8.3 KiB
数据保留规则
This tutorial demonstrates how to configure retention rules on a datasource to set the time intervals of data that will be retained or dropped.
For this tutorial, we'll assume you've already downloaded Apache Druid as described in the single-machine quickstart and have it running on your local machine.
It will also be helpful to have finished Tutorial: Loading a file and Tutorial: Querying data.
Load the example data
For this tutorial, we'll be using the Wikipedia edits sample data, with an ingestion task spec that will create a separate segment for each hour in the input data.
The ingestion spec can be found at quickstart/tutorial/retention-index.json. Let's submit that spec, which will create a datasource called retention-tutorial:
bin/post-index-task --file quickstart/tutorial/retention-index.json --url http://localhost:8081
After the ingestion completes, go to http://localhost:8888/unified-console.html#datasources in a browser to access the Druid Console's datasource view.
This view shows the available datasources and a summary of the retention rules for each datasource:

Currently there are no rules set for the retention-tutorial datasource. Note that there are default rules for the cluster: load forever with 2 replicas in _default_tier.
This means that all data will be loaded regardless of timestamp, and each segment will be replicated to two Historical processes in the default tier.
In this tutorial, we will ignore the tiering and redundancy concepts for now.
Let's view the segments for the retention-tutorial datasource by clicking the "24 Segments" link next to "Fully Available".
The segments view (http://localhost:8888/unified-console.html#segments) provides information about what segments a datasource contains. The page shows that there are 24 segments, each one containing data for a specific hour of 2015-09-12:

Set retention rules
Suppose we want to drop data for the first 12 hours of 2015-09-12 and keep data for the later 12 hours of 2015-09-12.
Go to the datasources view and click the blue pencil icon next to Cluster default: loadForever for the retention-tutorial datasource.
A rule configuration window will appear:

Now click the + New rule button twice.
In the upper rule box, select Load and by interval, and then enter 2015-09-12T12:00:00.000Z/2015-09-13T00:00:00.000Z in field next to by interval. Replicas can remain at 2 in the _default_tier.
In the lower rule box, select Drop and forever.
The rules should look like this:

Now click Next. The rule configuration process will ask for a user name and comment, for change logging purposes. You can enter tutorial for both.
Now click Save. You can see the new rules in the datasources view:

Give the cluster a few minutes to apply the rule change, and go to the segments view in the Druid Console. The segments for the first 12 hours of 2015-09-12 are now gone:

The resulting retention rule chain is the following:
-
loadByInterval 2015-09-12T12/2015-09-13 (12 hours)
-
dropForever
-
loadForever (default rule)
The rule chain is evaluated from top to bottom, with the default rule chain always added at the bottom.
The tutorial rule chain we just created loads data if it is within the specified 12 hour interval.
If data is not within the 12 hour interval, the rule chain evaluates dropForever next, which will drop any data.
The dropForever terminates the rule chain, effectively overriding the default loadForever rule, which will never be reached in this rule chain.
Note that in this tutorial we defined a load rule on a specific interval.
If instead you want to retain data based on how old it is (e.g., retain data that ranges from 3 months in the past to the present time), you would define a Period load rule instead.
Further reading
配置数据保留规则
本教程演示如何在数据源上配置保留规则,以设置要保留或删除的数据的时间间隔
本教程我们假设您已经按照单服务器部署中描述下载了Druid,并运行在本地机器上。
加载示例数据
在本教程中,我们将使用Wikipedia编辑的示例数据,其中包含一个摄取任务规范,它将为输入数据每个小时创建一个单独的段
数据摄取规范位于 quickstart/tutorial/retention-index.json, 提交这个规范,将创建一个名称为 retention-tutorial 的数据源
bin/post-index-task --file quickstart/tutorial/retention-index.json --url http://localhost:8081
摄取完成后,在浏览器中转到http://localhost:8888/unified-console.html#datasources以访问Druid控制台的datasource视图
此视图显示可用的数据源以及每个数据源的保留规则摘要

当前没有为 retention-tutorial 数据源设置规则。请注意,集群有默认规则:在 _default_tier 中永久加载2个副本
这意味着无论时间戳如何,所有数据都将加载,并且每个段将复制到两个Historical进程的 _default_tier 中
在本教程中,我们将暂时忽略分层和冗余概念
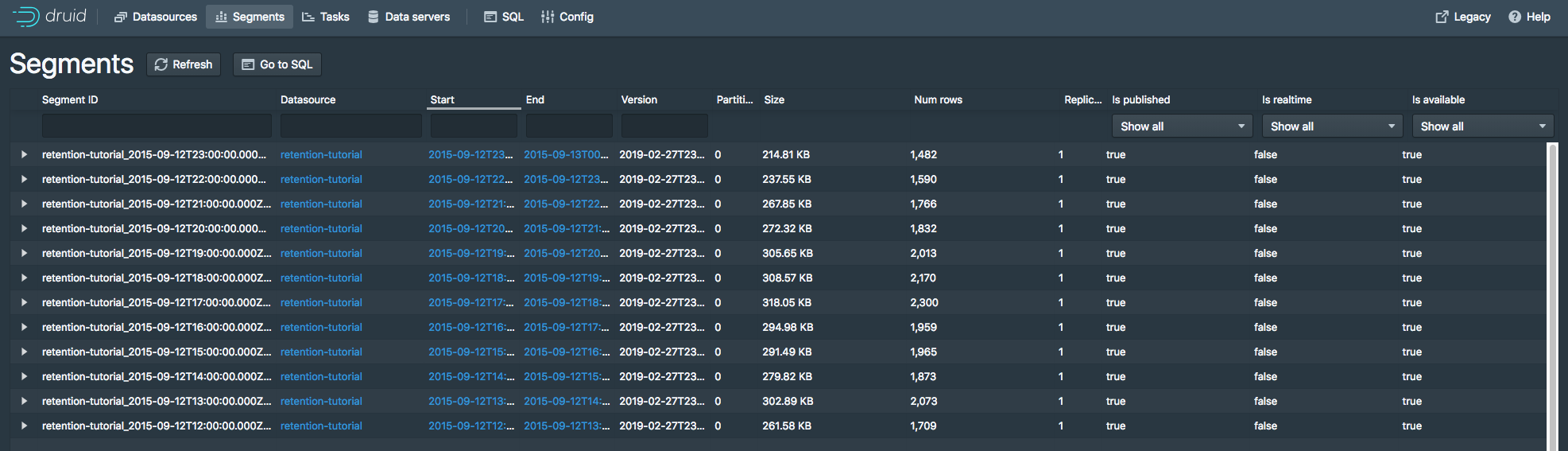
让我们通过单击"Fully Available"旁边的"24 Segments"链接来查看 retention-tutorial 数据源的段
Segment视图 提供了一个数据源包括的segment信息,本页显示有24个段,每一个段包括了2015-09-12特定小时的数据

设置数据保留规则
假设我们想删除2015年9月12日前12小时的数据,保留2015年9月12日后12小时的数据。
进入到Datasources视图,点击 retention-tutorial 数据源的蓝色铅笔的图标 Cluster default: loadForever
一个规则配置窗口出现了:
现在点击 + New rule 按钮两次
在上边的规则框中,选择 Load 和 by Interval 然后输入在 by Interval 旁边的输入框中输入 2015-09-12T12:00:00.000Z/2015-09-13T00:00:00.000Z, 副本可以选择保持2,在 _default_tier 中
在下边的规则框中,选择 Drop 和 forever
规则看上去是这样的:
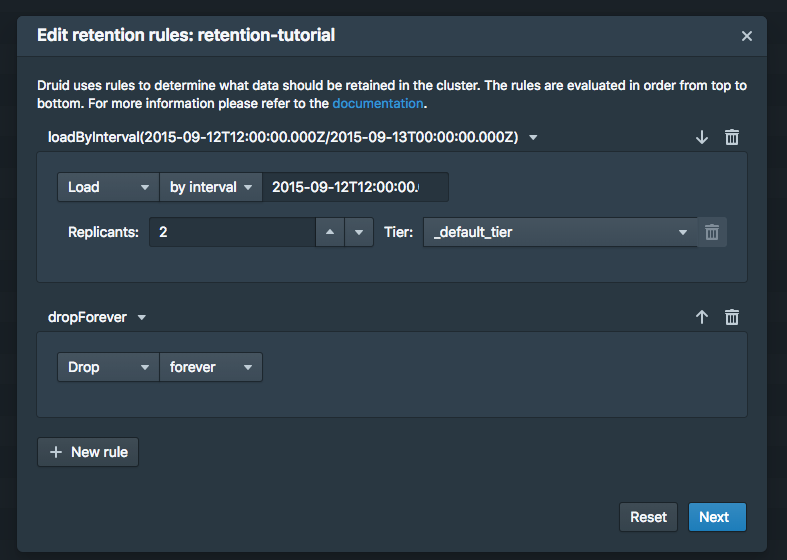
现在点击 Next, 规则配置过程将要求提供用户名和注释,以便进行更改日志记录。您可以同时输入教程。
现在点击 Save, 可以在Datasources视图中看到新的规则

给集群几分钟时间应用规则更改,然后转到Druid控制台中的segments视图。2015年9月12日前12小时的段文件现已消失
生成的保留规则链如下:
- loadByInterval 2015-09-12T12/2015-09-13 (12 hours)
- dropForever
- loadForever (默认规则)
规则链是自上而下计算的,默认规则链始终添加在底部
我们刚刚创建的教程规则链在指定的12小时间隔内加载数据
如果数据不在12小时的间隔内,则规则链下一步将计算 dropForever,这将删除任何数据
dropForever 终止了规则链,有效地覆盖了默认的 loadForever 规则,在这个规则链中永远不会到达该规则
注意,在本教程中,我们定义了一个特定间隔的加载规则
相反,如果希望根据数据的生命周期保留数据(例如,保留从过去3个月到现在3个月的数据),则应定义一个周期性加载规则(Period Load Rule)。