2.7 KiB
2.7 KiB
Solr-Cloud说明
因为Solr-Cloud中的配置文件是交由zookeeper进行管理的, 所以为了方便更新动态词典, 所以也要将动态词典文件上传至zookeeper中,目录与solr的配置文件目录一致。
注意:因为zookeeper中的配置文件大小不能超过1m,当词典列表过多时,需将词典文件切分成多个。
-
将jar包放入每台服务器的Solr服务的
Jetty或Tomcat的webapp/WEB-INF/lib/目录下; -
将
resources目录下的IKAnalyzer.cfg.xml、ext.dic、stopword.dic放入solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下;① IKAnalyzer.cfg.xml (IK默认的配置文件,用于配置自带的扩展词典及停用词典) ② ext.dic (默认的扩展词典) ③ stopword.dic (默认的停词词典)注意:与单机版不同,
ik.conf及dynamicdic.txt请不要放在classes目录下! -
将
resources目录下的ik.conf及dynamicdic.txt放入solr配置文件夹中,与solr的managed-schema文件同目录中;① ik.conf (动态词典配置文件) files (动态词典列表,可以设置多个词典表,用逗号进行分隔,默认动态词典表为dynamicdic.txt) lastupdate (默认值为0,每次对动态词典表修改后请修改该值,必须大于上次的值,不然不会将词典表中新的词语添加到内存中。) ② dynamicdic.txt (默认的动态词典,在此文件配置的词语不需重启服务即可加载进内存中。以#开头的词语视为注释,将不会加载到内存中。) -
配置Solr的
managed-schema,添加ik分词器,示例如下;<!-- ik分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> -
将配置文件上传至
zookeeper中,首次使用请重启服务或reload Collection。 -
测试分词:
- 此时的动态词典文件为空

- 配置文件lastupdate为0

- 测试分词
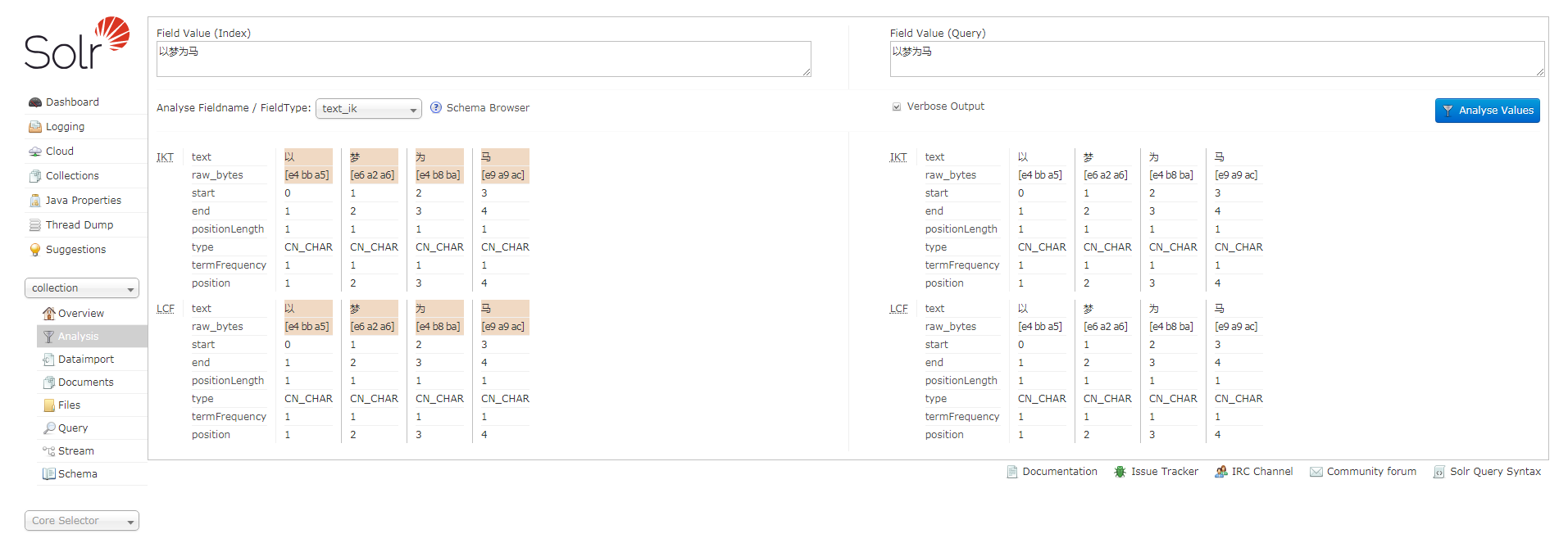
- 此时的动态词典文件为空
-
测试动态词典:
- 增加动态词典词语并上传至
zookeeper
- 修改配置文件并上传至
zookeeper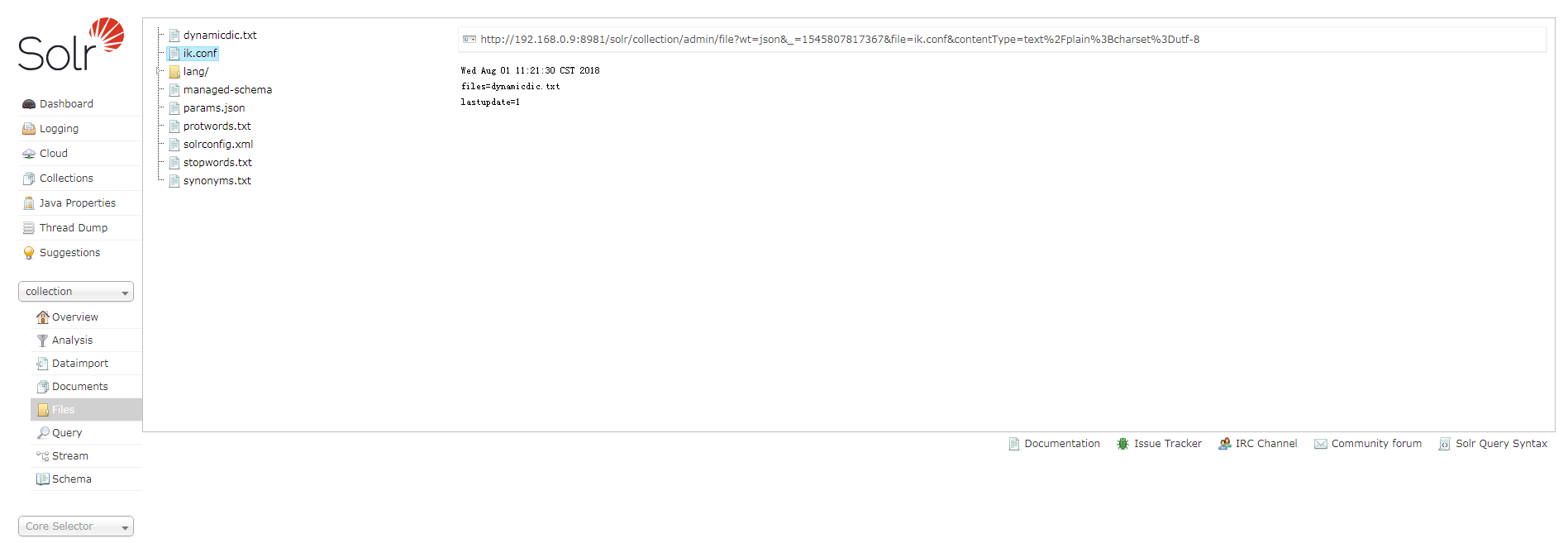
- 测试分词

- 增加动态词典词语并上传至