* Various documentation updates.
1) Split out "data management" from "ingestion". Break it into thematic pages.
2) Move "SQL-based ingestion" into the Ingestion category. Adjust content so
all conceptual content is in concepts.md and all syntax content is in reference.md.
Shorten the known issues page to the most interesting ones.
3) Add SQL-based ingestion to the ingestion method comparison page. Remove the
index task, since index_parallel is just as good when maxNumConcurrentSubTasks: 1.
4) Rename various mentions of "Druid console" to "web console".
5) Add additional information to ingestion/partitioning.md.
6) Remove a mention of Tranquility.
7) Remove a note about upgrading to Druid 0.10.1.
8) Remove no-longer-relevant task types from ingestion/tasks.md.
9) Move ingestion/native-batch-firehose.md to the hidden section. It was previously deprecated.
10) Move ingestion/native-batch-simple-task.md to the hidden section. It is still linked in some
places, but it isn't very useful compared to index_parallel, so it shouldn't take up space
in the sidebar.
11) Make all br tags self-closing.
12) Certain other cosmetic changes.
13) Update to node-sass 7.
* make travis use node12 for docs
Co-authored-by: Vadim Ogievetsky <vadim@ogievetsky.com>
9.7 KiB
| id | title |
|---|---|
| web-console | Web console |
Druid includes a web console for loading data, managing datasources and tasks, and viewing server status and segment information. You can also run SQL and native Druid queries in the console.
Enable the following cluster settings to use the web console. Note that these settings are enabled by default.
- Enable the Router's management proxy.
- Enable Druid SQL for the Broker processes in the cluster.
The Router service hosts the web console. Access the web console at the following address:
http://<ROUTER_IP>:<ROUTER_PORT>
Security note: Without Druid user permissions configured, any user of the API or web console has effectively the same level of access to local files and network services as the user under which Druid runs. It is a best practice to avoid running Druid as the root user, and to use Druid permissions or network firewalls to restrict which users have access to potentially sensitive resources.
This topic presents the high-level features and functionality of the web console.
Home
The Home view provides a high-level overview of the cluster. Each card is clickable and links to the appropriate view.
The Home view displays the following cards:
- Status. Click this card for information on the Druid version and any extensions loaded on the cluster.
- Datasources
- Segments
- Supervisors
- Tasks
- Services
- Lookups
You can access the data loader and lookups view from the top-level navigation of the Home view.

Query
SQL-based ingestion and the multi-stage query task engine use the Query view, which provides you with a UI to edit and use SQL queries. You should see this UI automatically in Druid 24.0 and later since the multi-stage query extension is loaded by default.
The following screenshot shows a populated enhanced Query view along with a description of its parts:

- The multi-stage, tab-enabled, Query view is where you can issue queries and see results.
All other views are unchanged from the non-enhanced version. You can still access the original Query view by navigating to
#queryin the URL. You can tell that you're looking at the updated Query view by the presence of the tabs (3). - The druid panel shows the available schemas, datasources, and columns.
- Query tabs allow you to manage and run several queries at once. Click the plus icon to open a new tab. To manipulate existing tabs, click the tab name.
- The tab bar contains some helpful tools including the Connect external data button that samples external data and creates an initial query with the appropriate
EXTERNdefinition that you can then edit as needed. - The Recent query tasks panel lets you see currently running and previous queries from all users in the cluster.
It is equivalent to the Task view in the Ingestion view with the filter of
type='query_controller'. - You can click on each query entry to attach to that query in a new tab.
- You can download an archive of all the pertinent details about the query that you can share.
- The Run button runs the query.
- The Preview button appears when you enter an INSERT/REPLACE query. It runs the query inline without the INSERT/REPLACE clause and with an added LIMIT to give you a preview of the data that would be ingested if you click Run. The added LIMIT makes the query run faster but provides incomplete results.
- The engine selector lets you choose which engine (API endpoint) to send a query to. By default, it automatically picks which endpoint to use based on an analysis of the query, but you can select a specific engine explicitly. You can also configure the engine specific context parameters from this menu.
- The Max tasks picker appears when you have the sql-msq-task engine selected. It lets you configure the degree of parallelism.
- The More menu (...) contains the following helpful tools:
- Explain SQL query shows you the logical plan returned by
EXPLAIN PLAN FORfor a SQL query. - Query history shows you previously executed queries.
- Convert ingestion spec to SQL lets you convert a native batch ingestion spec to an equivalent SQL query.
- Attach tab from task ID lets you create a new tab from the task ID of a query executed on this cluster.
- Open query detail archive lets you open a detail archive generated on any cluster by (7).
- The query timer indicates how long the query has been running for.
- The (cancel) link cancels the currently running query.
- The main progress bar shows the overall progress of the query. The progress is computed from the various counters in the live reports (16).
- The Current stage progress bar shows the progress for the currently running query stage. If several stages are executing concurrently, it conservatively shows the information for the earliest executing stage.
- The live query reports show detailed information of all the stages (past, present, and future). The live reports are shown while the query is running. You can hide the report if you want. After queries finish, you can access them by clicking on the query time indicator or from the Recent query tasks panel (6).
- You can expand each stage of the live query report by clicking on the triangle to show per worker and per partition statistics.
Data loader
You can use the data loader to build an ingestion spec with a step-by-step wizard.
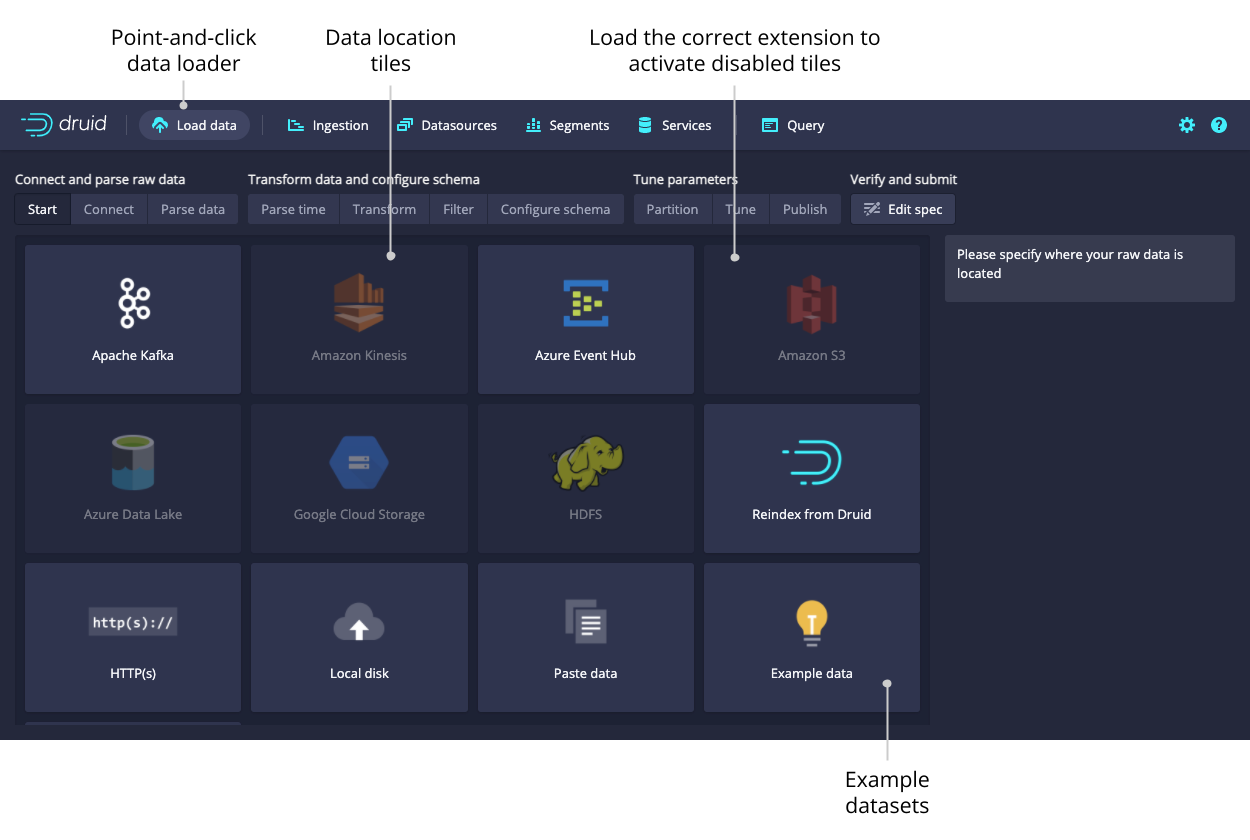
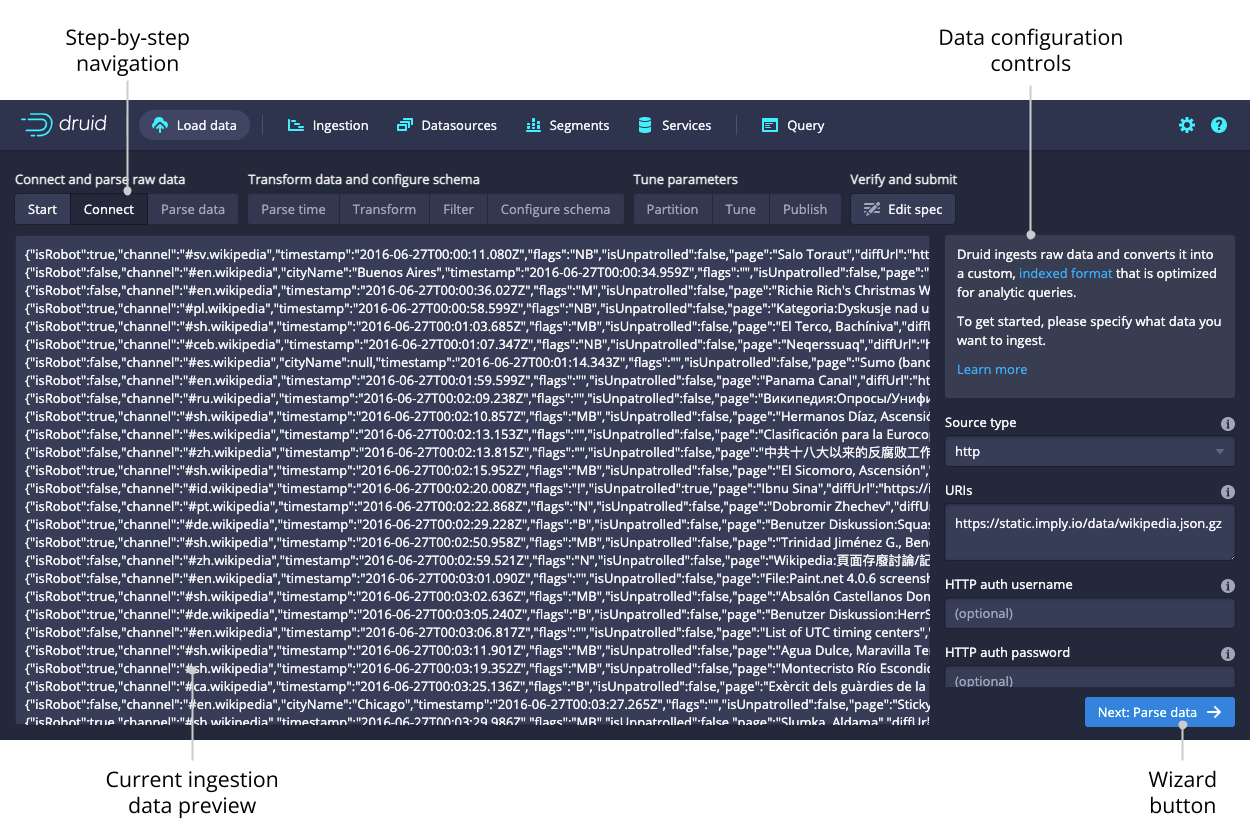
After selecting the location of your data, follow the series of steps displaying incremental previews of the data as it is ingested. After filling in the required details on every step you can navigate to the next step by clicking Next. You can also freely navigate between the steps from the top navigation.
Navigating with the top navigation leaves the underlying spec unmodified while clicking Next attempts to fill in the subsequent steps with appropriate defaults.
Datasources
The Datasources view shows all the datasources currently loaded on the cluster, as well as their sizes and availability. From the Datasources view, you can edit the retention rules, configure automatic compaction, and drop data in a datasource.
A datasource is partitioned into one or more segments organized by time chunks. To display a timeline of segments, toggle the option for Show segment timeline.
Like any view that is powered by a Druid SQL query, you can click View SQL query for table from the ellipsis menu to run the underlying SQL query directly.
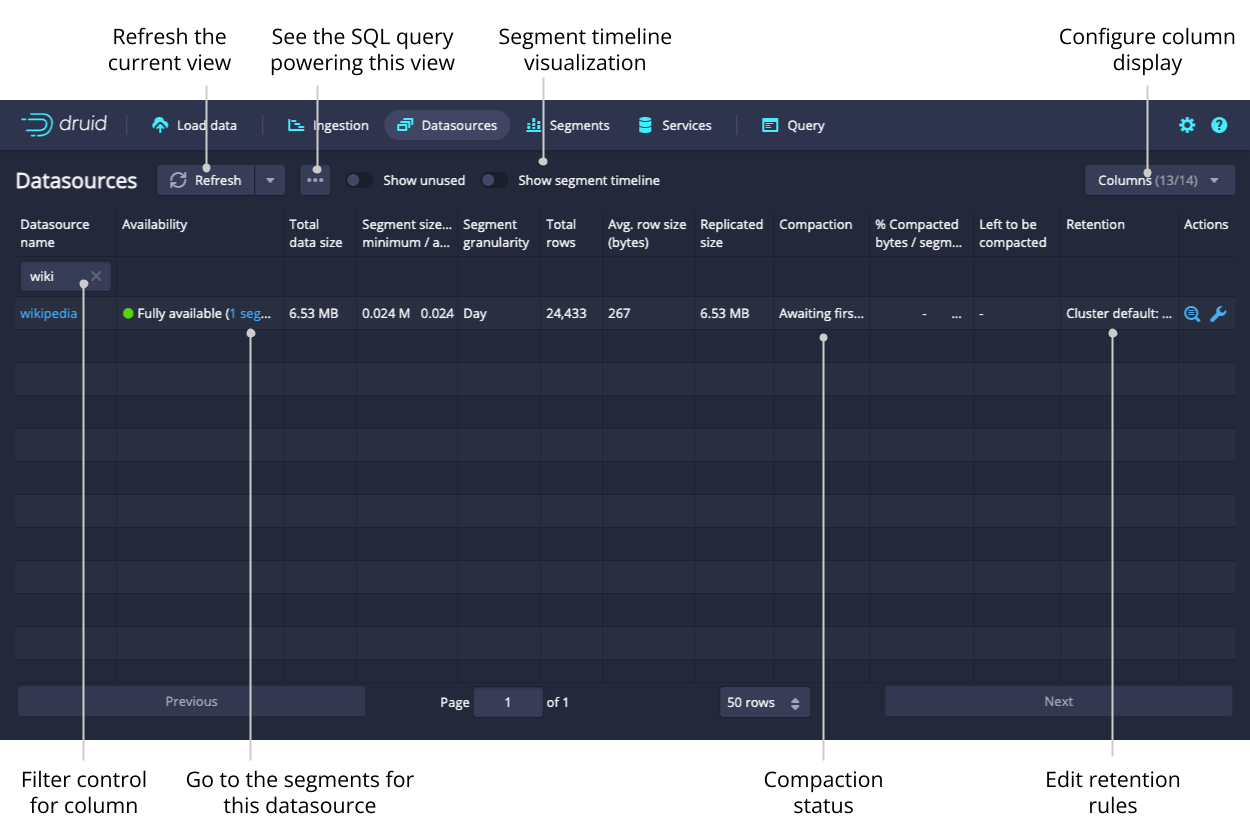
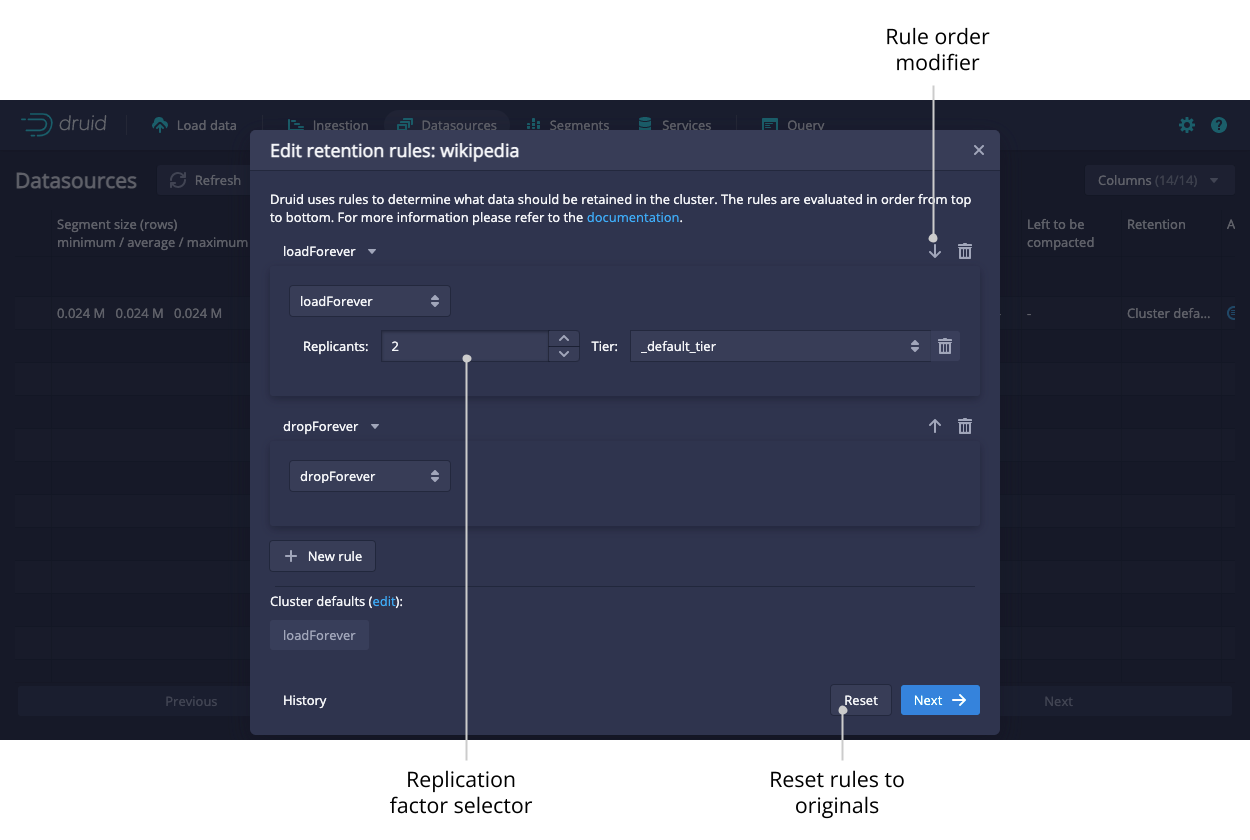
You can view and edit retention rules to determine the general availability of a datasource.
Segments
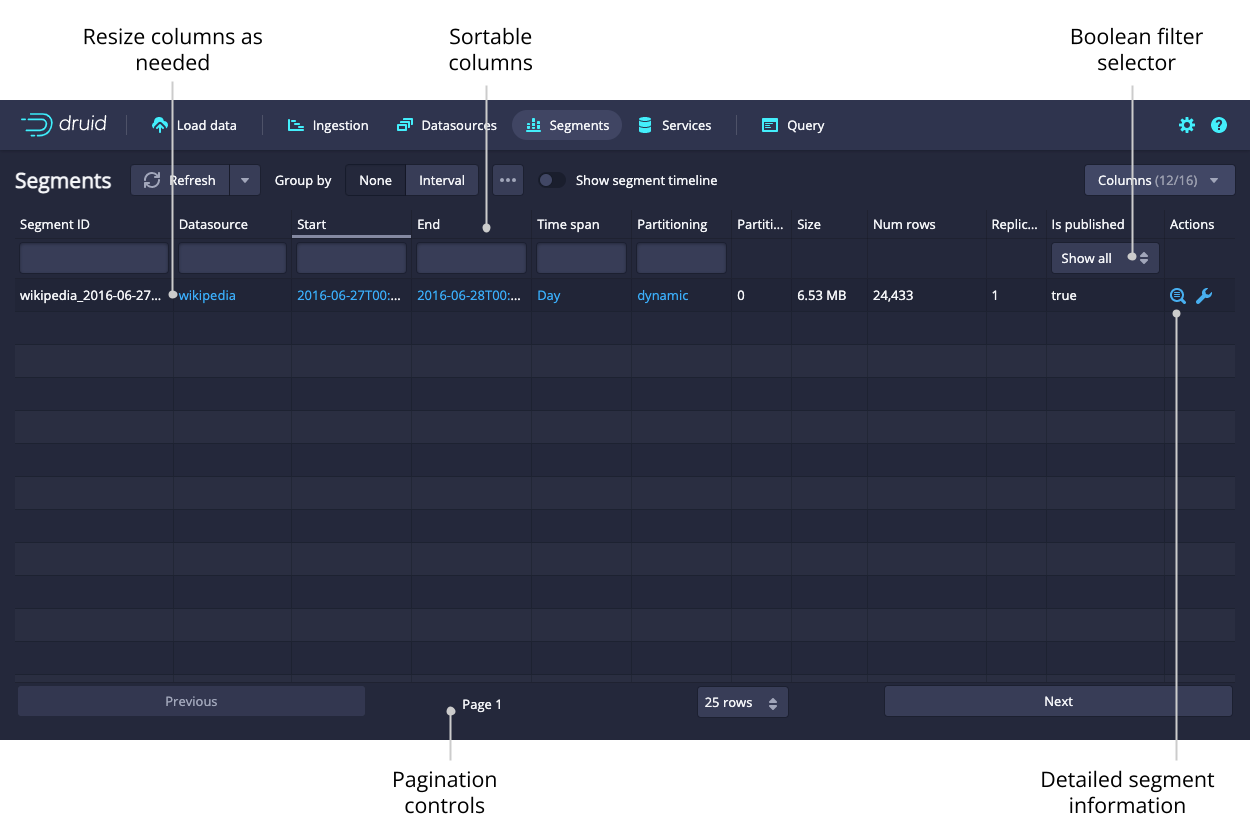
The Segments view shows all the segments in the cluster. Each segment has a detail view that provides more information. The Segment ID is also conveniently broken down into Datasource, Start, End, Version, and Partition columns for ease of filtering and sorting.
Supervisors and tasks
From this view, you can check the status of existing supervisors as well as suspend, resume, and reset them. The supervisor oversees the state of the indexing tasks to coordinate handoffs, manage failures, and ensure that the scalability and replication requirements are maintained.
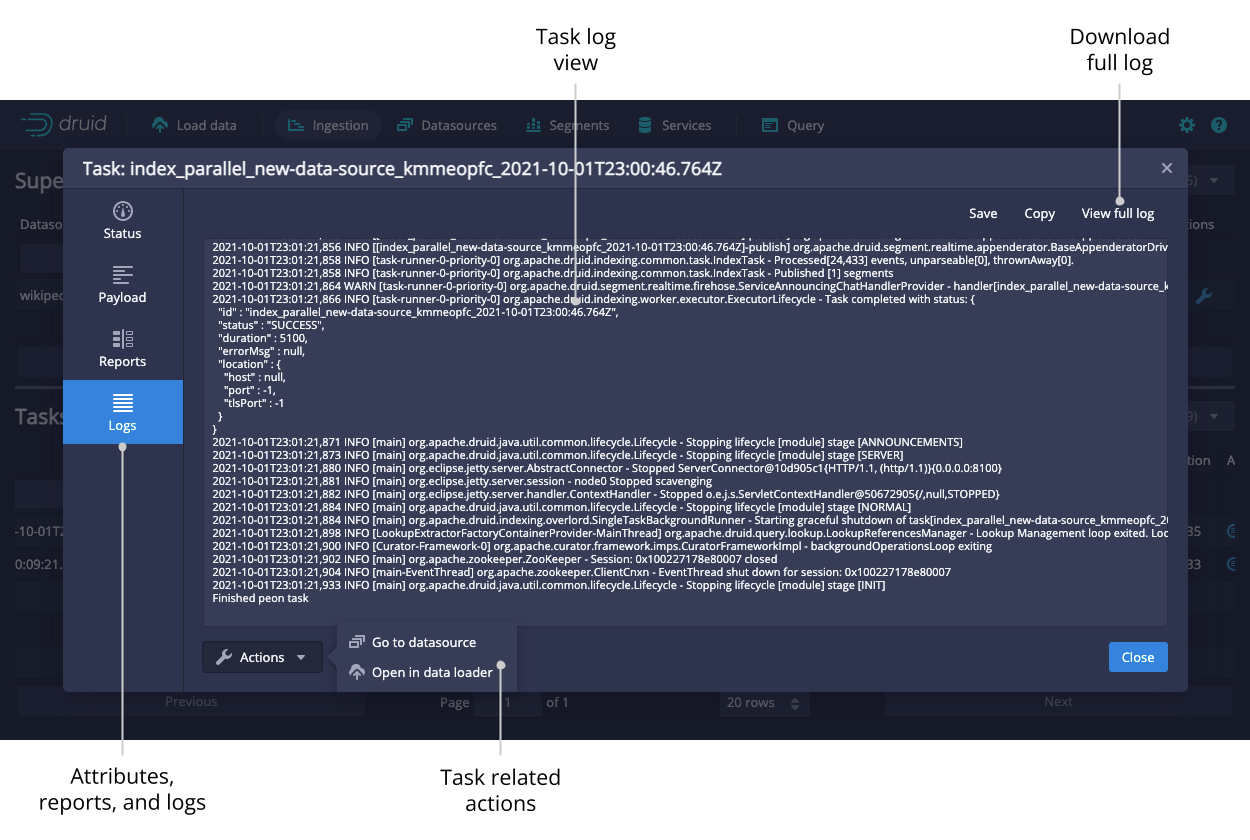
The tasks table allows you to see the currently running and recently completed tasks. To navigate your tasks more easily, you can group them by their Type, Datasource, or Status. Submit a task manually by clicking the ellipsis icon and selecting Submit JSON task.
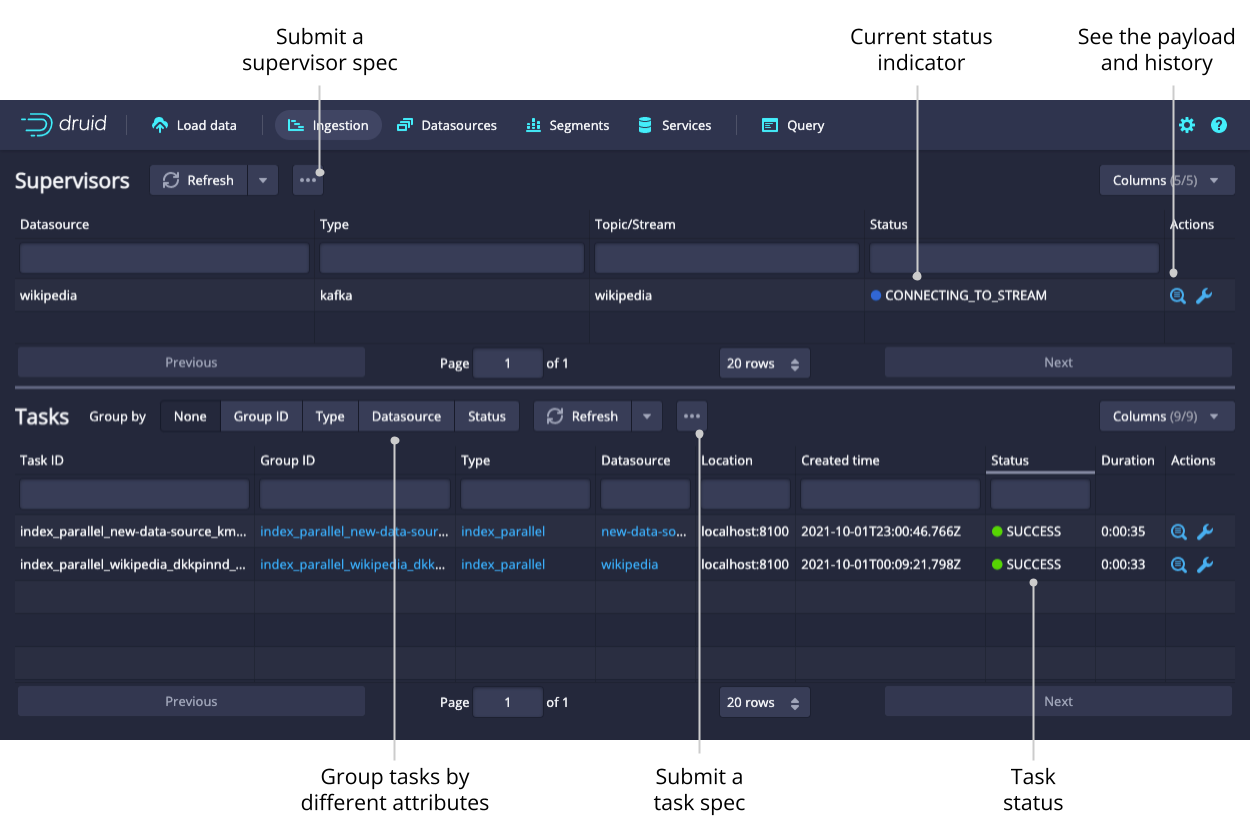
Click on the magnifying glass for any supervisor to see detailed reports of its progress.
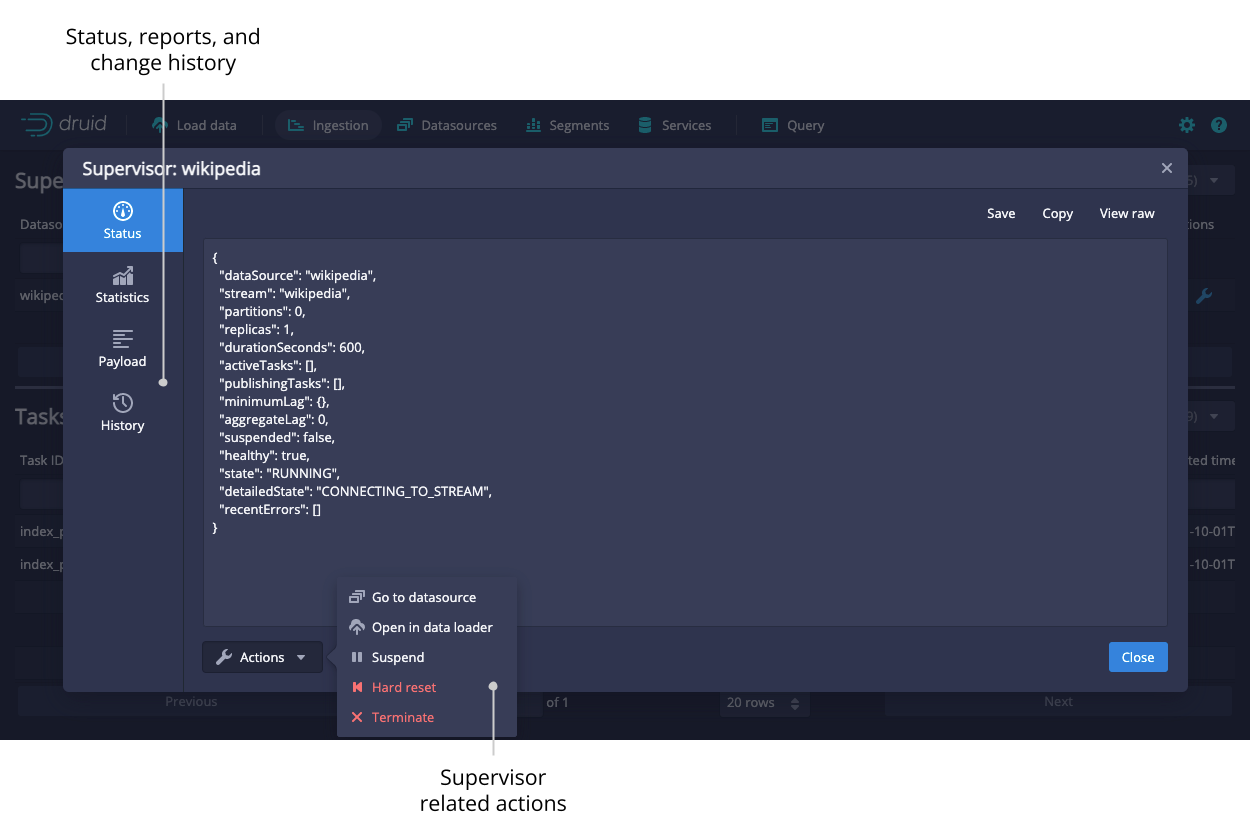
Click on the magnifying glass for any task to see more detail about it.
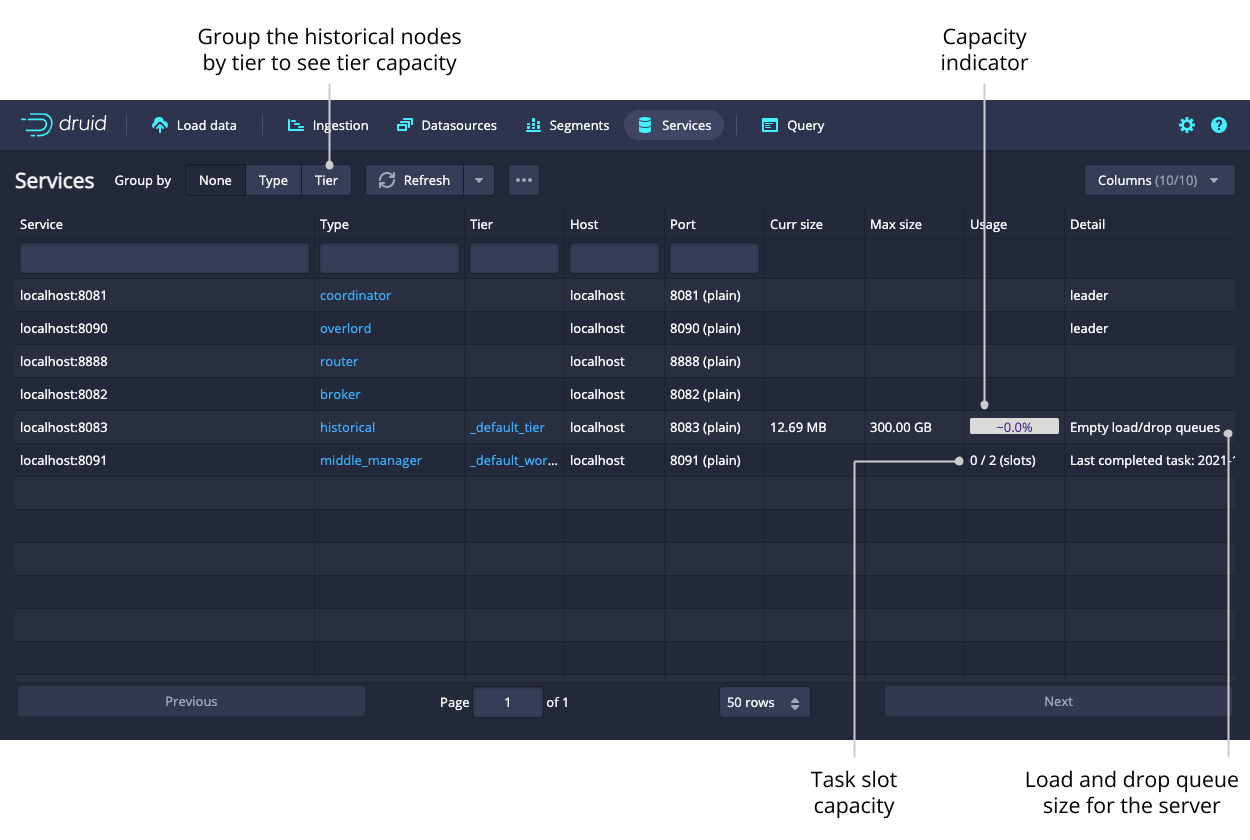
Services
The Services view lets you see the current status of the nodes making up your cluster. You can group the nodes by type or by tier to get meaningful summary statistics.
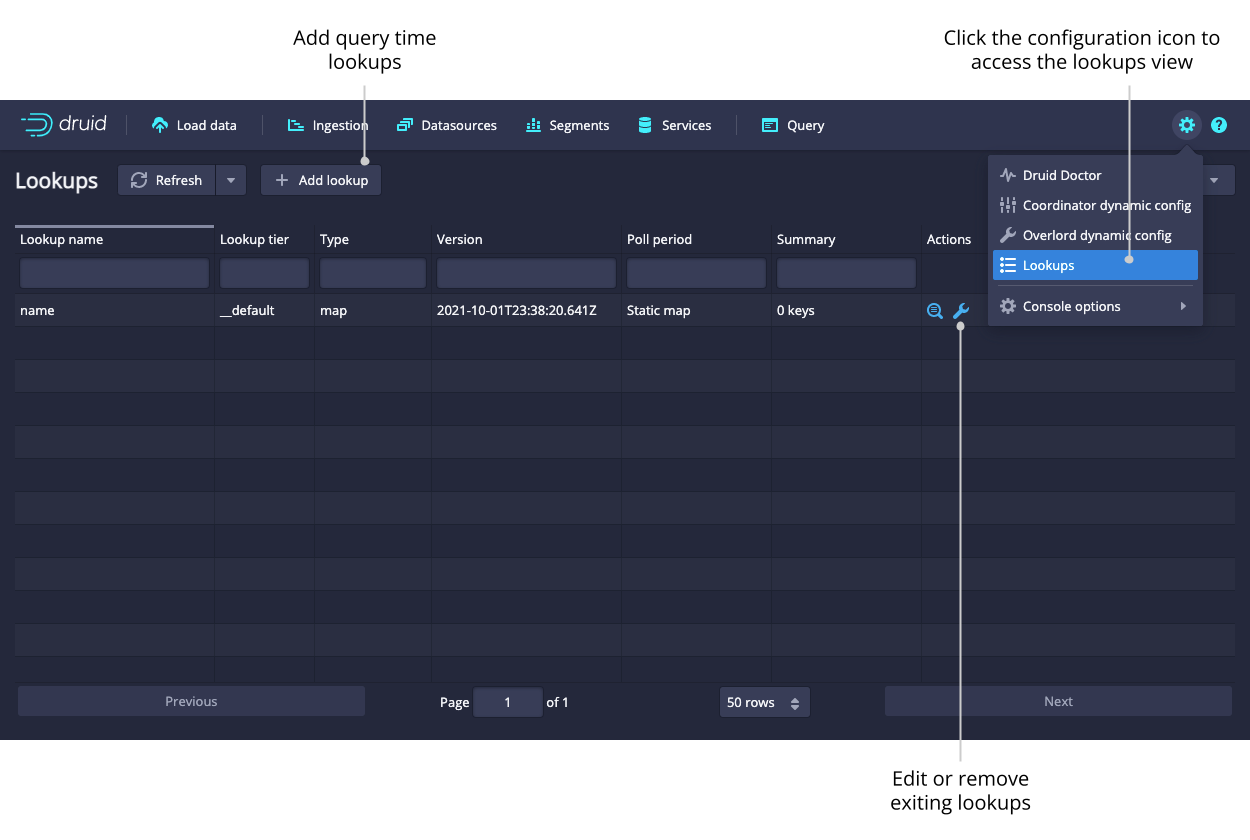
Lookups
Access the Lookups view from the Lookups card in the home view or by clicking on the gear icon in the upper right corner. Here you can create and edit query time lookups.