
HDFS supports writing to off-heap memory managed by the Data Nodes. The Data Nodes will flush in-memory data to disk asynchronously thus removing expensive disk IO and checksum computations from the performance-sensitive IO path, hence we call such writes Lazy Persist writes. HDFS provides best-effort persistence guarantees for Lazy Persist Writes. Rare data loss is possible in the event of a node restart before replicas are persisted to disk. Applications can choose to use Lazy Persist Writes to trade off some durability guarantees in favor of reduced latency.
This feature is available starting with Apache Hadoop 2.6.0 and was developed under Jira HDFS-6581.
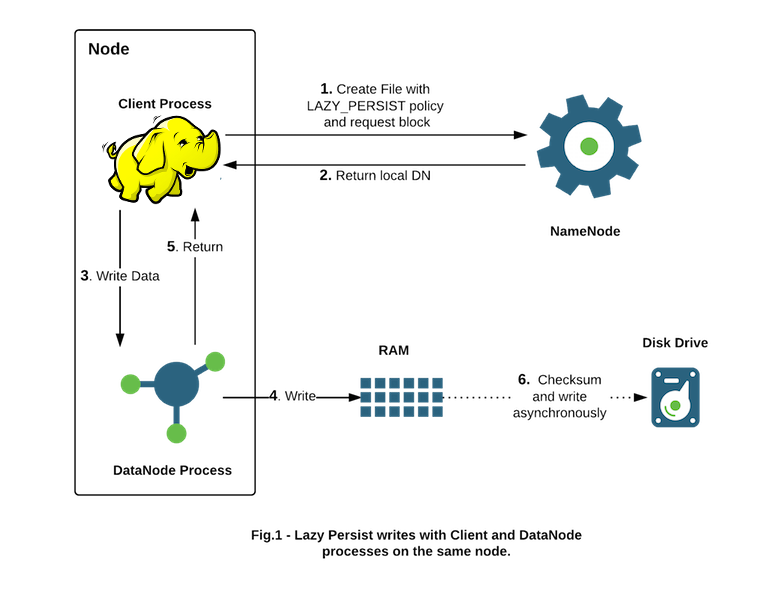
The target use cases are applications that would benefit from writing relatively low amounts of data (from a few GB up to tens of GBs depending on available memory) with low latency. Memory storage is for applications that run within the cluster and collocated with HDFS Data Nodes. We have observed that the latency overhead from network replication negates the benefits of writing to memory.
Applications that use Lazy Persist Writes will continue to work by falling back to DISK storage if memory is insufficient or unconfigured.
This section enumerates the administrative steps required before applications can start using the feature in a cluster.
First decide the amount of memory to be dedicated for replicas stored in memory. Set dfs.datanode.max.locked.memory accordingly in hdfs-site.xml. This is the same setting used by the Centralized Cache Management feature. The Data Node will ensure that the combined memory used by Lazy Persist Writes and Centralized Cache Management does not exceed the amount configured in dfs.datanode.max.locked.memory.
E.g. To reserve 32 GB for in-memory replicas
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>34359738368</value>
</property>
This memory is not allocated by the Data Node on startup.
On Unix-like systems, the “locked-in-memory size” ulimit (ulimit -l) of the Data Node user also needs to be increased to match this parameter (see the related section on OS Limits). When setting this value, please remember that you will need space in memory for other things as well, such as the Data Node and application JVM heaps and the operating system page cache. You will also need memory for YARN containers if there is a YARN Node Manager process running on the same node as the Data Node.
Initialize a RAM disk on each Data Node. The choice of RAM Disk allows better data persistence across Data Node process restarts. The following setup will work on most Linux distributions. Using RAM disks on other platforms is not currently supported.
tmpfs (vs ramfs)Linux supports using two kinds of RAM disks - tmpfs and ramfs. The size of tmpfs is limited by the Linux kernel while ramfs grows to fill all available system memory. There is a downside to tmpfs since its contents can be swapped to disk under memory pressure. However many performance-sensitive deployments run with swapping disabled so we do not expect this to be an issue in practice.
HDFS currently supports using tmpfs partitions. Support for adding ramfs is in progress (See HDFS-8584).
Mount the RAM Disk partition with the Unix mount command. E.g. to mount a 32 GB tmpfs partition under /mnt/dn-tmpfs/
sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/
It is recommended you create an entry in the /etc/fstab so the RAM Disk is recreated automatically on node restarts. Another option is to use a sub-directory under /dev/shm which is a tmpfs mount available by default on most Linux distributions. Ensure that the size of the mount is greater than or equal to your dfs.datanode.max.locked.memory setting else override it in /etc/fstab. Using more than one tmpfs partition per Data Node for Lazy Persist Writes is not recommended.
tmpfs volume with the RAM_DISK Storage TypeTag the tmpfs directory with the RAM_DISK storage type via the dfs.datanode.data.dir configuration setting in hdfs-site.xml. E.g. On a Data Node with three hard disk volumes /grid/0, /grid/1 and /grid/2 and a tmpfs mount /mnt/dn-tmpfs, dfs.datanode.data.dir must be set as follows:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>
This step is crucial. Without the RAM_DISK tag, HDFS will treat the tmpfs volume as non-volatile storage and data will not be saved to persistent storage. You will lose data on node restart.
Ensure that the global setting to turn on Storage Policies is enabled as documented here. This setting is on by default.
Applications indicate that HDFS can use Lazy Persist Writes for a file with the LAZY_PERSIST storage policy. Administrative privileges are not required to set the policy and it can be set in one of three ways.
hdfs storagepolicies command for directoriesSetting the policy on a directory causes it to take effect for all new files in the directory. The hdfs storagepolicies command can be used to set the policy as described in the Storage Policies documentation.
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
setStoragePolicy method for directoriesStarting with Apache Hadoop 2.8.0, an application can programmatically set the Storage Policy with FileSystem.setStoragePolicy. E.g.
fs.setStoragePolicy(path, "LAZY_PERSIST");
LAZY_PERSIST CreateFlag for new filesAn application can pass CreateFlag#LAZY_PERSIST when creating a new file with FileSystem#create API. E.g.
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);