tmpBuffer = ByteBuffer.allocateDirect(storageBuffer.remaining());
|
||||
ByteBuffer tmpBuffer = ByteBuffer.allocate(storageBuffer.remaining());
|
||||
tmpBuffer.put(storageBuffer.asReadOnlyBuffer());
|
||||
tmpBuffer.position(0);
|
||||
storageBuffer = tmpBuffer;
|
||||
|
|
@ -549,7 +548,7 @@ public abstract class HyperLogLogCollector implements Comparable<HyperLogLogColl
|
|||
|
||||
private void convertToDenseStorage()
|
||||
{
|
||||
ByteBuffer tmpBuffer = ByteBuffer.allocateDirect(getNumBytesForDenseStorage());
|
||||
ByteBuffer tmpBuffer = ByteBuffer.allocate(getNumBytesForDenseStorage());
|
||||
// put header
|
||||
setVersion(tmpBuffer);
|
||||
setRegisterOffset(tmpBuffer, getRegisterOffset());
|
||||
|
|
|
|||
|
|
@ -67,7 +67,7 @@ public class HyperUniquesBufferAggregator implements BufferAggregator
|
|||
public Object get(ByteBuffer buf, int position)
|
||||
{
|
||||
final int size = HyperLogLogCollector.getLatestNumBytesForDenseStorage();
|
||||
ByteBuffer dataCopyBuffer = ByteBuffer.allocateDirect(size);
|
||||
ByteBuffer dataCopyBuffer = ByteBuffer.allocate(size);
|
||||
ByteBuffer mutationBuffer = buf.duplicate();
|
||||
mutationBuffer.position(position);
|
||||
mutationBuffer.limit(position + size);
|
||||
|
|
|
|||
|
|
@ -79,17 +79,23 @@ public class HyperUniquesSerde extends ComplexMetricSerde
|
|||
@Override
|
||||
public HyperLogLogCollector extractValue(InputRow inputRow, String metricName)
|
||||
{
|
||||
HyperLogLogCollector collector = HyperLogLogCollector.makeLatestCollector();
|
||||
Object rawValue = inputRow.getRaw(metricName);
|
||||
|
||||
List<String> dimValues = inputRow.getDimension(metricName);
|
||||
if (dimValues == null) {
|
||||
if (rawValue instanceof HyperLogLogCollector) {
|
||||
return (HyperLogLogCollector) inputRow.getRaw(metricName);
|
||||
} else {
|
||||
HyperLogLogCollector collector = HyperLogLogCollector.makeLatestCollector();
|
||||
|
||||
List<String> dimValues = inputRow.getDimension(metricName);
|
||||
if (dimValues == null) {
|
||||
return collector;
|
||||
}
|
||||
|
||||
for (String dimensionValue : dimValues) {
|
||||
collector.add(hashFn.hashBytes(dimensionValue.getBytes(Charsets.UTF_8)).asBytes());
|
||||
}
|
||||
return collector;
|
||||
}
|
||||
|
||||
for (String dimensionValue : dimValues) {
|
||||
collector.add(hashFn.hashBytes(dimensionValue.getBytes(Charsets.UTF_8)).asBytes());
|
||||
}
|
||||
return collector;
|
||||
}
|
||||
};
|
||||
}
|
||||
|
|
|
|||
|
|
@ -67,4 +67,13 @@ public class JavaScriptDimFilter implements DimFilter
|
|||
.put(functionBytes)
|
||||
.array();
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString()
|
||||
{
|
||||
return "JavaScriptDimFilter{" +
|
||||
"dimension='" + dimension + '\'' +
|
||||
", function='" + function + '\'' +
|
||||
'}';
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -69,4 +69,13 @@ public class RegexDimFilter implements DimFilter
|
|||
.put(patternBytes)
|
||||
.array();
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString()
|
||||
{
|
||||
return "RegexDimFilter{" +
|
||||
"dimension='" + dimension + '\'' +
|
||||
", pattern='" + pattern + '\'' +
|
||||
'}';
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -64,9 +64,18 @@ public class SearchQueryDimFilter implements DimFilter
|
|||
final byte[] queryBytes = query.getCacheKey();
|
||||
|
||||
return ByteBuffer.allocate(1 + dimensionBytes.length + queryBytes.length)
|
||||
.put(DimFilterCacheHelper.SEARCH_QUERY_TYPE_ID)
|
||||
.put(dimensionBytes)
|
||||
.put(queryBytes)
|
||||
.array();
|
||||
.put(DimFilterCacheHelper.SEARCH_QUERY_TYPE_ID)
|
||||
.put(dimensionBytes)
|
||||
.put(queryBytes)
|
||||
.array();
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString()
|
||||
{
|
||||
return "SearchQueryDimFilter{" +
|
||||
"dimension='" + dimension + '\'' +
|
||||
", query=" + query +
|
||||
'}';
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -99,4 +99,13 @@ public class SpatialDimFilter implements DimFilter
|
|||
result = 31 * result + (bound != null ? bound.hashCode() : 0);
|
||||
return result;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString()
|
||||
{
|
||||
return "SpatialDimFilter{" +
|
||||
"dimension='" + dimension + '\'' +
|
||||
", bound=" + bound +
|
||||
'}';
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -44,6 +44,7 @@ import io.druid.query.aggregation.AggregatorFactory;
|
|||
import io.druid.query.aggregation.BufferAggregator;
|
||||
import io.druid.query.aggregation.PostAggregator;
|
||||
import io.druid.query.dimension.DimensionSpec;
|
||||
import io.druid.query.extraction.DimExtractionFn;
|
||||
import io.druid.segment.Cursor;
|
||||
import io.druid.segment.DimensionSelector;
|
||||
import io.druid.segment.StorageAdapter;
|
||||
|
|
@ -69,7 +70,7 @@ public class GroupByQueryEngine
|
|||
private final StupidPool<ByteBuffer> intermediateResultsBufferPool;
|
||||
|
||||
@Inject
|
||||
public GroupByQueryEngine (
|
||||
public GroupByQueryEngine(
|
||||
Supplier<GroupByQueryConfig> config,
|
||||
@Global StupidPool<ByteBuffer> intermediateResultsBufferPool
|
||||
)
|
||||
|
|
@ -80,6 +81,12 @@ public class GroupByQueryEngine
|
|||
|
||||
public Sequence<Row> process(final GroupByQuery query, StorageAdapter storageAdapter)
|
||||
{
|
||||
if (storageAdapter == null) {
|
||||
throw new ISE(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
|
||||
);
|
||||
}
|
||||
|
||||
final List<Interval> intervals = query.getQuerySegmentSpec().getIntervals();
|
||||
if (intervals.size() != 1) {
|
||||
throw new IAE("Should only have one interval, got[%s]", intervals);
|
||||
|
|
@ -182,12 +189,11 @@ public class GroupByQueryEngine
|
|||
|
||||
final DimensionSelector dimSelector = dims.get(0);
|
||||
final IndexedInts row = dimSelector.getRow();
|
||||
if (row.size() == 0) {
|
||||
if (row == null || row.size() == 0) {
|
||||
ByteBuffer newKey = key.duplicate();
|
||||
newKey.putInt(dimSelector.getValueCardinality());
|
||||
unaggregatedBuffers = updateValues(newKey, dims.subList(1, dims.size()));
|
||||
}
|
||||
else {
|
||||
} else {
|
||||
for (Integer dimValue : row) {
|
||||
ByteBuffer newKey = key.duplicate();
|
||||
newKey.putInt(dimValue);
|
||||
|
|
@ -201,8 +207,7 @@ public class GroupByQueryEngine
|
|||
retVal.addAll(unaggregatedBuffers);
|
||||
}
|
||||
return retVal;
|
||||
}
|
||||
else {
|
||||
} else {
|
||||
key.clear();
|
||||
Integer position = positions.get(key);
|
||||
int[] increments = positionMaintainer.getIncrements();
|
||||
|
|
@ -266,8 +271,7 @@ public class GroupByQueryEngine
|
|||
{
|
||||
if (nextVal > max) {
|
||||
return null;
|
||||
}
|
||||
else {
|
||||
} else {
|
||||
int retVal = (int) nextVal;
|
||||
nextVal += increment;
|
||||
return retVal;
|
||||
|
|
@ -398,9 +402,14 @@ public class GroupByQueryEngine
|
|||
ByteBuffer keyBuffer = input.getKey().duplicate();
|
||||
for (int i = 0; i < dimensions.size(); ++i) {
|
||||
final DimensionSelector dimSelector = dimensions.get(i);
|
||||
final DimExtractionFn fn = dimensionSpecs.get(i).getDimExtractionFn();
|
||||
final int dimVal = keyBuffer.getInt();
|
||||
if (dimSelector.getValueCardinality() != dimVal) {
|
||||
theEvent.put(dimNames.get(i), dimSelector.lookupName(dimVal));
|
||||
if (fn != null) {
|
||||
theEvent.put(dimNames.get(i), fn.apply(dimSelector.lookupName(dimVal)));
|
||||
} else {
|
||||
theEvent.put(dimNames.get(i), dimSelector.lookupName(dimVal));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -428,9 +437,10 @@ public class GroupByQueryEngine
|
|||
throw new UnsupportedOperationException();
|
||||
}
|
||||
|
||||
public void close() {
|
||||
public void close()
|
||||
{
|
||||
// cleanup
|
||||
for(BufferAggregator agg : aggregators) {
|
||||
for (BufferAggregator agg : aggregators) {
|
||||
agg.close();
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -173,7 +173,7 @@ public class GroupByQueryQueryToolChest extends QueryToolChest<Row, GroupByQuery
|
|||
}
|
||||
|
||||
@Override
|
||||
public Function<Row, Row> makeMetricManipulatorFn(final GroupByQuery query, final MetricManipulationFn fn)
|
||||
public Function<Row, Row> makePreComputeManipulatorFn(final GroupByQuery query, final MetricManipulationFn fn)
|
||||
{
|
||||
return new Function<Row, Row>()
|
||||
{
|
||||
|
|
|
|||
|
|
@ -155,7 +155,7 @@ public class SegmentMetadataQueryQueryToolChest extends QueryToolChest<SegmentAn
|
|||
}
|
||||
|
||||
@Override
|
||||
public Function<SegmentAnalysis, SegmentAnalysis> makeMetricManipulatorFn(
|
||||
public Function<SegmentAnalysis, SegmentAnalysis> makePreComputeManipulatorFn(
|
||||
SegmentMetadataQuery query, MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
|
|
|
|||
|
|
@ -104,47 +104,47 @@ public class SegmentMetadataQueryRunnerFactory implements QueryRunnerFactory<Seg
|
|||
)
|
||||
{
|
||||
return new ConcatQueryRunner<SegmentAnalysis>(
|
||||
Sequences.map(
|
||||
Sequences.simple(queryRunners),
|
||||
new Function<QueryRunner<SegmentAnalysis>, QueryRunner<SegmentAnalysis>>()
|
||||
Sequences.map(
|
||||
Sequences.simple(queryRunners),
|
||||
new Function<QueryRunner<SegmentAnalysis>, QueryRunner<SegmentAnalysis>>()
|
||||
{
|
||||
@Override
|
||||
public QueryRunner<SegmentAnalysis> apply(final QueryRunner<SegmentAnalysis> input)
|
||||
{
|
||||
return new QueryRunner<SegmentAnalysis>()
|
||||
{
|
||||
@Override
|
||||
public QueryRunner<SegmentAnalysis> apply(final QueryRunner<SegmentAnalysis> input)
|
||||
public Sequence<SegmentAnalysis> run(final Query<SegmentAnalysis> query)
|
||||
{
|
||||
return new QueryRunner<SegmentAnalysis>()
|
||||
{
|
||||
@Override
|
||||
public Sequence<SegmentAnalysis> run(final Query<SegmentAnalysis> query)
|
||||
{
|
||||
|
||||
Future<Sequence<SegmentAnalysis>> future = queryExecutor.submit(
|
||||
new Callable<Sequence<SegmentAnalysis>>()
|
||||
{
|
||||
@Override
|
||||
public Sequence<SegmentAnalysis> call() throws Exception
|
||||
{
|
||||
return new ExecutorExecutingSequence<SegmentAnalysis>(
|
||||
input.run(query),
|
||||
queryExecutor
|
||||
);
|
||||
}
|
||||
}
|
||||
);
|
||||
try {
|
||||
return future.get();
|
||||
Future<Sequence<SegmentAnalysis>> future = queryExecutor.submit(
|
||||
new Callable<Sequence<SegmentAnalysis>>()
|
||||
{
|
||||
@Override
|
||||
public Sequence<SegmentAnalysis> call() throws Exception
|
||||
{
|
||||
return new ExecutorExecutingSequence<SegmentAnalysis>(
|
||||
input.run(query),
|
||||
queryExecutor
|
||||
);
|
||||
}
|
||||
}
|
||||
catch (InterruptedException e) {
|
||||
throw Throwables.propagate(e);
|
||||
}
|
||||
catch (ExecutionException e) {
|
||||
throw Throwables.propagate(e);
|
||||
}
|
||||
}
|
||||
};
|
||||
);
|
||||
try {
|
||||
return future.get();
|
||||
}
|
||||
catch (InterruptedException e) {
|
||||
throw Throwables.propagate(e);
|
||||
}
|
||||
catch (ExecutionException e) {
|
||||
throw Throwables.propagate(e);
|
||||
}
|
||||
}
|
||||
}
|
||||
)
|
||||
);
|
||||
};
|
||||
}
|
||||
}
|
||||
)
|
||||
);
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
|
|||
|
|
@ -32,7 +32,6 @@ import java.util.Map;
|
|||
|
||||
public class SegmentMetadataQuery extends BaseQuery<SegmentAnalysis>
|
||||
{
|
||||
|
||||
private final ColumnIncluderator toInclude;
|
||||
private final boolean merge;
|
||||
|
||||
|
|
|
|||
|
|
@ -129,7 +129,7 @@ public class SearchQueryQueryToolChest extends QueryToolChest<Result<SearchResul
|
|||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<SearchResultValue>, Result<SearchResultValue>> makeMetricManipulatorFn(
|
||||
public Function<Result<SearchResultValue>, Result<SearchResultValue>> makePreComputeManipulatorFn(
|
||||
SearchQuery query, MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
|
|
@ -294,7 +294,7 @@ public class SearchQueryQueryToolChest extends QueryToolChest<Result<SearchResul
|
|||
return runner.run(query);
|
||||
}
|
||||
|
||||
final boolean isBySegment = Boolean.parseBoolean((String) query.getContextValue("bySegment", "false"));
|
||||
final boolean isBySegment = query.getContextBySegment(false);
|
||||
|
||||
return Sequences.map(
|
||||
runner.run(query.withLimit(config.getMaxSearchLimit())),
|
||||
|
|
|
|||
|
|
@ -55,7 +55,7 @@ import java.util.Map;
|
|||
import java.util.TreeSet;
|
||||
|
||||
/**
|
||||
*/
|
||||
*/
|
||||
public class SearchQueryRunner implements QueryRunner<Result<SearchResultValue>>
|
||||
{
|
||||
private static final EmittingLogger log = new EmittingLogger(SearchQueryRunner.class);
|
||||
|
|
@ -99,12 +99,10 @@ public class SearchQueryRunner implements QueryRunner<Result<SearchResultValue>>
|
|||
ConciseSet set = new ConciseSet();
|
||||
set.add(0);
|
||||
baseFilter = ImmutableConciseSet.newImmutableFromMutable(set);
|
||||
}
|
||||
else {
|
||||
} else {
|
||||
baseFilter = ImmutableConciseSet.complement(new ImmutableConciseSet(), index.getNumRows());
|
||||
}
|
||||
}
|
||||
else {
|
||||
} else {
|
||||
baseFilter = filter.goConcise(new ColumnSelectorBitmapIndexSelector(index));
|
||||
}
|
||||
|
||||
|
|
@ -133,49 +131,52 @@ public class SearchQueryRunner implements QueryRunner<Result<SearchResultValue>>
|
|||
}
|
||||
|
||||
final StorageAdapter adapter = segment.asStorageAdapter();
|
||||
if (adapter != null) {
|
||||
Iterable<String> dimsToSearch;
|
||||
if (dimensions == null || dimensions.isEmpty()) {
|
||||
dimsToSearch = adapter.getAvailableDimensions();
|
||||
} else {
|
||||
dimsToSearch = dimensions;
|
||||
|
||||
if (adapter == null) {
|
||||
log.makeAlert("WTF!? Unable to process search query on segment.")
|
||||
.addData("segment", segment.getIdentifier())
|
||||
.addData("query", query).emit();
|
||||
throw new ISE(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
|
||||
);
|
||||
}
|
||||
|
||||
Iterable<String> dimsToSearch;
|
||||
if (dimensions == null || dimensions.isEmpty()) {
|
||||
dimsToSearch = adapter.getAvailableDimensions();
|
||||
} else {
|
||||
dimsToSearch = dimensions;
|
||||
}
|
||||
|
||||
final TreeSet<SearchHit> retVal = Sets.newTreeSet(query.getSort().getComparator());
|
||||
|
||||
final Iterable<Cursor> cursors = adapter.makeCursors(filter, segment.getDataInterval(), QueryGranularity.ALL);
|
||||
for (Cursor cursor : cursors) {
|
||||
Map<String, DimensionSelector> dimSelectors = Maps.newHashMap();
|
||||
for (String dim : dimsToSearch) {
|
||||
dimSelectors.put(dim, cursor.makeDimensionSelector(dim));
|
||||
}
|
||||
|
||||
final TreeSet<SearchHit> retVal = Sets.newTreeSet(query.getSort().getComparator());
|
||||
|
||||
final Iterable<Cursor> cursors = adapter.makeCursors(filter, segment.getDataInterval(), QueryGranularity.ALL);
|
||||
for (Cursor cursor : cursors) {
|
||||
Map<String, DimensionSelector> dimSelectors = Maps.newHashMap();
|
||||
for (String dim : dimsToSearch) {
|
||||
dimSelectors.put(dim, cursor.makeDimensionSelector(dim));
|
||||
}
|
||||
|
||||
while (!cursor.isDone()) {
|
||||
for (Map.Entry<String, DimensionSelector> entry : dimSelectors.entrySet()) {
|
||||
final DimensionSelector selector = entry.getValue();
|
||||
final IndexedInts vals = selector.getRow();
|
||||
for (int i = 0; i < vals.size(); ++i) {
|
||||
final String dimVal = selector.lookupName(vals.get(i));
|
||||
if (searchQuerySpec.accept(dimVal)) {
|
||||
retVal.add(new SearchHit(entry.getKey(), dimVal));
|
||||
if (retVal.size() >= limit) {
|
||||
return makeReturnResult(limit, retVal);
|
||||
}
|
||||
while (!cursor.isDone()) {
|
||||
for (Map.Entry<String, DimensionSelector> entry : dimSelectors.entrySet()) {
|
||||
final DimensionSelector selector = entry.getValue();
|
||||
final IndexedInts vals = selector.getRow();
|
||||
for (int i = 0; i < vals.size(); ++i) {
|
||||
final String dimVal = selector.lookupName(vals.get(i));
|
||||
if (searchQuerySpec.accept(dimVal)) {
|
||||
retVal.add(new SearchHit(entry.getKey(), dimVal));
|
||||
if (retVal.size() >= limit) {
|
||||
return makeReturnResult(limit, retVal);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
cursor.advance();
|
||||
}
|
||||
}
|
||||
|
||||
return makeReturnResult(limit, retVal);
|
||||
cursor.advance();
|
||||
}
|
||||
}
|
||||
|
||||
log.makeAlert("WTF!? Unable to process search query on segment.")
|
||||
.addData("segment", segment.getIdentifier())
|
||||
.addData("query", query);
|
||||
return Sequences.empty();
|
||||
return makeReturnResult(limit, retVal);
|
||||
}
|
||||
|
||||
private Sequence<Result<SearchResultValue>> makeReturnResult(int limit, TreeSet<SearchHit> retVal)
|
||||
|
|
|
|||
|
|
@ -22,6 +22,7 @@ package io.druid.query.select;
|
|||
import com.fasterxml.jackson.annotation.JsonCreator;
|
||||
import com.fasterxml.jackson.annotation.JsonProperty;
|
||||
import com.google.common.collect.Maps;
|
||||
import com.metamx.common.ISE;
|
||||
import org.joda.time.DateTime;
|
||||
|
||||
import java.util.Map;
|
||||
|
|
@ -50,7 +51,14 @@ public class EventHolder
|
|||
|
||||
public DateTime getTimestamp()
|
||||
{
|
||||
return (DateTime) event.get(timestampKey);
|
||||
Object retVal = event.get(timestampKey);
|
||||
if (retVal instanceof String) {
|
||||
return new DateTime(retVal);
|
||||
} else if (retVal instanceof DateTime) {
|
||||
return (DateTime) retVal;
|
||||
} else {
|
||||
throw new ISE("Do not understand format [%s]", retVal.getClass());
|
||||
}
|
||||
}
|
||||
|
||||
@JsonProperty
|
||||
|
|
|
|||
|
|
@ -22,6 +22,7 @@ package io.druid.query.select;
|
|||
import com.google.common.base.Function;
|
||||
import com.google.common.collect.Lists;
|
||||
import com.google.common.collect.Maps;
|
||||
import com.metamx.common.ISE;
|
||||
import com.metamx.common.guava.BaseSequence;
|
||||
import com.metamx.common.guava.Sequence;
|
||||
import io.druid.query.QueryRunnerHelper;
|
||||
|
|
@ -54,6 +55,12 @@ public class SelectQueryEngine
|
|||
{
|
||||
final StorageAdapter adapter = segment.asStorageAdapter();
|
||||
|
||||
if (adapter == null) {
|
||||
throw new ISE(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
|
||||
);
|
||||
}
|
||||
|
||||
final Iterable<String> dims;
|
||||
if (query.getDimensions() == null || query.getDimensions().isEmpty()) {
|
||||
dims = adapter.getAvailableDimensions();
|
||||
|
|
|
|||
|
|
@ -131,7 +131,7 @@ public class SelectQueryQueryToolChest extends QueryToolChest<Result<SelectResul
|
|||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<SelectResultValue>, Result<SelectResultValue>> makeMetricManipulatorFn(
|
||||
public Function<Result<SelectResultValue>, Result<SelectResultValue>> makePreComputeManipulatorFn(
|
||||
final SelectQuery query, final MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
|
|
@ -170,10 +170,9 @@ public class SelectQueryQueryToolChest extends QueryToolChest<Result<SelectResul
|
|||
++index;
|
||||
}
|
||||
|
||||
|
||||
final Set<String> metrics = Sets.newTreeSet();
|
||||
if (query.getMetrics() != null) {
|
||||
dimensions.addAll(query.getMetrics());
|
||||
metrics.addAll(query.getMetrics());
|
||||
}
|
||||
|
||||
final byte[][] metricBytes = new byte[metrics.size()][];
|
||||
|
|
|
|||
|
|
@ -123,7 +123,7 @@ public class TimeBoundaryQueryQueryToolChest
|
|||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<TimeBoundaryResultValue>, Result<TimeBoundaryResultValue>> makeMetricManipulatorFn(
|
||||
public Function<Result<TimeBoundaryResultValue>, Result<TimeBoundaryResultValue>> makePreComputeManipulatorFn(
|
||||
TimeBoundaryQuery query, MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
|
|
|
|||
|
|
@ -87,6 +87,12 @@ public class TimeBoundaryQueryRunnerFactory
|
|||
@Override
|
||||
public Iterator<Result<TimeBoundaryResultValue>> make()
|
||||
{
|
||||
if (adapter == null) {
|
||||
throw new ISE(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
|
||||
);
|
||||
}
|
||||
|
||||
return legacyQuery.buildResult(
|
||||
adapter.getInterval().getStart(),
|
||||
adapter.getMinTime(),
|
||||
|
|
|
|||
|
|
@ -24,7 +24,6 @@ import io.druid.granularity.AllGranularity;
|
|||
import io.druid.granularity.QueryGranularity;
|
||||
import io.druid.query.Result;
|
||||
import io.druid.query.aggregation.AggregatorFactory;
|
||||
import io.druid.query.aggregation.PostAggregator;
|
||||
|
||||
import java.util.LinkedHashMap;
|
||||
import java.util.List;
|
||||
|
|
@ -37,17 +36,14 @@ public class TimeseriesBinaryFn
|
|||
{
|
||||
private final QueryGranularity gran;
|
||||
private final List<AggregatorFactory> aggregations;
|
||||
private final List<PostAggregator> postAggregations;
|
||||
|
||||
public TimeseriesBinaryFn(
|
||||
QueryGranularity granularity,
|
||||
List<AggregatorFactory> aggregations,
|
||||
List<PostAggregator> postAggregations
|
||||
List<AggregatorFactory> aggregations
|
||||
)
|
||||
{
|
||||
this.gran = granularity;
|
||||
this.aggregations = aggregations;
|
||||
this.postAggregations = postAggregations;
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
@ -71,11 +67,6 @@ public class TimeseriesBinaryFn
|
|||
retVal.put(metricName, factory.combine(arg1Val.getMetric(metricName), arg2Val.getMetric(metricName)));
|
||||
}
|
||||
|
||||
for (PostAggregator pf : postAggregations) {
|
||||
final String metricName = pf.getName();
|
||||
retVal.put(metricName, pf.compute(retVal));
|
||||
}
|
||||
|
||||
return (gran instanceof AllGranularity) ?
|
||||
new Result<TimeseriesResultValue>(
|
||||
arg1.getTimestamp(),
|
||||
|
|
|
|||
|
|
@ -20,6 +20,7 @@
|
|||
package io.druid.query.timeseries;
|
||||
|
||||
import com.google.common.base.Function;
|
||||
import com.metamx.common.ISE;
|
||||
import com.metamx.common.guava.BaseSequence;
|
||||
import com.metamx.common.guava.Sequence;
|
||||
import io.druid.query.QueryRunnerHelper;
|
||||
|
|
@ -40,6 +41,12 @@ public class TimeseriesQueryEngine
|
|||
{
|
||||
public Sequence<Result<TimeseriesResultValue>> process(final TimeseriesQuery query, final StorageAdapter adapter)
|
||||
{
|
||||
if (adapter == null) {
|
||||
throw new ISE(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
|
||||
);
|
||||
}
|
||||
|
||||
return new BaseSequence<Result<TimeseriesResultValue>, Iterator<Result<TimeseriesResultValue>>>(
|
||||
new BaseSequence.IteratorMaker<Result<TimeseriesResultValue>, Iterator<Result<TimeseriesResultValue>>>()
|
||||
{
|
||||
|
|
@ -74,10 +81,6 @@ public class TimeseriesQueryEngine
|
|||
bob.addMetric(aggregator);
|
||||
}
|
||||
|
||||
for (PostAggregator postAgg : postAggregatorSpecs) {
|
||||
bob.addMetric(postAgg);
|
||||
}
|
||||
|
||||
Result<TimeseriesResultValue> retVal = bob.build();
|
||||
|
||||
// cleanup
|
||||
|
|
|
|||
|
|
@ -101,8 +101,7 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest<Result<Timeser
|
|||
TimeseriesQuery query = (TimeseriesQuery) input;
|
||||
return new TimeseriesBinaryFn(
|
||||
query.getGranularity(),
|
||||
query.getAggregatorSpecs(),
|
||||
query.getPostAggregatorSpecs()
|
||||
query.getAggregatorSpecs()
|
||||
);
|
||||
}
|
||||
};
|
||||
|
|
@ -131,32 +130,6 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest<Result<Timeser
|
|||
.setUser9(Minutes.minutes(numMinutes).toString());
|
||||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<TimeseriesResultValue>, Result<TimeseriesResultValue>> makeMetricManipulatorFn(
|
||||
final TimeseriesQuery query, final MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
return new Function<Result<TimeseriesResultValue>, Result<TimeseriesResultValue>>()
|
||||
{
|
||||
@Override
|
||||
public Result<TimeseriesResultValue> apply(Result<TimeseriesResultValue> result)
|
||||
{
|
||||
final Map<String, Object> values = Maps.newHashMap();
|
||||
final TimeseriesResultValue holder = result.getValue();
|
||||
for (AggregatorFactory agg : query.getAggregatorSpecs()) {
|
||||
values.put(agg.getName(), fn.manipulate(agg, holder.getMetric(agg.getName())));
|
||||
}
|
||||
for (PostAggregator postAgg : query.getPostAggregatorSpecs()) {
|
||||
values.put(postAgg.getName(), holder.getMetric(postAgg.getName()));
|
||||
}
|
||||
return new Result<TimeseriesResultValue>(
|
||||
result.getTimestamp(),
|
||||
new TimeseriesResultValue(values)
|
||||
);
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
@Override
|
||||
public TypeReference<Result<TimeseriesResultValue>> getResultTypeReference()
|
||||
{
|
||||
|
|
@ -169,7 +142,6 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest<Result<Timeser
|
|||
return new CacheStrategy<Result<TimeseriesResultValue>, Object, TimeseriesQuery>()
|
||||
{
|
||||
private final List<AggregatorFactory> aggs = query.getAggregatorSpecs();
|
||||
private final List<PostAggregator> postAggs = query.getPostAggregatorSpecs();
|
||||
|
||||
@Override
|
||||
public byte[] computeCacheKey(TimeseriesQuery query)
|
||||
|
|
@ -238,10 +210,6 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest<Result<Timeser
|
|||
retVal.put(factory.getName(), factory.deserialize(resultIter.next()));
|
||||
}
|
||||
|
||||
for (PostAggregator postAgg : postAggs) {
|
||||
retVal.put(postAgg.getName(), postAgg.compute(retVal));
|
||||
}
|
||||
|
||||
return new Result<TimeseriesResultValue>(
|
||||
timestamp,
|
||||
new TimeseriesResultValue(retVal)
|
||||
|
|
@ -268,4 +236,52 @@ public class TimeseriesQueryQueryToolChest extends QueryToolChest<Result<Timeser
|
|||
{
|
||||
return Ordering.natural();
|
||||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<TimeseriesResultValue>, Result<TimeseriesResultValue>> makePreComputeManipulatorFn(
|
||||
final TimeseriesQuery query, final MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
return makeComputeManipulatorFn(query, fn, false);
|
||||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<TimeseriesResultValue>, Result<TimeseriesResultValue>> makePostComputeManipulatorFn(
|
||||
TimeseriesQuery query, MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
return makeComputeManipulatorFn(query, fn, true);
|
||||
}
|
||||
|
||||
private Function<Result<TimeseriesResultValue>, Result<TimeseriesResultValue>> makeComputeManipulatorFn(
|
||||
final TimeseriesQuery query, final MetricManipulationFn fn, final boolean calculatePostAggs
|
||||
)
|
||||
{
|
||||
return new Function<Result<TimeseriesResultValue>, Result<TimeseriesResultValue>>()
|
||||
{
|
||||
@Override
|
||||
public Result<TimeseriesResultValue> apply(Result<TimeseriesResultValue> result)
|
||||
{
|
||||
final Map<String, Object> values = Maps.newHashMap();
|
||||
final TimeseriesResultValue holder = result.getValue();
|
||||
if (calculatePostAggs) {
|
||||
// put non finalized aggregators for calculating dependent post Aggregators
|
||||
for (AggregatorFactory agg : query.getAggregatorSpecs()) {
|
||||
values.put(agg.getName(), holder.getMetric(agg.getName()));
|
||||
}
|
||||
for (PostAggregator postAgg : query.getPostAggregatorSpecs()) {
|
||||
values.put(postAgg.getName(), postAgg.compute(values));
|
||||
}
|
||||
}
|
||||
for (AggregatorFactory agg : query.getAggregatorSpecs()) {
|
||||
values.put(agg.getName(), fn.manipulate(agg, holder.getMetric(agg.getName())));
|
||||
}
|
||||
|
||||
return new Result<TimeseriesResultValue>(
|
||||
result.getTimestamp(),
|
||||
new TimeseriesResultValue(values)
|
||||
);
|
||||
}
|
||||
};
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -19,10 +19,11 @@
|
|||
|
||||
package io.druid.query.topn;
|
||||
|
||||
import com.google.common.collect.Lists;
|
||||
import com.metamx.common.ISE;
|
||||
import com.metamx.common.Pair;
|
||||
import io.druid.collections.StupidPool;
|
||||
import io.druid.query.aggregation.AggregatorFactory;
|
||||
import io.druid.query.aggregation.AggregatorUtil;
|
||||
import io.druid.query.aggregation.PostAggregator;
|
||||
import io.druid.segment.Capabilities;
|
||||
import io.druid.segment.Cursor;
|
||||
|
|
@ -56,7 +57,6 @@ public class AggregateTopNMetricFirstAlgorithm implements TopNAlgorithm<int[], T
|
|||
this.bufferPool = bufferPool;
|
||||
}
|
||||
|
||||
|
||||
@Override
|
||||
public TopNParams makeInitParams(
|
||||
DimensionSelector dimSelector, Cursor cursor
|
||||
|
|
@ -65,65 +65,27 @@ public class AggregateTopNMetricFirstAlgorithm implements TopNAlgorithm<int[], T
|
|||
return new TopNParams(dimSelector, cursor, dimSelector.getValueCardinality(), Integer.MAX_VALUE);
|
||||
}
|
||||
|
||||
@Override
|
||||
public TopNResultBuilder makeResultBuilder(TopNParams params)
|
||||
{
|
||||
return query.getTopNMetricSpec().getResultBuilder(
|
||||
params.getCursor().getTime(), query.getDimensionSpec(), query.getThreshold(), comparator
|
||||
);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void run(
|
||||
TopNParams params, TopNResultBuilder resultBuilder, int[] ints
|
||||
)
|
||||
{
|
||||
final TopNResultBuilder singleMetricResultBuilder = makeResultBuilder(params);
|
||||
final String metric;
|
||||
// ugly
|
||||
TopNMetricSpec spec = query.getTopNMetricSpec();
|
||||
if (spec instanceof InvertedTopNMetricSpec
|
||||
&& ((InvertedTopNMetricSpec) spec).getDelegate() instanceof NumericTopNMetricSpec) {
|
||||
metric = ((NumericTopNMetricSpec) ((InvertedTopNMetricSpec) spec).getDelegate()).getMetric();
|
||||
} else if (spec instanceof NumericTopNMetricSpec) {
|
||||
metric = ((NumericTopNMetricSpec) query.getTopNMetricSpec()).getMetric();
|
||||
} else {
|
||||
throw new ISE("WTF?! We are in AggregateTopNMetricFirstAlgorithm with a [%s] spec", spec.getClass().getName());
|
||||
}
|
||||
final String metric = query.getTopNMetricSpec().getMetricName(query.getDimensionSpec());
|
||||
Pair<List<AggregatorFactory>, List<PostAggregator>> condensedAggPostAggPair = AggregatorUtil.condensedAggregators(
|
||||
query.getAggregatorSpecs(),
|
||||
query.getPostAggregatorSpecs(),
|
||||
metric
|
||||
);
|
||||
|
||||
// Find either the aggregator or post aggregator to do the topN over
|
||||
List<AggregatorFactory> condensedAggs = Lists.newArrayList();
|
||||
for (AggregatorFactory aggregatorSpec : query.getAggregatorSpecs()) {
|
||||
if (aggregatorSpec.getName().equalsIgnoreCase(metric)) {
|
||||
condensedAggs.add(aggregatorSpec);
|
||||
break;
|
||||
}
|
||||
}
|
||||
List<PostAggregator> condensedPostAggs = Lists.newArrayList();
|
||||
if (condensedAggs.isEmpty()) {
|
||||
for (PostAggregator postAggregator : query.getPostAggregatorSpecs()) {
|
||||
if (postAggregator.getName().equalsIgnoreCase(metric)) {
|
||||
condensedPostAggs.add(postAggregator);
|
||||
|
||||
// Add all dependent metrics
|
||||
for (AggregatorFactory aggregatorSpec : query.getAggregatorSpecs()) {
|
||||
if (postAggregator.getDependentFields().contains(aggregatorSpec.getName())) {
|
||||
condensedAggs.add(aggregatorSpec);
|
||||
}
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (condensedAggs.isEmpty() && condensedPostAggs.isEmpty()) {
|
||||
if (condensedAggPostAggPair.lhs.isEmpty() && condensedAggPostAggPair.rhs.isEmpty()) {
|
||||
throw new ISE("WTF! Can't find the metric to do topN over?");
|
||||
}
|
||||
|
||||
// Run topN for only a single metric
|
||||
TopNQuery singleMetricQuery = new TopNQueryBuilder().copy(query)
|
||||
.aggregators(condensedAggs)
|
||||
.postAggregators(condensedPostAggs)
|
||||
.aggregators(condensedAggPostAggPair.lhs)
|
||||
.postAggregators(condensedAggPostAggPair.rhs)
|
||||
.build();
|
||||
final TopNResultBuilder singleMetricResultBuilder = BaseTopNAlgorithm.makeResultBuilder(params, singleMetricQuery);
|
||||
|
||||
PooledTopNAlgorithm singleMetricAlgo = new PooledTopNAlgorithm(capabilities, singleMetricQuery, bufferPool);
|
||||
PooledTopNAlgorithm.PooledTopNParams singleMetricParam = null;
|
||||
|
|
|
|||
|
|
@ -28,6 +28,7 @@ import io.druid.segment.Cursor;
|
|||
import io.druid.segment.DimensionSelector;
|
||||
|
||||
import java.util.Arrays;
|
||||
import java.util.Comparator;
|
||||
import java.util.List;
|
||||
|
||||
/**
|
||||
|
|
@ -230,4 +231,18 @@ public abstract class BaseTopNAlgorithm<DimValSelector, DimValAggregateStore, Pa
|
|||
return Pair.of(startIndex, endIndex);
|
||||
}
|
||||
}
|
||||
|
||||
public static TopNResultBuilder makeResultBuilder(TopNParams params, TopNQuery query)
|
||||
{
|
||||
Comparator comparator = query.getTopNMetricSpec()
|
||||
.getComparator(query.getAggregatorSpecs(), query.getPostAggregatorSpecs());
|
||||
return query.getTopNMetricSpec().getResultBuilder(
|
||||
params.getCursor().getTime(),
|
||||
query.getDimensionSpec(),
|
||||
query.getThreshold(),
|
||||
comparator,
|
||||
query.getAggregatorSpecs(),
|
||||
query.getPostAggregatorSpecs()
|
||||
);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -56,14 +56,6 @@ public class DimExtractionTopNAlgorithm extends BaseTopNAlgorithm<Aggregator[][]
|
|||
return new TopNParams(dimSelector, cursor, dimSelector.getValueCardinality(), Integer.MAX_VALUE);
|
||||
}
|
||||
|
||||
@Override
|
||||
public TopNResultBuilder makeResultBuilder(TopNParams params)
|
||||
{
|
||||
return query.getTopNMetricSpec().getResultBuilder(
|
||||
params.getCursor().getTime(), query.getDimensionSpec(), query.getThreshold(), comparator
|
||||
);
|
||||
}
|
||||
|
||||
@Override
|
||||
protected Aggregator[][] makeDimValSelector(TopNParams params, int numProcessed, int numToProcess)
|
||||
{
|
||||
|
|
@ -144,9 +136,7 @@ public class DimExtractionTopNAlgorithm extends BaseTopNAlgorithm<Aggregator[][]
|
|||
resultBuilder.addEntry(
|
||||
entry.getKey(),
|
||||
entry.getKey(),
|
||||
vals,
|
||||
query.getAggregatorSpecs(),
|
||||
query.getPostAggregatorSpecs()
|
||||
vals
|
||||
);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -36,7 +36,6 @@ import java.util.List;
|
|||
public class InvertedTopNMetricSpec implements TopNMetricSpec
|
||||
{
|
||||
private static final byte CACHE_TYPE_ID = 0x3;
|
||||
|
||||
private final TopNMetricSpec delegate;
|
||||
|
||||
@JsonCreator
|
||||
|
|
@ -76,10 +75,12 @@ public class InvertedTopNMetricSpec implements TopNMetricSpec
|
|||
DateTime timestamp,
|
||||
DimensionSpec dimSpec,
|
||||
int threshold,
|
||||
Comparator comparator
|
||||
Comparator comparator,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
)
|
||||
{
|
||||
return delegate.getResultBuilder(timestamp, dimSpec, threshold, comparator);
|
||||
return delegate.getResultBuilder(timestamp, dimSpec, threshold, comparator, aggFactories, postAggs);
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
@ -102,15 +103,27 @@ public class InvertedTopNMetricSpec implements TopNMetricSpec
|
|||
delegate.initTopNAlgorithmSelector(selector);
|
||||
}
|
||||
|
||||
@Override
|
||||
public String getMetricName(DimensionSpec dimSpec)
|
||||
{
|
||||
return delegate.getMetricName(dimSpec);
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean equals(Object o)
|
||||
{
|
||||
if (this == o) return true;
|
||||
if (o == null || getClass() != o.getClass()) return false;
|
||||
if (this == o) {
|
||||
return true;
|
||||
}
|
||||
if (o == null || getClass() != o.getClass()) {
|
||||
return false;
|
||||
}
|
||||
|
||||
InvertedTopNMetricSpec that = (InvertedTopNMetricSpec) o;
|
||||
|
||||
if (delegate != null ? !delegate.equals(that.delegate) : that.delegate != null) return false;
|
||||
if (delegate != null ? !delegate.equals(that.delegate) : that.delegate != null) {
|
||||
return false;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -80,10 +80,12 @@ public class LexicographicTopNMetricSpec implements TopNMetricSpec
|
|||
DateTime timestamp,
|
||||
DimensionSpec dimSpec,
|
||||
int threshold,
|
||||
Comparator comparator
|
||||
Comparator comparator,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
)
|
||||
{
|
||||
return new TopNLexicographicResultBuilder(timestamp, dimSpec, threshold, previousStop, comparator);
|
||||
return new TopNLexicographicResultBuilder(timestamp, dimSpec, threshold, previousStop, comparator, aggFactories);
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
@ -111,6 +113,12 @@ public class LexicographicTopNMetricSpec implements TopNMetricSpec
|
|||
selector.setAggregateAllMetrics(true);
|
||||
}
|
||||
|
||||
@Override
|
||||
public String getMetricName(DimensionSpec dimSpec)
|
||||
{
|
||||
return dimSpec.getOutputName();
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString()
|
||||
{
|
||||
|
|
|
|||
|
|
@ -121,10 +121,12 @@ public class NumericTopNMetricSpec implements TopNMetricSpec
|
|||
DateTime timestamp,
|
||||
DimensionSpec dimSpec,
|
||||
int threshold,
|
||||
Comparator comparator
|
||||
Comparator comparator,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
)
|
||||
{
|
||||
return new TopNNumericResultBuilder(timestamp, dimSpec, metric, threshold, comparator);
|
||||
return new TopNNumericResultBuilder(timestamp, dimSpec, metric, threshold, comparator, aggFactories, postAggs);
|
||||
}
|
||||
|
||||
@Override
|
||||
|
|
@ -150,6 +152,12 @@ public class NumericTopNMetricSpec implements TopNMetricSpec
|
|||
selector.setAggregateTopNMetricFirst(true);
|
||||
}
|
||||
|
||||
@Override
|
||||
public String getMetricName(DimensionSpec dimSpec)
|
||||
{
|
||||
return metric;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString()
|
||||
{
|
||||
|
|
|
|||
|
|
@ -35,7 +35,8 @@ import java.util.Comparator;
|
|||
|
||||
/**
|
||||
*/
|
||||
public class PooledTopNAlgorithm extends BaseTopNAlgorithm<int[], BufferAggregator[], PooledTopNAlgorithm.PooledTopNParams>
|
||||
public class PooledTopNAlgorithm
|
||||
extends BaseTopNAlgorithm<int[], BufferAggregator[], PooledTopNAlgorithm.PooledTopNParams>
|
||||
{
|
||||
private final Capabilities capabilities;
|
||||
private final TopNQuery query;
|
||||
|
|
@ -113,13 +114,7 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm<int[], BufferAggregat
|
|||
.build();
|
||||
}
|
||||
|
||||
@Override
|
||||
public TopNResultBuilder makeResultBuilder(PooledTopNParams params)
|
||||
{
|
||||
return query.getTopNMetricSpec().getResultBuilder(
|
||||
params.getCursor().getTime(), query.getDimensionSpec(), query.getThreshold(), comparator
|
||||
);
|
||||
}
|
||||
|
||||
|
||||
@Override
|
||||
protected int[] makeDimValSelector(PooledTopNParams params, int numProcessed, int numToProcess)
|
||||
|
|
@ -217,9 +212,7 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm<int[], BufferAggregat
|
|||
resultBuilder.addEntry(
|
||||
dimSelector.lookupName(i),
|
||||
i,
|
||||
vals,
|
||||
query.getAggregatorSpecs(),
|
||||
query.getPostAggregatorSpecs()
|
||||
vals
|
||||
);
|
||||
}
|
||||
}
|
||||
|
|
@ -228,7 +221,7 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm<int[], BufferAggregat
|
|||
@Override
|
||||
protected void closeAggregators(BufferAggregator[] bufferAggregators)
|
||||
{
|
||||
for(BufferAggregator agg : bufferAggregators) {
|
||||
for (BufferAggregator agg : bufferAggregators) {
|
||||
agg.close();
|
||||
}
|
||||
}
|
||||
|
|
@ -246,11 +239,6 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm<int[], BufferAggregat
|
|||
|
||||
public static class PooledTopNParams extends TopNParams
|
||||
{
|
||||
public static Builder builder()
|
||||
{
|
||||
return new Builder();
|
||||
}
|
||||
|
||||
private final ResourceHolder<ByteBuffer> resultsBufHolder;
|
||||
private final ByteBuffer resultsBuf;
|
||||
private final int[] aggregatorSizes;
|
||||
|
|
@ -278,6 +266,11 @@ public class PooledTopNAlgorithm extends BaseTopNAlgorithm<int[], BufferAggregat
|
|||
this.arrayProvider = arrayProvider;
|
||||
}
|
||||
|
||||
public static Builder builder()
|
||||
{
|
||||
return new Builder();
|
||||
}
|
||||
|
||||
public ResourceHolder<ByteBuffer> getResultsBufHolder()
|
||||
{
|
||||
return resultsBufHolder;
|
||||
|
|
|
|||
|
|
@ -33,8 +33,6 @@ public interface TopNAlgorithm<DimValSelector, Parameters extends TopNParams>
|
|||
|
||||
public TopNParams makeInitParams(DimensionSelector dimSelector, Cursor cursor);
|
||||
|
||||
public TopNResultBuilder makeResultBuilder(Parameters params);
|
||||
|
||||
public void run(
|
||||
Parameters params,
|
||||
TopNResultBuilder resultBuilder,
|
||||
|
|
|
|||
|
|
@ -24,6 +24,7 @@ import io.druid.granularity.AllGranularity;
|
|||
import io.druid.granularity.QueryGranularity;
|
||||
import io.druid.query.Result;
|
||||
import io.druid.query.aggregation.AggregatorFactory;
|
||||
import io.druid.query.aggregation.AggregatorUtil;
|
||||
import io.druid.query.aggregation.PostAggregator;
|
||||
import io.druid.query.dimension.DimensionSpec;
|
||||
import org.joda.time.DateTime;
|
||||
|
|
@ -63,7 +64,11 @@ public class TopNBinaryFn implements BinaryFn<Result<TopNResultValue>, Result<To
|
|||
this.topNMetricSpec = topNMetricSpec;
|
||||
this.threshold = threshold;
|
||||
this.aggregations = aggregatorSpecs;
|
||||
this.postAggregations = postAggregatorSpecs;
|
||||
|
||||
this.postAggregations = AggregatorUtil.pruneDependentPostAgg(
|
||||
postAggregatorSpecs,
|
||||
topNMetricSpec.getMetricName(dimSpec)
|
||||
);
|
||||
|
||||
this.dimension = dimSpec.getOutputName();
|
||||
this.comparator = topNMetricSpec.getComparator(aggregatorSpecs, postAggregatorSpecs);
|
||||
|
|
@ -79,7 +84,7 @@ public class TopNBinaryFn implements BinaryFn<Result<TopNResultValue>, Result<To
|
|||
return merger.getResult(arg1, comparator);
|
||||
}
|
||||
|
||||
Map<String, DimensionAndMetricValueExtractor> retVals = new LinkedHashMap<String, DimensionAndMetricValueExtractor>();
|
||||
Map<String, DimensionAndMetricValueExtractor> retVals = new LinkedHashMap<>();
|
||||
|
||||
TopNResultValue arg1Vals = arg1.getValue();
|
||||
TopNResultValue arg2Vals = arg2.getValue();
|
||||
|
|
@ -92,7 +97,8 @@ public class TopNBinaryFn implements BinaryFn<Result<TopNResultValue>, Result<To
|
|||
DimensionAndMetricValueExtractor arg1Val = retVals.get(dimensionValue);
|
||||
|
||||
if (arg1Val != null) {
|
||||
Map<String, Object> retVal = new LinkedHashMap<String, Object>();
|
||||
// size of map = aggregator + topNDim + postAgg (If sorting is done on post agg field)
|
||||
Map<String, Object> retVal = new LinkedHashMap<>(aggregations.size() + 2);
|
||||
|
||||
retVal.put(dimension, dimensionValue);
|
||||
for (AggregatorFactory factory : aggregations) {
|
||||
|
|
@ -117,7 +123,14 @@ public class TopNBinaryFn implements BinaryFn<Result<TopNResultValue>, Result<To
|
|||
timestamp = gran.toDateTime(gran.truncate(arg1.getTimestamp().getMillis()));
|
||||
}
|
||||
|
||||
TopNResultBuilder bob = topNMetricSpec.getResultBuilder(timestamp, dimSpec, threshold, comparator);
|
||||
TopNResultBuilder bob = topNMetricSpec.getResultBuilder(
|
||||
timestamp,
|
||||
dimSpec,
|
||||
threshold,
|
||||
comparator,
|
||||
aggregations,
|
||||
postAggregations
|
||||
);
|
||||
for (DimensionAndMetricValueExtractor extractor : retVals.values()) {
|
||||
bob.addEntry(extractor);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -40,7 +40,7 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
|
|||
private final DateTime timestamp;
|
||||
private final DimensionSpec dimSpec;
|
||||
private final String previousStop;
|
||||
|
||||
private final List<AggregatorFactory> aggFactories;
|
||||
private MinMaxPriorityQueue<DimValHolder> pQueue = null;
|
||||
|
||||
public TopNLexicographicResultBuilder(
|
||||
|
|
@ -48,12 +48,14 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
|
|||
DimensionSpec dimSpec,
|
||||
int threshold,
|
||||
String previousStop,
|
||||
final Comparator comparator
|
||||
final Comparator comparator,
|
||||
List<AggregatorFactory> aggFactories
|
||||
)
|
||||
{
|
||||
this.timestamp = timestamp;
|
||||
this.dimSpec = dimSpec;
|
||||
this.previousStop = previousStop;
|
||||
this.aggFactories = aggFactories;
|
||||
|
||||
instantiatePQueue(threshold, comparator);
|
||||
}
|
||||
|
|
@ -62,9 +64,7 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
|
|||
public TopNResultBuilder addEntry(
|
||||
String dimName,
|
||||
Object dimValIndex,
|
||||
Object[] metricVals,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
Object[] metricVals
|
||||
)
|
||||
{
|
||||
Map<String, Object> metricValues = Maps.newLinkedHashMap();
|
||||
|
|
@ -75,9 +75,6 @@ public class TopNLexicographicResultBuilder implements TopNResultBuilder
|
|||
for (Object metricVal : metricVals) {
|
||||
metricValues.put(aggsIter.next().getName(), metricVal);
|
||||
}
|
||||
for (PostAggregator postAgg : postAggs) {
|
||||
metricValues.put(postAgg.getName(), postAgg.compute(metricValues));
|
||||
}
|
||||
|
||||
pQueue.add(new DimValHolder.Builder().withDirName(dimName).withMetricValues(metricValues).build());
|
||||
}
|
||||
|
|
|
|||
|
|
@ -24,6 +24,8 @@ import io.druid.query.Result;
|
|||
import io.druid.segment.Cursor;
|
||||
import io.druid.segment.DimensionSelector;
|
||||
|
||||
import java.util.Comparator;
|
||||
|
||||
public class TopNMapFn implements Function<Cursor, Result<TopNResultValue>>
|
||||
{
|
||||
private final TopNQuery query;
|
||||
|
|
@ -52,7 +54,7 @@ public class TopNMapFn implements Function<Cursor, Result<TopNResultValue>>
|
|||
try {
|
||||
params = topNAlgorithm.makeInitParams(dimSelector, cursor);
|
||||
|
||||
TopNResultBuilder resultBuilder = topNAlgorithm.makeResultBuilder(params);
|
||||
TopNResultBuilder resultBuilder = BaseTopNAlgorithm.makeResultBuilder(params, query);
|
||||
|
||||
topNAlgorithm.run(params, resultBuilder, null);
|
||||
|
||||
|
|
|
|||
|
|
@ -47,7 +47,9 @@ public interface TopNMetricSpec
|
|||
DateTime timestamp,
|
||||
DimensionSpec dimSpec,
|
||||
int threshold,
|
||||
Comparator comparator
|
||||
Comparator comparator,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
);
|
||||
|
||||
public byte[] getCacheKey();
|
||||
|
|
@ -55,4 +57,6 @@ public interface TopNMetricSpec
|
|||
public <T> TopNMetricSpecBuilder<T> configureOptimizer(TopNMetricSpecBuilder<T> builder);
|
||||
|
||||
public void initTopNAlgorithmSelector(TopNAlgorithmSelector selector);
|
||||
|
||||
public String getMetricName(DimensionSpec dimSpec);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@ import com.google.common.collect.Maps;
|
|||
import com.google.common.collect.MinMaxPriorityQueue;
|
||||
import io.druid.query.Result;
|
||||
import io.druid.query.aggregation.AggregatorFactory;
|
||||
import io.druid.query.aggregation.AggregatorUtil;
|
||||
import io.druid.query.aggregation.PostAggregator;
|
||||
import io.druid.query.dimension.DimensionSpec;
|
||||
import org.joda.time.DateTime;
|
||||
|
|
@ -40,7 +41,8 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
|
|||
private final DateTime timestamp;
|
||||
private final DimensionSpec dimSpec;
|
||||
private final String metricName;
|
||||
|
||||
private final List<AggregatorFactory> aggFactories;
|
||||
private final List<PostAggregator> postAggs;
|
||||
private MinMaxPriorityQueue<DimValHolder> pQueue = null;
|
||||
|
||||
public TopNNumericResultBuilder(
|
||||
|
|
@ -48,12 +50,16 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
|
|||
DimensionSpec dimSpec,
|
||||
String metricName,
|
||||
int threshold,
|
||||
final Comparator comparator
|
||||
final Comparator comparator,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
)
|
||||
{
|
||||
this.timestamp = timestamp;
|
||||
this.dimSpec = dimSpec;
|
||||
this.metricName = metricName;
|
||||
this.aggFactories = aggFactories;
|
||||
this.postAggs = AggregatorUtil.pruneDependentPostAgg(postAggs, this.metricName);
|
||||
|
||||
instantiatePQueue(threshold, comparator);
|
||||
}
|
||||
|
|
@ -62,9 +68,7 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
|
|||
public TopNResultBuilder addEntry(
|
||||
String dimName,
|
||||
Object dimValIndex,
|
||||
Object[] metricVals,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
Object[] metricVals
|
||||
)
|
||||
{
|
||||
Map<String, Object> metricValues = Maps.newLinkedHashMap();
|
||||
|
|
@ -75,6 +79,7 @@ public class TopNNumericResultBuilder implements TopNResultBuilder
|
|||
for (Object metricVal : metricVals) {
|
||||
metricValues.put(aggFactoryIter.next().getName(), metricVal);
|
||||
}
|
||||
|
||||
for (PostAggregator postAgg : postAggs) {
|
||||
metricValues.put(postAgg.getName(), postAgg.compute(metricValues));
|
||||
}
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ package io.druid.query.topn;
|
|||
|
||||
import com.google.common.base.Function;
|
||||
import com.google.common.base.Preconditions;
|
||||
import com.google.common.collect.Lists;
|
||||
import com.metamx.common.ISE;
|
||||
import com.metamx.common.guava.FunctionalIterable;
|
||||
import com.metamx.common.logger.Logger;
|
||||
import io.druid.collections.StupidPool;
|
||||
|
|
@ -53,6 +53,12 @@ public class TopNQueryEngine
|
|||
|
||||
public Iterable<Result<TopNResultValue>> query(final TopNQuery query, final StorageAdapter adapter)
|
||||
{
|
||||
if (adapter == null) {
|
||||
throw new ISE(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped."
|
||||
);
|
||||
}
|
||||
|
||||
final List<Interval> queryIntervals = query.getQuerySegmentSpec().getIntervals();
|
||||
final Filter filter = Filters.convertDimensionFilters(query.getDimensionsFilter());
|
||||
final QueryGranularity granularity = query.getGranularity();
|
||||
|
|
@ -62,10 +68,6 @@ public class TopNQueryEngine
|
|||
queryIntervals.size() == 1, "Can only handle a single interval, got[%s]", queryIntervals
|
||||
);
|
||||
|
||||
if (mapFn == null) {
|
||||
return Lists.newArrayList();
|
||||
}
|
||||
|
||||
return FunctionalIterable
|
||||
.create(adapter.makeCursors(filter, queryIntervals.get(0), granularity))
|
||||
.transform(
|
||||
|
|
@ -84,13 +86,6 @@ public class TopNQueryEngine
|
|||
|
||||
private Function<Cursor, Result<TopNResultValue>> getMapFn(TopNQuery query, final StorageAdapter adapter)
|
||||
{
|
||||
if (adapter == null) {
|
||||
log.warn(
|
||||
"Null storage adapter found. Probably trying to issue a query against a segment being memory unmapped. Returning empty results."
|
||||
);
|
||||
return null;
|
||||
}
|
||||
|
||||
final Capabilities capabilities = adapter.getCapabilities();
|
||||
final int cardinality = adapter.getDimensionCardinality(query.getDimensionSpec().getDimension());
|
||||
int numBytesPerRecord = 0;
|
||||
|
|
|
|||
|
|
@ -46,6 +46,7 @@ import io.druid.query.Result;
|
|||
import io.druid.query.ResultGranularTimestampComparator;
|
||||
import io.druid.query.ResultMergeQueryRunner;
|
||||
import io.druid.query.aggregation.AggregatorFactory;
|
||||
import io.druid.query.aggregation.AggregatorUtil;
|
||||
import io.druid.query.aggregation.MetricManipulationFn;
|
||||
import io.druid.query.aggregation.PostAggregator;
|
||||
import io.druid.query.filter.DimFilter;
|
||||
|
|
@ -64,11 +65,13 @@ import java.util.Map;
|
|||
public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultValue>, TopNQuery>
|
||||
{
|
||||
private static final byte TOPN_QUERY = 0x1;
|
||||
|
||||
private static final Joiner COMMA_JOIN = Joiner.on(",");
|
||||
private static final TypeReference<Result<TopNResultValue>> TYPE_REFERENCE = new TypeReference<Result<TopNResultValue>>(){};
|
||||
|
||||
private static final TypeReference<Object> OBJECT_TYPE_REFERENCE = new TypeReference<Object>(){};
|
||||
private static final TypeReference<Result<TopNResultValue>> TYPE_REFERENCE = new TypeReference<Result<TopNResultValue>>()
|
||||
{
|
||||
};
|
||||
private static final TypeReference<Object> OBJECT_TYPE_REFERENCE = new TypeReference<Object>()
|
||||
{
|
||||
};
|
||||
private final TopNQueryConfig config;
|
||||
|
||||
@Inject
|
||||
|
|
@ -137,7 +140,7 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<TopNResultValue>, Result<TopNResultValue>> makeMetricManipulatorFn(
|
||||
public Function<Result<TopNResultValue>, Result<TopNResultValue>> makePreComputeManipulatorFn(
|
||||
final TopNQuery query, final MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
|
|
@ -146,7 +149,7 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
private String dimension = query.getDimensionSpec().getOutputName();
|
||||
|
||||
@Override
|
||||
public Result<TopNResultValue> apply(@Nullable Result<TopNResultValue> result)
|
||||
public Result<TopNResultValue> apply(Result<TopNResultValue> result)
|
||||
{
|
||||
List<Map<String, Object>> serializedValues = Lists.newArrayList(
|
||||
Iterables.transform(
|
||||
|
|
@ -154,14 +157,19 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
new Function<DimensionAndMetricValueExtractor, Map<String, Object>>()
|
||||
{
|
||||
@Override
|
||||
public Map<String, Object> apply(@Nullable DimensionAndMetricValueExtractor input)
|
||||
public Map<String, Object> apply(DimensionAndMetricValueExtractor input)
|
||||
{
|
||||
final Map<String, Object> values = Maps.newHashMap();
|
||||
for (AggregatorFactory agg : query.getAggregatorSpecs()) {
|
||||
values.put(agg.getName(), fn.manipulate(agg, input.getMetric(agg.getName())));
|
||||
}
|
||||
for (PostAggregator postAgg : query.getPostAggregatorSpecs()) {
|
||||
values.put(postAgg.getName(), input.getMetric(postAgg.getName()));
|
||||
for (PostAggregator postAgg : prunePostAggregators(query)) {
|
||||
Object calculatedPostAgg = input.getMetric(postAgg.getName());
|
||||
if (calculatedPostAgg != null) {
|
||||
values.put(postAgg.getName(), calculatedPostAgg);
|
||||
} else {
|
||||
values.put(postAgg.getName(), postAgg.compute(values));
|
||||
}
|
||||
}
|
||||
values.put(dimension, input.getDimensionValue(dimension));
|
||||
|
||||
|
|
@ -179,6 +187,60 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
};
|
||||
}
|
||||
|
||||
@Override
|
||||
public Function<Result<TopNResultValue>, Result<TopNResultValue>> makePostComputeManipulatorFn(
|
||||
final TopNQuery query, final MetricManipulationFn fn
|
||||
)
|
||||
{
|
||||
return new Function<Result<TopNResultValue>, Result<TopNResultValue>>()
|
||||
{
|
||||
private String dimension = query.getDimensionSpec().getOutputName();
|
||||
|
||||
@Override
|
||||
public Result<TopNResultValue> apply(Result<TopNResultValue> result)
|
||||
{
|
||||
List<Map<String, Object>> serializedValues = Lists.newArrayList(
|
||||
Iterables.transform(
|
||||
result.getValue(),
|
||||
new Function<DimensionAndMetricValueExtractor, Map<String, Object>>()
|
||||
{
|
||||
@Override
|
||||
public Map<String, Object> apply(DimensionAndMetricValueExtractor input)
|
||||
{
|
||||
final Map<String, Object> values = Maps.newHashMap();
|
||||
// put non finalized aggregators for calculating dependent post Aggregators
|
||||
for (AggregatorFactory agg : query.getAggregatorSpecs()) {
|
||||
values.put(agg.getName(), input.getMetric(agg.getName()));
|
||||
}
|
||||
|
||||
for (PostAggregator postAgg : query.getPostAggregatorSpecs()) {
|
||||
Object calculatedPostAgg = input.getMetric(postAgg.getName());
|
||||
if (calculatedPostAgg != null) {
|
||||
values.put(postAgg.getName(), calculatedPostAgg);
|
||||
} else {
|
||||
values.put(postAgg.getName(), postAgg.compute(values));
|
||||
}
|
||||
}
|
||||
for (AggregatorFactory agg : query.getAggregatorSpecs()) {
|
||||
values.put(agg.getName(), fn.manipulate(agg, input.getMetric(agg.getName())));
|
||||
}
|
||||
|
||||
values.put(dimension, input.getDimensionValue(dimension));
|
||||
|
||||
return values;
|
||||
}
|
||||
}
|
||||
)
|
||||
);
|
||||
|
||||
return new Result<TopNResultValue>(
|
||||
result.getTimestamp(),
|
||||
new TopNResultValue(serializedValues)
|
||||
);
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
@Override
|
||||
public TypeReference<Result<TopNResultValue>> getResultTypeReference()
|
||||
{
|
||||
|
|
@ -191,7 +253,11 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
return new CacheStrategy<Result<TopNResultValue>, Object, TopNQuery>()
|
||||
{
|
||||
private final List<AggregatorFactory> aggs = query.getAggregatorSpecs();
|
||||
private final List<PostAggregator> postAggs = query.getPostAggregatorSpecs();
|
||||
private final List<PostAggregator> postAggs = AggregatorUtil.pruneDependentPostAgg(
|
||||
query.getPostAggregatorSpecs(),
|
||||
query.getTopNMetricSpec()
|
||||
.getMetricName(query.getDimensionSpec())
|
||||
);
|
||||
|
||||
@Override
|
||||
public byte[] computeCacheKey(TopNQuery query)
|
||||
|
|
@ -231,7 +297,7 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
return new Function<Result<TopNResultValue>, Object>()
|
||||
{
|
||||
@Override
|
||||
public Object apply(@Nullable final Result<TopNResultValue> input)
|
||||
public Object apply(final Result<TopNResultValue> input)
|
||||
{
|
||||
List<DimensionAndMetricValueExtractor> results = Lists.newArrayList(input.getValue());
|
||||
final List<Object> retVal = Lists.newArrayListWithCapacity(results.size() + 1);
|
||||
|
|
@ -259,7 +325,7 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
private final QueryGranularity granularity = query.getGranularity();
|
||||
|
||||
@Override
|
||||
public Result<TopNResultValue> apply(@Nullable Object input)
|
||||
public Result<TopNResultValue> apply(Object input)
|
||||
{
|
||||
List<Object> results = (List<Object>) input;
|
||||
List<Map<String, Object>> retVal = Lists.newArrayListWithCapacity(results.size());
|
||||
|
|
@ -313,6 +379,11 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
return new ThresholdAdjustingQueryRunner(runner, config.getMinTopNThreshold());
|
||||
}
|
||||
|
||||
public Ordering<Result<TopNResultValue>> getOrdering()
|
||||
{
|
||||
return Ordering.natural();
|
||||
}
|
||||
|
||||
private static class ThresholdAdjustingQueryRunner implements QueryRunner<Result<TopNResultValue>>
|
||||
{
|
||||
private final QueryRunner<Result<TopNResultValue>> runner;
|
||||
|
|
@ -339,7 +410,7 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
return runner.run(query);
|
||||
}
|
||||
|
||||
final boolean isBySegment = Boolean.parseBoolean((String) query.getContextValue("bySegment", "false"));
|
||||
final boolean isBySegment = query.getContextBySegment(false);
|
||||
|
||||
return Sequences.map(
|
||||
runner.run(query.withThreshold(minTopNThreshold)),
|
||||
|
|
@ -359,7 +430,7 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
new Function<Result<TopNResultValue>, Result<TopNResultValue>>()
|
||||
{
|
||||
@Override
|
||||
public Result<TopNResultValue> apply(@Nullable Result<TopNResultValue> input)
|
||||
public Result<TopNResultValue> apply(Result<TopNResultValue> input)
|
||||
{
|
||||
return new Result<TopNResultValue>(
|
||||
input.getTimestamp(),
|
||||
|
|
@ -398,8 +469,11 @@ public class TopNQueryQueryToolChest extends QueryToolChest<Result<TopNResultVal
|
|||
}
|
||||
}
|
||||
|
||||
public Ordering<Result<TopNResultValue>> getOrdering()
|
||||
private static List<PostAggregator> prunePostAggregators(TopNQuery query)
|
||||
{
|
||||
return Ordering.natural();
|
||||
return AggregatorUtil.pruneDependentPostAgg(
|
||||
query.getPostAggregatorSpecs(),
|
||||
query.getTopNMetricSpec().getMetricName(query.getDimensionSpec())
|
||||
);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -33,9 +33,7 @@ public interface TopNResultBuilder
|
|||
public TopNResultBuilder addEntry(
|
||||
String dimName,
|
||||
Object dimValIndex,
|
||||
Object[] metricVals,
|
||||
List<AggregatorFactory> aggFactories,
|
||||
List<PostAggregator> postAggs
|
||||
Object[] metricVals
|
||||
);
|
||||
|
||||
public TopNResultBuilder addEntry(
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@
|
|||
package io.druid.data.input;
|
||||
|
||||
import com.google.protobuf.AbstractMessage;
|
||||
import com.google.protobuf.UnknownFieldSet;
|
||||
|
||||
public final class ProtoTestEventWrapper {
|
||||
private ProtoTestEventWrapper() {}
|
||||
|
|
@ -85,7 +86,13 @@ public final class ProtoTestEventWrapper {
|
|||
public ProtoTestEvent getDefaultInstanceForType() {
|
||||
return defaultInstance;
|
||||
}
|
||||
|
||||
|
||||
@Override
|
||||
public UnknownFieldSet getUnknownFields()
|
||||
{
|
||||
return UnknownFieldSet.getDefaultInstance();
|
||||
}
|
||||
|
||||
public static final com.google.protobuf.Descriptors.Descriptor
|
||||
getDescriptor() {
|
||||
return ProtoTestEventWrapper.internal_static_prototest_ProtoTestEvent_descriptor;
|
||||
|
|
@ -1049,6 +1056,7 @@ public final class ProtoTestEventWrapper {
|
|||
new com.google.protobuf.Descriptors.FileDescriptor[] {
|
||||
}, assigner);
|
||||
}
|
||||
|
||||
|
||||
// @@protoc_insertion_point(outer_class_scope)
|
||||
}
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue